ImageNet Classification with Deep Convolutional Neural Networks
AlaxNet是深度学习整个浪潮的奠基作之一,发表在2012年。
我们读这篇文章有两个目的。
第一个目的是给大家演示一下怎么用我们之前讲的三步读论文法读一篇文章。三步法就包括了 第一遍我们看一下标题摘要和结论,第二遍我们快速读篇文章,第三遍我们再深入读,我们可以再随时在中间停下来说不往下了, 如果你读到最后就意味着你这篇文章对你非常重要。我们假设自己回到九年前的状态去看我们怎么样去读这篇文章。
第二个目的是说我们回到现在看一下9年后,我们再来读这篇经典的文章,看一下里面哪些东西是还是成立的,哪些东西可能从现在角度来观点来看已经过时了,再经典的文章也是有时代局限性的,所以里面那些精髓我们是保留下来。
第一遍
1.标题
ImageNet Classification with Deep Convolutional Neural Networks
标题看到是两个词。
第一个词叫做ImageNet Classification,回到九年前,你可能也是听说过ImageNet,当时是图片分类最大的数据集,100万的图片,然后1000类,不管你说机器学习还是说计算机视觉,你可能都听说过他。
第二个词你可能就不那么理解了,就是Deep Convolutional Neural Networks,神经网络你应该是听说过,学人工智能、学机器学习,多多少少会学到过神经网络,卷积神经网络你不一定学到,那时候大家一般都不怎么讲,一般大家讲的是树、SVM讲的比较多,加一个Deep那你可能是更没听说过了,这很有可能你看到这个词之后,你可能觉得跟我的研究方向没什么关系,我就不看了,这非常有可能,这是我们现在假设是说你有师兄或师姐告诉你说这篇文章值得一读。
2.摘要
摘要第一句话是说,我们训练的一个很大的、很深的卷积神经网络,用来对120万张图片做分类,这里面有1000个类,第一句话就告诉我干了什么事情。然后他就说我的结果在测试集上面,我的top-1和top-5的错误率是分别是37.5%和17.0%,他说我比前面的工作都要好。
这个是比较有意思的一个写法,就是很少有人第一句话我做什么第二句话我的结果很好,这个是非常少见的一种写法。
然后他说这个神经网络有6000万个参数和65万个神经元。
首先你可能不一定知道神经元是什么东西,但是参数你看下还是挺厉害的,就是说你看看自己的SVM或者是你的线性模型可能参数根本就没那么多,所以看到这个数字还是比较吓人的。
然后他说我这个神经网络有五个卷积层,然后有一些是MaxPooling层,然后有三个全连接层,然后最后一个100层的softmax。
