Abstract
Underwater acoustic target recognition (UATR) is usually difficult due to the complex and multipath underwater environment.由于水下环境的复杂性和多径性,水声目标识别一直是一个难点。
Currently, deep-learning(DL)-based UATR methods have proved their effectiveness and have outperformed the traditional methods by using powerful convolution neural networks (CNNs) to extract discriminative features on acoustic spectrograms.目前,基于深度学习(DL)的UATR方法已经证明了它们的有效性,并且通过使用强大的卷积神经网络(CNN)来提取声谱图上的区分特征,其性能优于传统方法。
However, CNNs always fail to capture the global information implicated in the spectrogram due to the use of a small kernel and thus encounter the performance bottleneck.然而,由于使用小的内核,CNN总是无法捕获频谱图中包含的全局信息,从而遇到性能瓶颈。
To this end, we propose the UATR-transformer based on a convolution-free architecture, referred to as the transformer, which can perceive both the global and local information from acoustic spectrograms, and thus improve the accuracy.为此,我们提出了基于无卷积架构的UATR-transformer,称为Transformer,它可以从声谱图中感知全局和局部信息,从而提高准确性。
Experiments on two real-world data demonstrate that our proposed model has achieved comparative results to the state of art CNNs and thus can be applied to certain cases in UATR.在两个真实数据上的实验表明,我们提出的模型与最先进的CNN取得了比较结果,因此可以应用于UATR中的某些情况。
Index Terms—Acoustic spectrogram, convolution-free, transformer, underwater acoustic target recognition (UATR).索引词——声谱图,无卷积,Transformer,水声目标识别。
1.Introduction
Underwater acoustic target recognition (UATR) is one of the major functions in a sonar system.水声目标识别是声纳系统的主要功能之一。
It has attracted much attention due to its wide applications in the detection and classification of underwater targets, measurement of the impact of ship radiated noise, and the design of abandoned ships [1].由于其在水下目标的检测和分类、舰船辐射噪声影响的测量以及废弃舰船的设计等方面的广泛应用,引起了人们的广泛关注[1]。
However, because of the complicated ship noise radiation itself and various experimental interference, it is challenged in the case of the complex marine environment and the fact that underwater acoustic signals can be easily affected by various physical variables.然而,由于船舶噪声辐射本身的复杂性和各种实验干扰,在复杂的海洋环境和水声信号易受各种物理量影响的情况下,对船舶噪声辐射的研究面临着挑战。
Currently, the issue of UATR can be commonly solved by time–frequency (T–F) analysis, for example, the low frequency analysis and recording (LOFAR) [2], detection of envelope modulation on noise (DEMON) analysis [3], and the Mel-frequency cepstral coefficient (MFCC) [4] inspired by human auditory perception.目前,UATR的问题通常可以通过时频(T-F)分析来解决,例如,低频分析和记录(LOFAR)[2],噪声包络调制检测(DEMON)分析[3]以及受人类听觉感知启发的Mel频率倒谱系数(MFCC)[4]。
On the other hand, to automatically classify the underwater acoustic signals with efficiency, deep-learning (DL)-based UATR has become a major trend of development.另一方面,为了有效地自动分类水声信号,基于深度学习(DL)的UATR已成为发展的主要趋势。
One of the major challenges is that the underwater acoustic spectrogram, unlike common images or audio spectrograms, lacks sufficient texture features due to multivariate influences in the marine environment such as ambient noise interference, multipath interference, and transmission loss.其中一个主要的挑战是,水下声谱图,不像普通的图像或音频声谱图,缺乏足够的纹理特征,由于在海洋环境中的多变量影响,如环境噪声干扰,多径干扰,和传输损耗。
As such, it merely provides a certain correlation between the time and frequency axes, which implies that a powerful DL model with strong robustness is needed.因此,它仅提供时间轴和频率轴之间的某种相关性,这意味着需要具有强鲁棒性的强大DL模型。
Owing to the convolution neural networks (CNNs) and their variations, DL-based UATR has made certain results.由于卷积神经网络(CNN)及其变体,基于DL的UATR取得了一定的成果。
For example, Hu et al. [5] studied a novel DL model by introducing depthwise (DW) separable and time-dilated convolution for passive UATR and has proved its effectiveness compared with traditional UATR methods.例如,Hu等人[5]通过引入用于被动UATR的dependency(DW)可分离和时间扩张卷积来研究一种新的DL模型,并与传统UATR方法相比证明了其有效性。