你如果第一次读的话,你可能也不知道他在干干什么事情,反正你知道是讲我的模型在干嘛。
他说为了训练快一点,我们使用了一个什么东西,然后使用了gpu的实现。
GPU的实现在2012年已经算是比较正常了,就是在我记得2007年NVIDIA出了CUDA这个库之后,在过去的几年之内,就2012年过学几年之类的GPU在机学习界还用的还是挺多的,当时候大家主要还是用Matlab,Matlab也有很多gpu的加速包,这块用的还挺多的,所以看到这个不意外。
另外一个是说为了减少我的过拟合,我们用了一些Regularization正则的办法,叫做Dropout,然后我们又把这个模型放到了2012年竞赛中 得到了一个15.3%的top-5的测试率。
他这个东西就比较奇怪了,就是说你之前其实说的是17.0%,然后这里说的是15.3%,你可能第一眼会觉得比较奇怪,但我们就回来讲一下为什么。
然后最后一句话就是说第二名拿的是26.2%,你拿的是15.3%。
你看一下这个区别还是挺大的,就虽然我可能并不知道ImageNet绝对的错误率是多少,但是我一看你跟第二名好那么多,那还是有一定兴趣的。
这就是说你的摘要在干什么事情,所以说白了就是说我训练了一个很大的神经网络,在这个数据集上我们比第二错误率好很多,这就是整个摘要干的事情。
这个不算是一个很好的摘要,这个有点像一个技术报告干的事情,从人篇论文的角度来讲,这个比较相对来说写的, 不那么好,但是你最后一个东西就是比较强,就是说你看我就是结果好,所以在这个时候你一般来说会还是会选择往下看一眼,毕竟你好那么多,我们看一下他到底是干什么。
3.讨论
我们接下来直接跳到最后看一下是什么样子,最后这篇文章是没有结论的,他有一个讨论,就讨论和结论会不一样,讨论更多是说我看就是吐吐槽然后看一下未来要干什么事情,结论很多时候是跟摘要的一个一一的对应,所以没有结论通常来说是比较少见的一个事情。
我们看一下他的讨论干什么,他讨论说我们的结果显示,一个大的、很深的神经网络能够做一个特别好的结果在一个特别难的数据集上面,他说我们的网络的性能会往下降,如果你把一个一层神经网络去掉,就是说他有五层卷积神经网络,如果你去掉一层之后,他说我会降2%个点,所以深度是非常重要的,就是说你这个网络有多深是很重要的。
这个结论倒是没有错,但是你说我把一层卷积层拿掉然后降了2%个点,不能说明说深度一定是最重要的,因为很有可能是你参数没设好,实际上说 AlexNet能去掉一些层,然后把中间参数变一变,还是有办法达到的,就是说你当时搜参搜的不够。
但反过来讲,这个结论导致现在看起来没问题,就是说你需要很深,另外一块的话,更完整的结论是说深也很重要,但是宽度也是相对来重要的,你不能特别是特别窄,你也不能特别宽特别扁都不行,就是说像你拍照一样的,你高宽比是比较重要的。