Zhang et al. [6] combined the recurrent neural network (RNN) and CNN to design a modulation recognition model for underwater acoustic signals.Zhang等人[6]将递归神经网络(RNN)和CNN相结合,设计了一种水声信号的调制识别模型。
Cao et al. [7] studied an end-to-end clas53 sification model that combines the CNN with second-order pooling to capture the temporal correlations from the T–F spectrogram of the radiated acoustic signals.Cao等人[7]研究了一种端到端分类模型,该模型将CNN与二阶池化相结合,以从辐射声信号的T-F频谱图中捕获时间相关性。
In another work [1], a hybrid CNN and RNN model is also proposed to extract multidimensional T–F features from spectrograms, which can effectively achieve robust feature extraction and UATR.在另一项工作[1]中,还提出了一种混合CNN和RNN模型来从谱图中提取多维T-F特征,该模型可以有效地实现鲁棒的特征提取和UATR。
In all, they research leverage convolution mechanism to continuously enrich the manual or automatic features by sliding a kernel window on acoustic data and expect to improve the recognition performance by various designs of CNN structure.总之,他们研究利用卷积机制,通过在声学数据上滑动内核窗口来不断丰富手动或自动特征,并期望通过CNN结构的各种设计来提高识别性能。
Nevertheless, for CNN-based UATR methods, only parts of the acoustic spectrogram that are close enough to fit within the kernel size can interact with each other in a convolution layer.然而,对于基于CNN的UATR方法,只有足够接近以适合核大小的声谱图的部分可以在卷积层中相互作用。
While for the items that are further apart, the global information between time and frequency segments is rarely considered.而对于距离较远的项目,很少考虑时间段和频率段之间的全局信息。
In this case, the existing CNN-based UATR methods encounter performance bottlenecks and therefore may not achieve satisfactory results.在这种情况下,现有的基于CNN的UATR方法遇到性能瓶颈,因此可能无法获得令人满意的结果。
To this end, we propose the UATR-transformer model for UATR based on transformer [8], which is known as a convolution-free architecture.为此,我们基于transformer [8]提出了UATR的UATR-transformer模型,这被称为无卷积架构。
Currently, transformer seems to achieve state-of-the-art results and has shown its great potential in various scientific fields.目前,Transformer已经取得了很好的研究成果,并在各个科学领域显示出了巨大的潜力。
Particularly, its great success in audio processing further enhances the feasibility for underwater acoustic research, such as the audio spectrogram transformer (AST) [9] inspired by data efficient image transformer (DeiT) [10], and the hierarchical token-semantic audio transformer (HTS-AT) [11] inspired by Swin transformer [12].特别是,其在音频处理方面的巨大成功进一步增强了水下声学研究的可行性,例如受数据高效图像Transformer(DeiT)[10]启发的音频频谱图Transformer(AST)[9],以及受Swin Transformer [12]启发的分层令牌语义音频Transformer(HTS-AT)[11]。
Compared with the CNNs for UATR, the transformer architecture is believed to perceive both global and local information from the acoustic spectrogram.与用于UATR的CNN相比,Transformer架构被认为从声谱图中感知全局和局部信息。
And the experimental results based on two real-world data show that our proposed model exceeds CNN architecture with excellent generalization, which has proved its effectiveness in introducing transformer into UATR and thus can be applied to certain cases.基于两个真实数据的实验结果表明,该模型优于CNN结构,具有良好的泛化能力,证明了该模型在UATR中引入Transformer的有效性,并可应用于特定情况。
To sum up, this letter mainly includes the following contributions概括起来,这封信主要包括以下几点贡献
- First of all, we take advantage of the transformer as a backbone instead of the CNN. To the best of our knowledge, researchers have introduced the attention mechanism knowledge, researchers have introduced the attention mechanism into UATR to analyze the inner workings and behavior of DL models [13], however, this is the first time that the ent knowledge, researchers have introduced the attention mechanism into UATR to analyze the inner workings and behavior of DL models [13], however, this is the first time that the entire transformer owing to multihead self-attention (MHSA) [8] module has been introduced into the field of UATR. which is certainly meaningful since the powerful transformer is in the stage of rapid development and is considered to be a strong competitor to the CNN and RNN due to its strong representation ability.