第二段他说为了使得我们的实验更加简单 我们没有做任何Unsupervised Pre-training。
训练神经网络时,我很有可能去来一些没有标号的一些图片,把它的权重相对来说受到比较好的范围再往下训练,主要是因为深度神经网络在当时候的训练是不容易的,所以很多时候会用一些大量的没有必要的图片让他预热。
所以这句话就是说我没有用他意思,其实说我不用他没关系了,这句话就是让整个深度学习在非常长的一段时间之内主要关注于有标号的数据 ,就是叫Supervised Learning。
在之前整个深度学习,他的目的是想说我真的能够通过训练一个非常大的神经网络,在没有标的数据上把整个东西把里面内在的结构抽取出来 。因为人类学的东西很多时候是你不一定告诉你真实答案是什么,就是你读书读百遍,其义自现,所以导致说AlexNet影响了整个深度学习,这也使得,就说当时候不管是 Hinton也好,LeCun也好,还是其他大佬也好都觉得你是走了歪的方向,因为他们追求的是无监督学习,但是在过去很多年之内,大家主要关注在有标号的数据上,然后怎么样打赢别人,有意思的是,直到最近两三年BERT这一块在自然语言界的兴起才把大家又回到了无监督的学习上面,就是给我数据但是你不要告诉我标号,我真的能去从中间理解。最近很多重要的工作是基于这一块的,以至于大家觉得是一个很信赖思想,其实在AlexNet之前整个深度学习更多是做无监督的学习,为什么,因为有监督学习打不赢别人,跟SVM效果差不多,那我们只能说我的模型够大,我可以做你不能干的事情。但是 AlexNet证明的说,我在有标号的数据项,只要够大一样的打赢别人,整个学术界、工业界都在干这一块事情。
那我们之后有机会给大家讲一讲 , 现在是Unsupervised的,就是没有标号这一块是怎么做,也可能很大程度未来在几年之内大家都走这一个方向。
然后他后面说如果我们有足够多的计算资源,可以把我们的网络变得特别大, 当我有足够的资源的时候,我把网络变得很大,也没有标号的数据也没关系,然后他说只要我们的网络更大、训练更长,然后我们的结论就可以更好。但他也承认,我们现在还是跟人类的视觉还是差很远,就是说你虽然能在ImageNet上做的比较好,但是跟人的能力比还是差远,这个东西在当时是这样,但是现在来看,在图片里面找找简单的事情,深度学习已经做比人类好很多了,比如说开开无人车,也现在也问题不大了。他说最后我们想用非常大和深的神经网络在video上面,因为video视频里面有一些时序的信息,时序的信息能够有很多帮你理解在空间的图片信息。然后他说我们如果有钱、有机器、有数据的话,那我们想去训练下video数据。
过去那么多年,大家在图片上面走的非常非常的远,在语言上面也走了非常远,就是在video上面 一直是走的比较慢,因为video确实对于图片来讲,它的计算量增加的不是一点点,而video很多时候都是有版权的。