首先,我们利用Transformer作为主干,而不是CNN。据我们所知,研究人员已经引入了注意力机制知识,研究人员将注意力机制引入UATR来分析DL模型的内部工作和行为[13],然而,这是第一次将注意力机制引入UATR来分析DL模型的内部工作和行为[13],然而,这是第一次将由于多头自注意(MHSA)[8]模块而产生的整个Transformer引入UATR领域。这当然是有意义的,因为强大的Transformer正处于快速发展阶段,并且由于其强大的表示能力而被认为是CNN和RNN的强有力竞争者。 - Moreover, we develop a novel progressive token embedding strategy for underwater acoustic spectrograms. As such, we expect that our model can extract high-level features from acoustic spectrogram as it not only takes global information into account via MHSA, but also implements hierarchical local aggregation (partial convolution) within each T–F token. Besides, we adopt the T–F Tokens Pooling classifier instead of the [CLS] token used in traditional transformers, which enables our model to capture the relationship between all aggregated T–F tokens.
此外,我们开发了一种新的渐进式token嵌入策略的水声频谱。因此,我们期望我们的模型可以从声谱图中提取高级特征,因为它不仅通过MHSA考虑全局信息,而且还在每个T-F token内实现分层局部聚合(部分卷积)。此外,我们采用T-F tokens池分类器代替传统transformer中使用的[CLS] token,这使得我们的模型能够捕获所有聚合T-F tokens之间的关系。
2.PROPOSED METHOD
建议的方法
For UATR, this research studies an efficient acoustic Mel-spectrogram transformer with T–F tokens aggregating and the tokens pooling classifier, referred to as the UATR-transformer, to recognize two real-world underwater acoustic signal data.针对UATR,本文研究了一种有效的基于T-F tokens聚集的声学Mel-谱图Transformer和tokens池分类器,简称UATR-Transformer,并对两组真实的水声信号数据进行了识别。
Specifically, our work is fundamentally inspired by the Tokens-To-Token Vision Transformer (T2T-ViT) introduced for image classification [14] and is leveraged with a 120 novel classification strategy.具体来说,我们的工作从根本上受到了为图像分类引入的Tokens-To-Token Vision Transformer(T2T-ViT)的启发[14],并利用了120种新颖的分类策略。
The overall workflow can be seen in Fig. 1.总体工作流程如图1所示。![Figure 1 Illustration of the overall workflow (inspired by vision transformer [8]). Qh, Kh,and Vh, respectively, means the query matrix, the key matrix, and the value matrix.](https://cdn.jsdelivr.net/gh/YangQingHui66/CDN/blog-img/at/1.png)
整体工作流程的图示(灵感来自Vision Transformer [8])。Qh、Kh和Vh分别表示查询矩阵、键矩阵和值矩阵。
The Mel-fbank feature consisting of half-overlapped triangular filters on center frequency fmel can be written as follows:由中心频率fmel上的半重叠三角形滤波器组成的Mel-fbank特征可以写为: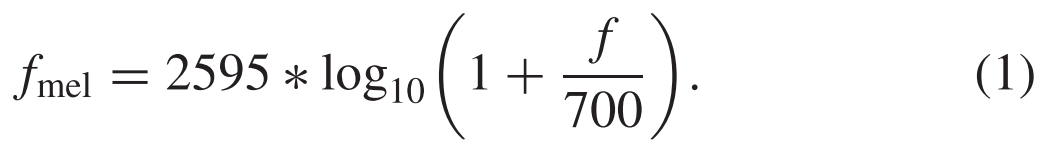
As the frequency f (Hz) increases, the bandwidth of the filter gradually increases, which makes it more conducive to extracting low-frequency features of underwater target signals.随着频率f(Hz)的增大,滤波器的带宽逐渐增大,更有利于提取水下目标信号的低频特征。
To this end, the Mel-fbank is chosen as the input representation for the UATR transformer.为此,选择Mel-fbank作为UATR Transformer的输入表示。
As shown on the left of Fig. 1, the input acoustic waveform of t seconds is first converted into a sequence of t × f log Mel-fbank features computed every 10 ms with a 25-ms Hamming window, as the input representation for our proposed model, where f means the number of filter banks.如图1左侧所示,t秒的输入声波波形首先被转换为一系列t × f log Mel-fbank特征,每10 ms计算一次,汉明窗口为25 ms,作为我们提出的模型的输入表示,其中f表示滤波器组的数量。
As a similar work in audio processing, tokenization in AST is to divide the spectrogram into 16 × 16 patches with an overlap of 6 in both time and frequency dimensions, which will be flattened into high-dimensional embedding vectors using a linear projection layer.与音频处理中的类似工作一样,AST中的标记化是将频谱图划分为16 × 16块,在时间和频率维度上都有6个重叠,这些块将使用线性投影层平坦化为高维嵌入向量。
As such, the model cannot well capture the partial relationship between neighboring tokens by directly splitting spectrogram to tokens with fixed lengths.因此,该模型不能很好地捕捉相邻标记之间的部分关系,通过直接分裂频谱图与固定长度的标记。
We are then motivated to employ a novel tokenization approach to circumvent the limit mentioned above and to apply it to underwater acoustic spectrograms.然后,我们有动机采用一种新的标记化方法来规避上述限制,并将其应用于水下声谱图。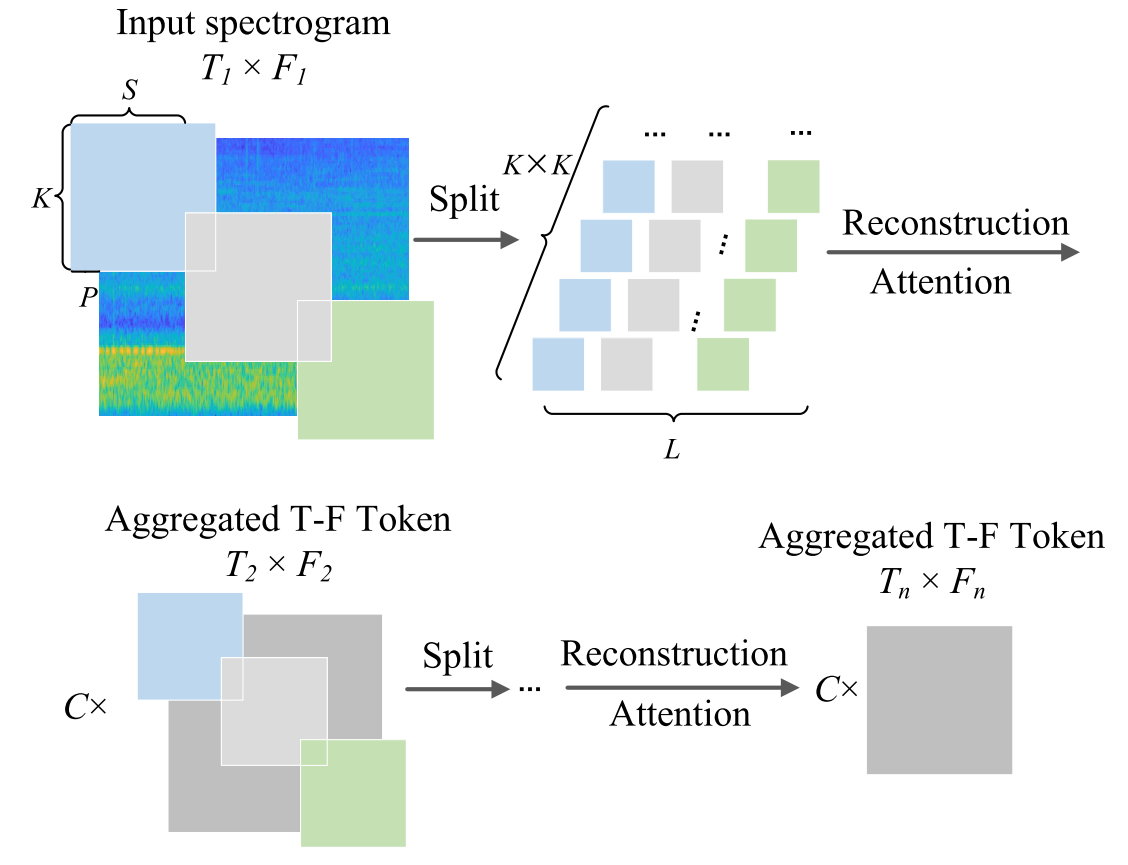
T–F tokens聚合模块的总体结构。
As illustrated in Fig. 2, we use a progressive tokenization module that integrates neighboring T–F tokens which are split from spectrogram into one smaller token on both time and frequency dimensions, referred to as the T–F tokens aggregating block, which encodes the local structure for surrounding T–F tokens while concurrently reducing the token length and therefore improve the efficiency.如图2所示,我们使用渐进式tokens模块,该模块将从频谱图分裂的相邻T-F tokens在时间和频率维度上集成为一个较小的token,称为T-F tokens聚合块,其对周围T-F tokens的局部结构进行编码,同时减少tokens长度,从而提高效率。
To be more explicit, the T–F tokens aggregating module consists of three main steps: T–F Split, token attention calculation, and T–F Reconstruction.更明确地说,T-F tokens聚合模块包括三个主要步骤:T-F分割,标记注意力计算和T-F重建。
Specifically, the T1 ×F1 input spectrogram I0 is first split into an overlapping sequence of CK^2 × L pixels by sliding a kernel window with a size of [K, S, P],of which C is the number of the channels具体地,首先通过滑动大小为[K,S,P]的核窗口将T1 ×F1输入谱图I0分割成CK ^2 × L像素的重叠序列,其中C是通道的数目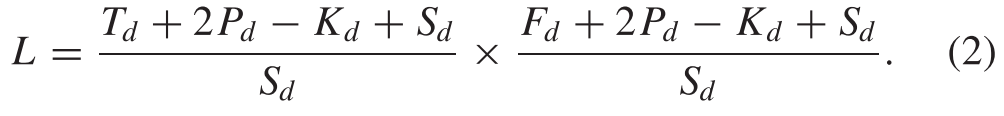
At the dth iteration, Td and Fd are the time and frequency axes, Kd, Sd,and Pd are the kernel size, the stride, and the padding of the kernel window, respectively.在第d次迭代时,Td和Fd是时间轴和频率轴,Kd、Sd和Pd分别是内核窗口的内核大小、步幅和填充。
To capture the spatial structure, the relation between each token is measured by attention calculation in an MHSA layer with a number of heads H = 1 (will be discussed later), in this case, information between surrounding tokens is aggregated together, and then the output is flattened into the C × T2 × F2 spectrogram as the reconstruction process.为了捕捉空间结构,在具有头部数量H = 1的MHSA层中通过注意力计算来测量每个标记之间的关系(将在后面讨论),在这种情况下,周围标记之间的信息被聚集在一起,然后输出被平坦化为C × T2 × F2谱图作为重建过程。
These steps are repeated multiple times to get the final T–F tokens of proper size.这些步骤重复多次,以获得适当大小的最终T-F tokens。
Particularly, this module can be defined as the operation of reducing the number of T–F tokens on a spatial level, and simultaneously establishing a strong correlation between them.特别地,该模块可以被定义为在空间水平上减少T-F tokens的数量,并且同时在它们之间建立强相关性的操作。
By using a linear projection layer, finally, each aggregated T–F token is mapped into a 192-D feature vector.通过使用线性投影层,最后,每个聚合的T-F令牌被映射到192-D特征向量。
In our experiment, we use the setup of kernel size (K, S, P) = (7, 4, 2), (3, 2, 1) and (3, 2, 1), which results in T/16×F/16 tokens with an embedding dimension of 192 since the stride is 4, 2 and 2.在我们的实验中,我们使用内核大小(K,S,P)=(7,4,2),(3,2,1)和(3,2,1)的设置,这导致T/16×F/16令牌的嵌入维数为192,因为步幅为4,2和2。
Importantly, in order to capture the spatial structure of the spectrogram, a learnable positional embedding is attached to each T–F token, which is initialed as follows:重要的是,为了捕获频谱图的空间结构,每个T-F标记都附加了一个可学习的位置嵌入,初始化如下: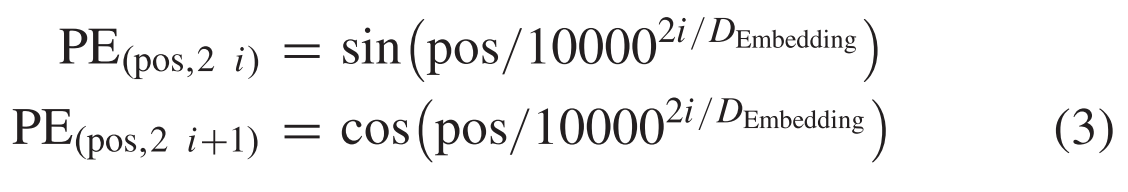
where pos means the order of the T–F token, i ∈ [1, DEmbedding/2],and DEmbedding is the embedding dimension.其中pos表示T-F令牌的阶数,i ∈ [1,DEmbedding/2],DEmbedding是嵌入维数。
As a result, the original Mel-spectrogram is encoded by a series of T–F tokens with order information as input fed into N transformer encoders.结果,原始Mel频谱图由一系列T-F令牌编码,其中顺序信息作为输入馈送到N个Transformer编码器中。
In particular, a transformer is made up of several encoder and decoder blocks.特别地,Transformer由若干编码器和解码器块组成。
Since our model is designed for UATR which is considered a classification task, we only exploit the encoder blocks, intuitively.由于我们的模型是为UATR设计的,UATR被认为是一个分类任务,因此我们只直观地利用编码器块。
Our model exploits N transformer encoders with the MHSA mechanism, which calculates the attention weight between each T–F token.我们的模型利用N个Transformer编码器和MHSA机制,计算每个T-F令牌之间的注意力权重。