这是他的讨论的部分。
然后我们第一遍里面,我们还会去看一下一些重要的图和公式,然后一些图我们来看一下是怎么回事,我们往上翻一翻。

这个图是说我的结果一些东西,这个东西当然大家是多多少少能看懂,你看一下这个图是说我是用了我们这些测试图片看一下我的分类效果怎么样。
第一个这是个摩托车,说你分对了,然后第二个是go-kart 然后说看上去也对,你预测的那些别的来看上去也不错,你说雪豹,第二个词也差不多是雪豹,cherry这个东西你可能没搞对,你可能是认的是后面是狗,然后你这个东西 你认的是一个敞篷车,你的预测敞篷车它的真实的标号是第二个。
就基本上看到是说,这图片对人来说当然是容易的,但是对一个机器学习算法来说,这个图片还真的不那么容易,毕竟它种类特别多,所以就是说, 基本上看到说效果在一些难的cass上面还是做的比较好的。
第二个图片特别有意思,第二个图片是说,他把这个神经网络最后的那些图片在倒数第二层的输出拿出来就得到一个长的向量,然后把每个图片都拿出来,然后去把说给定一张图片,看一下跟我这个向量上最近的那些图片是谁全部找出来,就基本上看到找出的东西都挺靠谱的。
给朵花跟我在最后一层输出那个向量的输出里面靠的很近的一些花,找出来都差不多是那个花,象也是,然后这个南瓜就是万圣节的南瓜,然后这个狗都长差不多。
就虽然这篇论文并没有讨论到这个东西有多重要,实际上来说,这个是整个最重要的一个结果,就是说深度神经网络的一个图片训练出来最后那个向量在语义空间里面的表示特别好,就是相似的图片真的会把它放在一起,所以导致说它是一个非常好的特征,非常适合用后面的机器学习 一个简单的分离器,就能做的特别好,这也是深度学习等一大强项。在这个地方虽然作者有把他的结果秀出来,但是对这个工 对这个东西的意义,大家其实要过了很久或者也过了几个月大家才知道这个东西确实效果太好了。
然后我们再往前看下还有什么重要的图。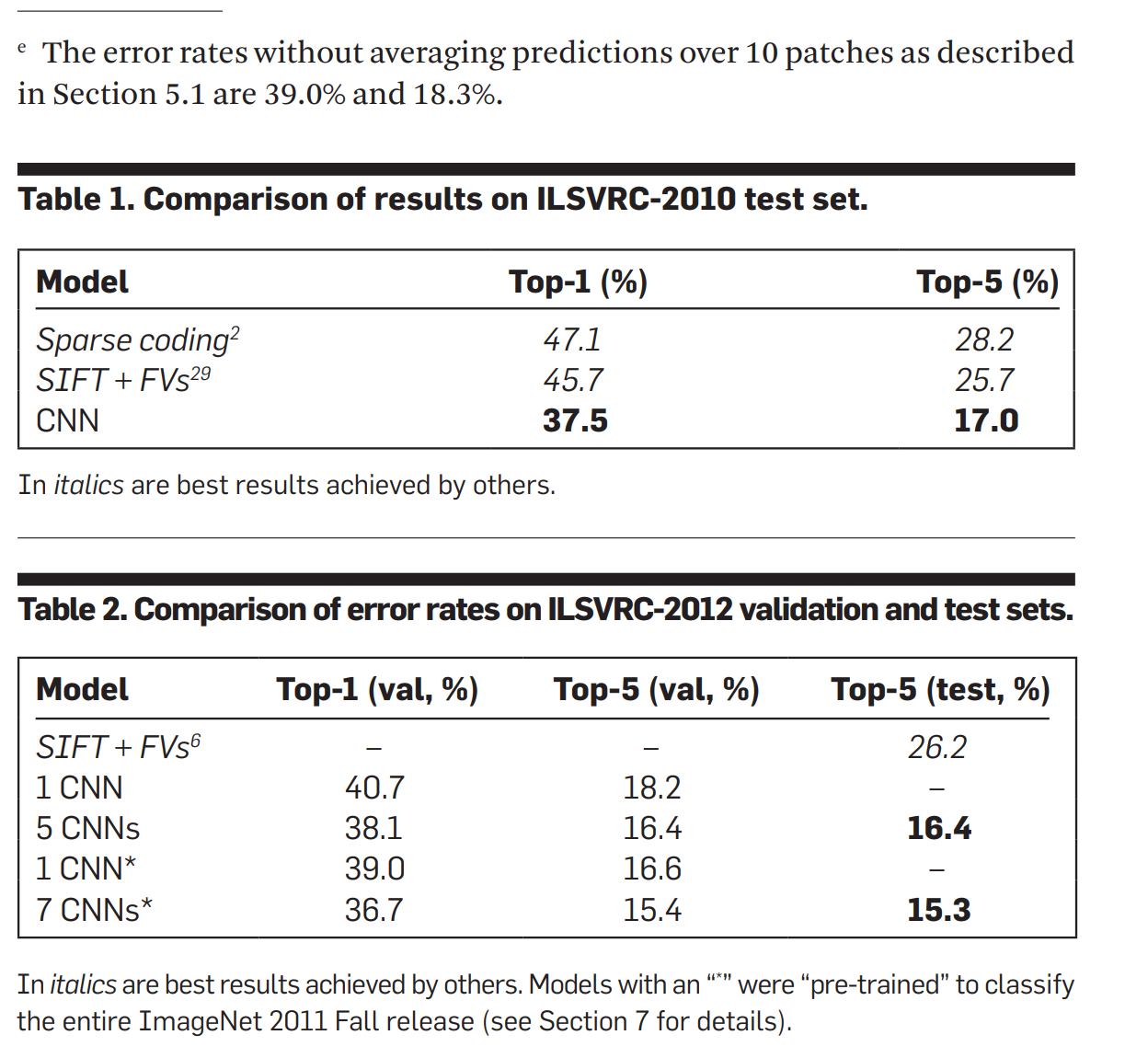
这个表表示的是我的结果跟别人的结果的对比,这个是两个当前最好的结果,可以看到别人结果在top-1的错误率上面、top-5的错误率上是远远的高于这篇文章提出来结果,这个是他其实在摘要里面说过的,但是这个地方给的更详细一点,基本上可以看到是说整篇文章的卖点是我的结果特别好。
然后再往前面看 就这是结果方面再往前面看,就是说你会看到一些一些图,如果你不做神经网络,可能是不那么了解这个图,就是说当然在计算机视觉里面,大家会多多少给看到这些图,但是如果你是刚来的话其实不知道这个在干嘛。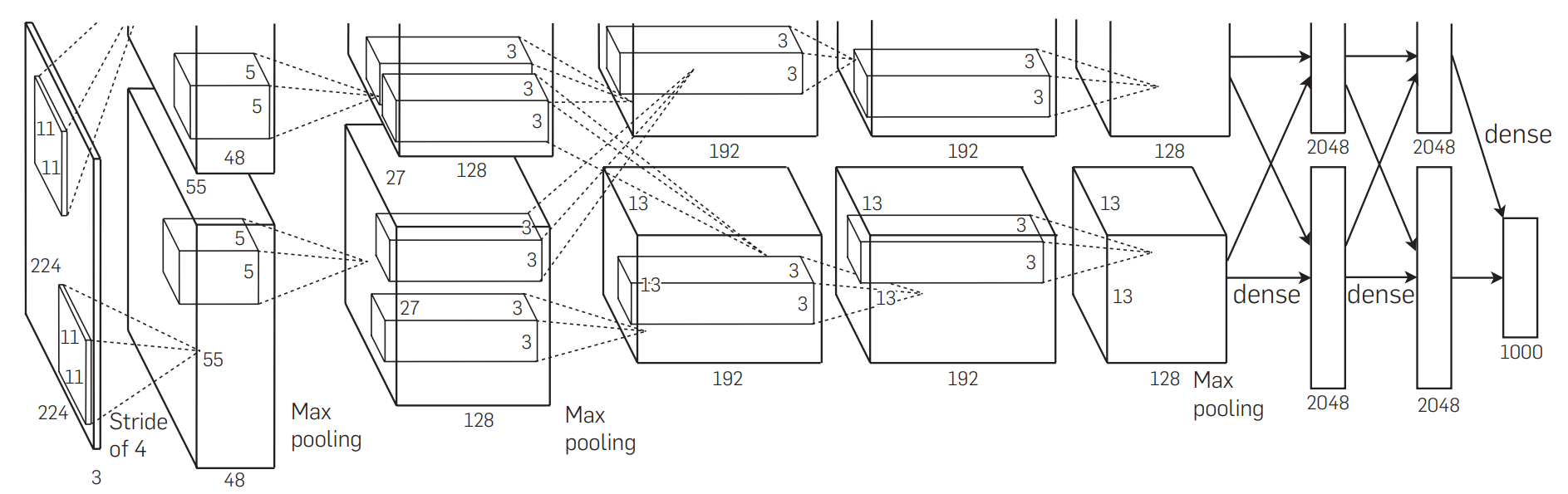