Specifically, in the first transformer encoder, the input feature after tokenization can be denoted as X0 of size P × DEmbedding and P = T/16 × F/16.具体地,在第一Transformer编码器中,标记化之后的输入特征可以表示为大小为P × DEmbedding并且P = T/16 × F/16的X 0。
Then the MHSA layer in N transformer encoder projects Xn−1 with Qh, Kh,and Vh, referred to as the query matrix, the key matrix, and the value matrix, respectively,然后,N Transformer编码器中的MHSA层用Qh、Kh和Vh投影Xn-1,Qh、Kh和Vh分别被称为查询矩阵、键矩阵和值矩阵,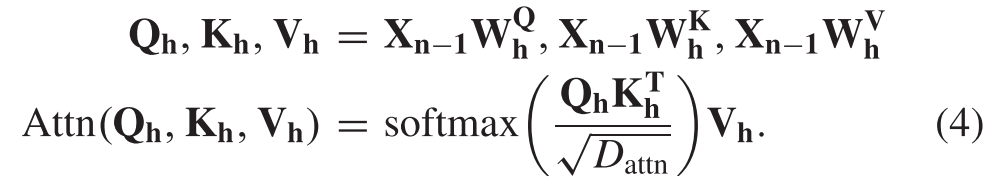
In which, W^Q h , W^K h ,and W^V h are learnable projection matrixes, H is the number of heads, h ∈[1, H] represents which head to be calculated, dimension of the attention weight Dattn = DEmbedding/H.其中,W^Q h、W^K h和W^V h是可学习的投影矩阵,H是头部的数量,h ∈[1,H]表示要计算哪个头部,注意力权重的维数Dattn = DEmbedding/H。
After MHSA and multilayer perceptron (MLP) in N transformer encoders, we have an output of size P × DEmbedding with both local and global information between time and frequency axes.在N个Transformer编码器中的MHSA和多层感知器(MLP)之后,我们具有大小为P × DEmbedding的输出,其在时间和频率轴之间具有局部和全局信息。
To classify labels in most transformer models, an extra token named [CLS] token that gathers classification information is appended at the beginning of the sequence and is directly fed into an MLP head.为了对大多数Transformer模型中的标签进行分类,在序列的开头附加一个名为[CLS]的标记,用于收集分类信息,并将其直接送入MLP头。
However, in the area of acoustic processing, models may not well capture the start and the end of sample data when the embedding dimension is large.然而,在声学处理领域,当嵌入维数较大时,模型可能无法很好地捕获样本数据的开始和结束。
To this end, we use the tokens pooling layer to predict the label, which is expected to improve the performance of UATR because it examines the final prediction by grouping all T–F tokens.为此,我们使用tokens池层来预测标签,这有望提高UATR的性能,因为它通过对所有T-F令牌进行分组来检查最终预测。
Specifically, in the final layer output, each T–F token contains information about its corresponding time frames and frequency bins, and our model takes these latent tokens after attention calculation as an activation map, which is expected to jointly consider the relationship between the frequency bins and the time frames contained in each token so that we can integrate the meanings of each T–F token rather than using extra tokens.具体来说,在最终的层输出中,每个T-F标记包含关于其对应的时间帧和频率箱的信息,并且我们的模型将注意力计算后的这些潜在标记作为激活图,期望共同考虑每个标记中包含的频率箱和时间帧之间的关系,以便我们可以整合每个T-F标记的含义,而不是使用额外的标记。
In particular, the tokens pooling classifier after the final encoder has a kernel size (3, F/16), stride (1, 1) with a padding size (1, 0) to integrate all frequency bins and map the 192-D features into the number of classes C.具体地,在最终编码器之后的令牌池化分类器具有核大小(3,F/16)、步幅(1,1)和填充大小(1,0),以整合所有频率仓并将192-D特征映射到多个类别C中。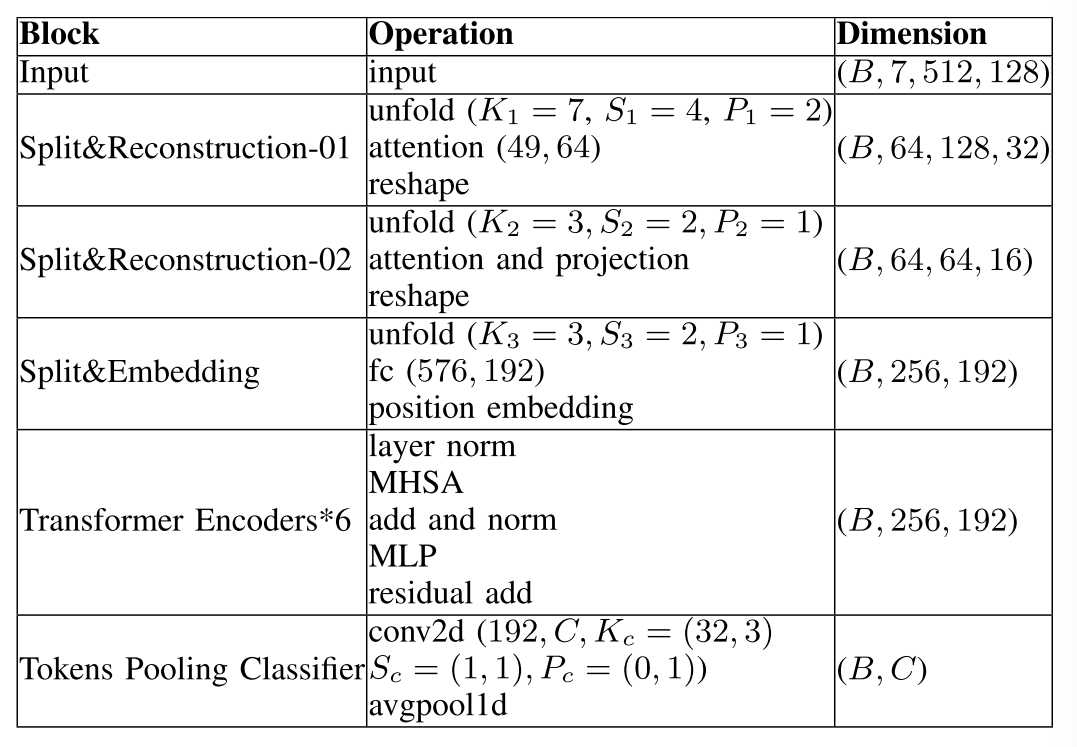
UATR-变压器体系结构的详细描述
The detailed description of the UATR transformer architecture can be seen in Table I, in which B means the batch size, C is the number of classes, Kc, Sc,and Pc are the kernel size, stride, and padding of the convolution block, respectively.UATR Transformer架构的详细描述可以在表I中看到,其中B表示批量大小,C是类的数量,Kc、Sc和Pc分别是卷积块的内核大小、步幅和填充。
3.DATASET DESCRIPTION
数据集描述
We conduct experiments on two publicly available datasets: First, the Shipsear database of underwater noise produced by various vessels [15]; this dataset is recorded in a shallow water environment, in which case it contains both the natural and anthropogenic environment noise in real conditions.我们在两个公开的数据集上进行实验:首先,由各种船只产生的水下噪声的Shipsear数据库[15];该数据集在浅水环境中记录,在这种情况下,它包含真实的条件下的自然和人为环境噪声。
In addition, a larger dataset refers to the Deepship database [16], which consists of 47 h and 4 min real-world underwater recordings produced by more than 250 types of ships belonging to four classes (no background noise provided).此外,更大的数据集是指Deepship数据库[16],其中包括47小时和4分钟的真实水下记录,由属于四个类别的250多种船舶产生(没有提供背景噪音)。
For both datasets, sample data is first resampled at a sampling frequency of 16 kHz.对于这两个数据集,首先以16 kHz的采样频率对样本数据进行重新采样。
To jointly take feature size, computer resources, and classification accuracy into account, all audio files are sliced into 5-s segments with the proper size, and randomly shuffled before training, of which 70% of them are selected for training and the remaining 30% for testing.为了综合考虑特征大小、计算机资源和分类准确性,所有音频文件都被切成大小合适的5秒段,并在训练前随机洗牌,其中70%用于训练,其余30%用于测试。
Details of the two datasets can be seen in Table II.两个数据集的详细信息见表II。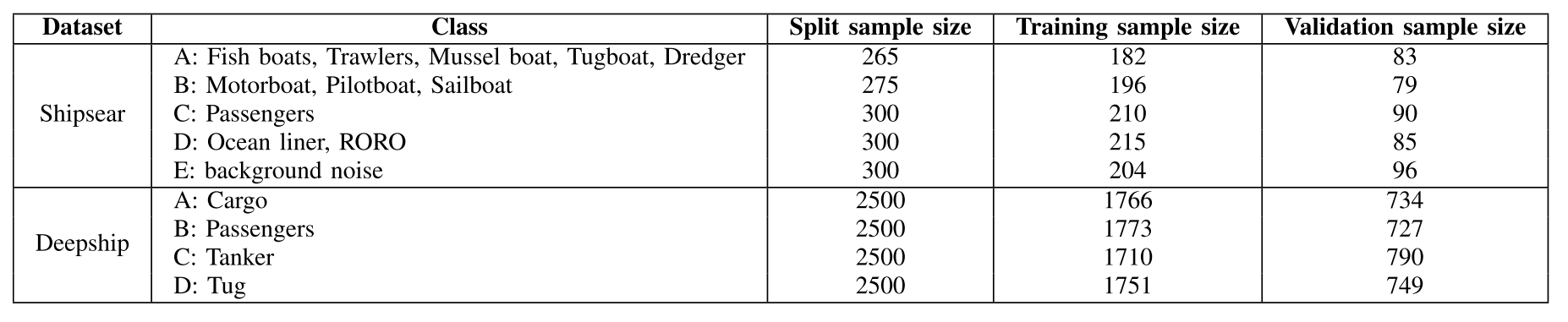
数据集分区
4.EXPERIMENTAL RESULTS AND DISCUSSION
实验结果和讨论
All experiments are conducted using Pytorch 1.8.0 with Python version 3.8 and verified by a computer with GPU of Nvidia GeForce RTX 3090 and Core i9-10900K CPU.所有实验都使用Pytorch 1.8.0和Python 3.8版本进行,并在具有Nvidia GeForce RTX 3090 GPU和Core i9- 10900 K CPU的计算机上进行验证。
For data augmentation, we employ the T–F mask optimization by the implementation of torchaudio.transforms.FrequencyMasking and TimeMasking, of which the frequency mask is 48 and the time mask is 192 in our experiments.对于数据增强,我们采用了T-F掩码优化,通过实现torchaudio.transforms.FrequencyMasking和TimeMasking,其中频率掩码为48,时间掩码为192。
And we normalize the input Mel-spectrogram before being applied to the model so that the dataset mean and standard deviation are 0 and 0.5, respectively.在应用于模型之前,我们对输入的Mel谱图进行归一化,使数据集的平均值和标准差分别为0和0.5。
Moreover, as a classification task, the cross-entropy (CE) loss LCE is used as the loss function, which is shown as follows:此外,作为分类任务,使用交叉熵(CE)损失LCE作为损失函数,其如下所示: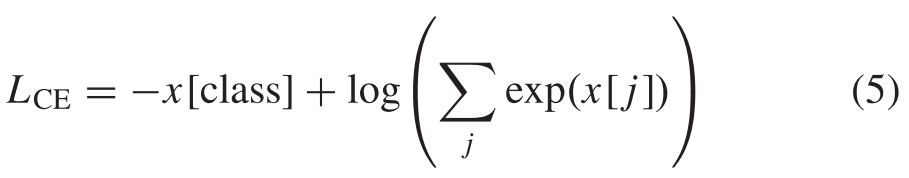
where x[class] and x[ j ] are the one-hot label of sample x and the probability of class j output, respectively, j = 1, 2, … , C,and C is the number of classes.其中x[class]和x[ j ]分别是样本x的独热标签和类j输出的概率,j = 1,2,.,C,C是类的数量。
In our experiment, layer normalization is applied before each layer and residual modules to reduce the distribution variation between channels, which is proved more effective than batch normalization for the transformer architecture.在我们的实验中,层归一化应用于每个层和剩余模块之前,以减少通道之间的分布变化,这被证明比批量归一化更有效的Transformer架构。
For the Shipsear and Deepship experiments, we use a fixed initial learning rate of 1e−4and 2.5e−4, and cut it with a decay rate of 0.5 and 0.6 after 50 epochs, respectively.对于Shipsear和Deepship实验,我们使用固定的初始学习率1e− 4和2.5e−4,并在50个epoch后分别将其削减为0.5和0.6的衰减率。
Moreover, the batch size is 16 and 32 for Shipsear and Deepship, respectively, and the number of epochs is both 80, other hyperparameters are the same for the two datasets. We mention that these hyperparameters are determined by repeated experiments.此外,Shipsear和Deepship的批量大小分别为16和32,epoch数均为80,其他超参数对于两个数据集是相同的。我们提到,这些超参数是通过重复实验确定的。
The network parameters are updated with the Adam optimizer.使用Adam优化器更新网络参数。
The loss and accuracy curve in Fig. 3 depicts that the UATR transformer was not overfit.图3中的损耗和精度曲线显示UATR Transformer不是过拟合。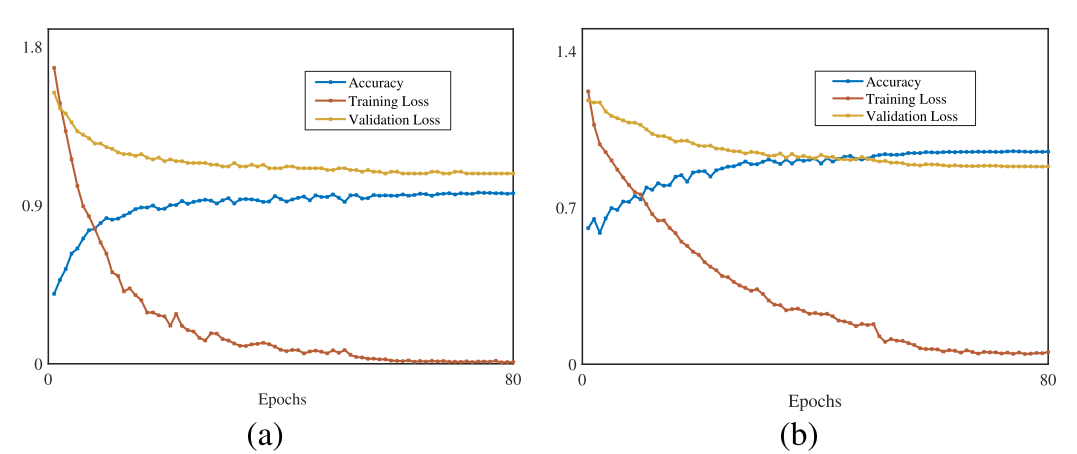
准确性、训练和验证损失随时间的变化。在(a)Shipsear数据集和(B)Deepship数据集上进行实验。
In the first experiment, the effect of different transformer structures is comprehensively analyzed, in which AST represents the AST with traditional [CLS] token and MLP classifier, AST-TP means the AST with tokens pooling classifier, UATR-transformer-MLP represents the UATR transformer with traditional [CLS] token and MLP classifier, and the UATR transformer means the designed UATR transformer with tokens pooling classifier.在第一个实验中,全面分析了不同Transformer结构的效果,其中AST表示具有传统[CLS]令牌和MLP分类器的AST,AST-TP表示具有令牌池分类器的AST,UATR-Transformer-MLP表示具有传统[CLS]令牌和MLP分类器的UATR Transformer,UATR Transformer表示设计的具有令牌池分类器的UATR Transformer。
We report the average overall accuracy (OA) and Kappa value for five-times experiments, of which OA_se and Kappa_se are corresponding assessment metrics for the Shipsear dataset, while OA_ds and Kappa_ds for the Deepship dataset.我们报告了五次实验的平均总体准确度(OA)和Kappa值,其中OA_se和Kappa_se是Shipsear数据集的相应评估指标,而OA_ds和Kappa_ds是Deepship数据集的相应评估指标。
不同变压器的性能比较
As illustrated in Table III, we can clearly see that the UATR transformer achieves the best recognition performance on both datasets.如表III所示,我们可以清楚地看到,UATR Transformer在两个数据集上都实现了最佳识别性能。
It is probable that using hierarchically split tokens via T–F token aggregating makes the features more discriminative.通过T-F令牌聚合使用分层拆分的令牌可能使特征更具区分性。
Meanwhile, owing to the integrated information from the frequency domain, the tokens pooling classifier has more advantages than [CLS] token and MLP in traditional transformer for UATR.同时,由于结合了频域信息,令牌池分类器比传统Transformer中的[CLS]令牌和MLP具有更多的优势。
In the second experiment, the performance of the model is evaluated on both accuracy and complexity by comparison with other DL methods.在第二个实验中,通过与其他DL方法的比较,从准确度和复杂度两个方面评估了该模型的性能。
We set up the UATR-transformer model that has comparable trainable parameters with EfficientNet-b0 (CNN) [17], CRNN (CNN + LSTM) [1], and MbNet-V2 (DW separable CNN) [18], of which the main module among them has been widely used for UATR [5], [6], [19].我们建立了UATR转换器模型,该模型具有与EfficientNet-b 0(CNN)[17],CRNN(CNN + LSTM)[1]和MbNet-V2(DW可分离CNN)[18]相当的可训练参数,其中主要模块已广泛用于UATR [5],[6],[19]。
We mention that networks are modified to accept the input of 1-D Mel-fbank features and trained from scratch as the UATR transformer with the same data augmentation strategy.我们提到,网络被修改为接受1-D Mel-fbank特征的输入,并从头开始训练为具有相同数据增强策略的UATR Transformer。
To show the real-time performance of the prediction model, besides OA and Kappa, we report the number of trainable para- meters (No.params), the average prediction time (Avg.time) with the standard deviation, and the frames per second (FPS) on ShipsEar to evaluate the computational complexity shown in Table IV.为了显示预测模型的实时性能,除了OA和Kappa之外,我们还报告了ShipsEar上的可训练帕拉数量(参数数量)、平均预测时间(平均时间)和标准差以及每秒帧数(FPS),以评估表IV中所示的计算复杂度。
两种数据集上CNN方法的比较
Regarding the recognition accuracy, the results obtained by EfficientNet-b0 and CRNN are close, and each has its advantages on either dataset.关于识别精度,EfficientNet-b 0和CRNN获得的结果接近,并且在任何一个数据集上都有各自的优势。
Owing to the combination of DW and pointwise (PW) components for extracting feature maps, MbNet-V2 achieved better performance compared to EfficientNet-b0 and CRNN that make use of conventional convolution operations, while the UATR transformer achieved satisfactory recognition accuracy on both datasets in the case of the same hyperparameter setup, of which the OA was 96.9% and 95.3%, Kappa value of 0.959 and 0.937, respectively, which has proved its advanced robustness and generalization ability.由于DW和逐点(PW)分量的组合用于提取特征图,MbNet-V2与使用传统卷积运算的EfficientNet-b 0和CRNN相比具有更好的性能,而UATR Transformer在相同超参数设置的情况下在两个数据集上都获得了令人满意的识别准确率,其中OA为96.9%和95.3%,Kappa值分别为0.959和0.937,证明了其先进的鲁棒性和泛化能力。
In addition, for all models, the performance was slightly worse on the DeepShip dataset, probably because the DeepShip dataset was a larger and more complex dataset, which makes it more difficult to recognize. Regarding computational complexity, the UATR transformer predicts acoustic targets more quickly than other CNN models due to the progressive token embedding strategy designed to reduce redundancy.此外,对于所有模型,DeepShip数据集的性能略差,可能是因为DeepShip数据集更大,更复杂,这使得它更难以识别。关于计算复杂性,UATR Transformer比其他CNN模型更快地预测声学目标,这是由于旨在减少冗余的渐进令牌嵌入策略。
EfficientNet-b0, which contains the largest parameters, reports the worst prediction speed with an Avg.time of 13.4 ms due to its large spatial size and wide network width.包含最大参数的EfficientNet-b 0报告了最差的预测速度,平均时间为13.4 ms,这是由于其空间大小和网络宽度较大。
MbNet-V2 takes a shorter prediction time due to the use of DW and PW, which makes it having a relatively low number of parameters and operational cost compared to the conventional convolution operation.由于使用DW和PW,MbNet-V2需要更短的预测时间,这使得它与传统卷积运算相比具有相对较低的参数数量和操作成本。
In summary, the comparative results show that the recognition accuracy of the UATR transformer is significantly higher than that of the other representative models with relatively small model parameters and the best processing speed.综上所述,对比结果表明,UATR Transformer的识别准确率明显高于模型参数相对较小、处理速度最好的其他代表性模型。
As major parameters for the UATR transformer, we further analyze the parameter sensitivity of embedding dimension DEmbedding, the number of heads H, and the number of transformer encoders N based on the Shipsear dataset for efficiency.作为UATR Transformer的主要参数,我们基于Shipsear数据集进一步分析了嵌入维数DEmbedding、头数H和Transformer编码器数N的参数敏感性,以提高效率。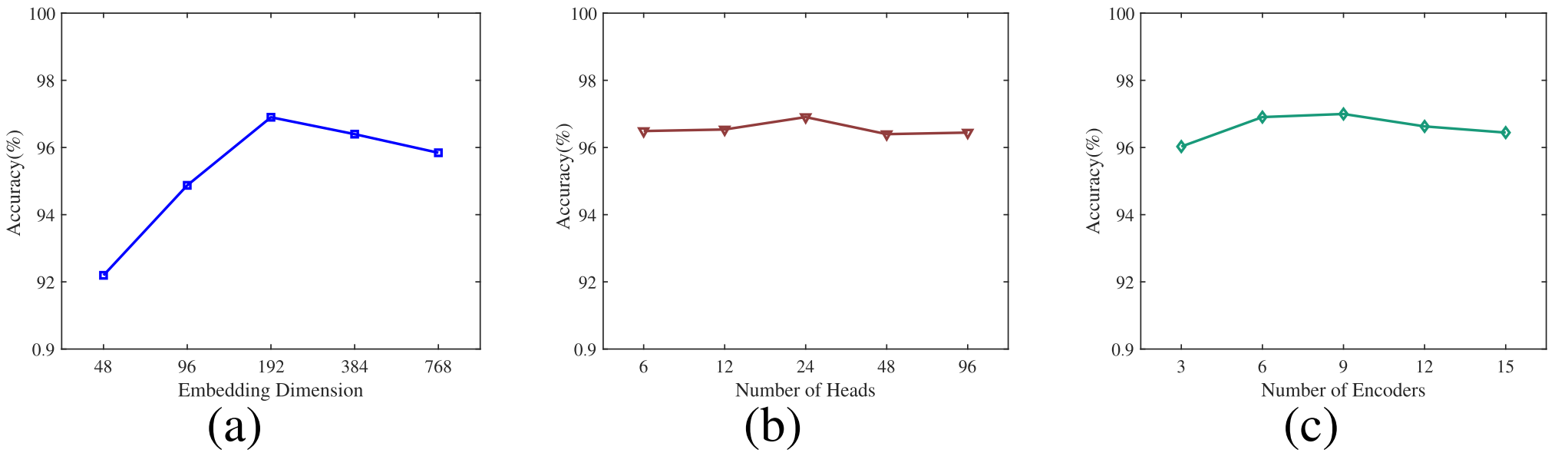
参数DEmbedding、H、N对基于Shipsear的OA的影响。(a)不同的嵌入维数DEmbedding。(b)不同的头数H。(c)不同数量的编码器N。
As can be seen in Fig. 4(a), when DEmbedding > 192, the performance is slightly worse, this is probably because that model cannot aggregate the information between too long-distance tokens, which may also bring redundancy and thus decreases the recognition accuracy.如图4(a)所示,当DEmbedding > 192时,性能稍差,这可能是因为该模型不能聚合太长距离的令牌之间的信息,这也可能带来冗余,从而降低识别准确率。
While for small DEmbedding, some important information may be discarded so that spatial features are insufficiently captured, in which case the performance significantly drops.而对于小的DEmbedding,一些重要的信息可能会被丢弃,使得空间特征不能被充分捕获,在这种情况下,性能显著下降。
With regard to the effect of the number of heads H shown in Fig. 4(b), larger heads H have no significant effect on recognition accuracy, which indicates that small H is also useful to perceive spatial information between each token.关于图4(b)中所示的头部H的数量的影响,较大的头部H对识别准确性没有显著影响,这表明小的H对于感知每个标记之间的空间信息也是有用的。
Moreover, based on the results plotted in Fig. 4(c), when the number of encoders N < 9, the performance will be improved as N increases.此外,基于图4(c)中绘制的结果,当编码器的数量N < 9时,性能将随着N的增加而改善。
It is probable that the deeper network enhances the representation ability and thus improves layer-by-layer feature learning performance. While for N > 9, the model may be overfitted to a certain extent, and therefore the performance decreases on Shipsear.更深的网络可能增强了表示能力,从而提高了逐层特征学习性能。而当N > 9时,模型可能会出现一定程度的过拟合,从而导致模型在Shipsear上的性能下降。
In all, embedding dimension DEmbedding parameter is more sensitive to the UATR transformer than H and N.总的来说,嵌入维数DEmbedding参数对UATR Transformer的影响比H和N更敏感。
5.Conclusion
In this letter, an UATR method based on the UATR transformer is proposed.本文提出了一种基于UATR Transformer的UATR方法。
In the UATR transformer, input representation such as 1-D Mel-fbank features is first split into T–F tokens with a proper embedding dimension.在UATR Transformer中,输入表示(例如1-D Mel-fbank特征)首先被分割成具有适当嵌入维度的T-F tokens。
Then neighboring T–F tokens are aggregated into smaller tokens on both time and frequency dimensions to reduce the token size and redundancy.然后,相邻的T-F tokens聚合成更小的令牌上的时间和频率维度,以减少令牌的大小和冗余。
In this case, the UATR transformer can capture both global and local information on spectrograms and thus improve the UATR performance.在这种情况下,UATR Transformer可以捕获频谱图上的全局和局部信息,从而提高UATR性能。
In all, the UATR transformer shows superior performance with relatively few model parameters compared with CNNs, which have proved the effectiveness of introducing the transformer into UATR.总之,UATR Transformer与CNN相比,在模型参数相对较少的情况下表现出上级的性能,这证明了将Transformer引入UATR的有效性。
For future research studies, with the various designs of the transformer, its great potential in UATR is believed to be revealed.对于未来的研究,随着Transformer设计的多样化,其在UATR中的巨大潜力将被进一步挖掘。