再往前面看,另外一个主要图是这个块图,就是说如果你在这一块不了解的话,是初学者的话,其实是不怎么看得懂这个图面。
我们假设自己回到九年前,我对这一块不那么了解的话,这张图在可能第一遍里面我是看不懂的, 第一遍你能看懂图通常是一些实验的结果图,和你对这一块方向比较了解的,然后看下这个图大概能理解这个东西跟我之前的知识一对比,大家能理解他做什么东西 ,但是这个一块相对来说比较新,这是开创性的工作,所以这一遍,我可以留到之后来看。
第一遍读下来就知道,这篇文章结果特别好,是用神经网络做的,但是具体为什么好,然后具体怎么做的,因为你的背景知识还不够,所以在第一遍你可以放弃,然后你这时候可以决定说,我要不要往下读,我们在假设当时你应该往下走,不然的话我们就完事了,但是在当时候,你很有可能不一定往下走,你就知道效果很好用的神经网络,但是我的研究跟这一块无关,我可能就不做这一块了,但是如果你是做图片分类这一块,你是一个计算机视觉的研究者的,你很有可能还是会往下读了,因为毕竟这块工作很好,他赢了下了比赛,那么明年那肯定会有很多人用这个方法来去试一下这家伙怎么样,所以你应该多多少少是应该往下的。
第二遍
我现在给大家读第二遍AlexNet这篇文章,第二遍里面我们需要把整个文章从头到尾读一遍,但是如果碰到了那些不懂的地方,我们可以留下来由给第三遍,但是第二遍主要的目的是知道很多细节的干什么,更多的是去了解作者是怎么想的,作者是怎么样表述东西的,每一篇文章都需要自己的观点,每个做的他都对这个世界的认识是有一定的角度的,所以通过读论文我们能够很清晰的感受到作者对整个问题的看法以及他的角度他是怎么认为的,因为写文章的时候,作者通常会把自己所有想的东西一股脑地拍在文章上面,就是一种被掏空的感觉,这个相对来说比读那些博客文章或简单来介绍什么是AlexNet才能读到的信息量更多,而且对一个人来讲,你需要读到很多文章,然后去总结很多不同的优秀的研究者对这个世界的认识,然后形成自己独特的观点,我觉得这个是一个研究者最重要的事情,每个人都需要有自己的观点,你的观点不对没关系,没有人的观点是对的,但是你一定有自己独特的观点,这样子才能够不一样,如果你跟别人的观点都一样,那么你对这个世界贡献可能就没那么多了。
当然因为AlexNet是经典论文了,我们在这一遍还要给大家讲一下他的那些对技术的选择、对技术的描述,从现在角度来看是不是真的还是这样子的,我们等会看到会知道其实里面绝大部分的对一个技术的描述、为什么做东西在现在观点来看都是错误的,而且里面有很多大量的细节 其实从现在角度来讲是没有必要的,而且是过度的engineering,但是在当时不知道的,所以大家是说我出了一个结果,把所有东西弄在一起很好,但是在后面一些年,因为这个工作特别重要,大家会去看每一个细节到底是在干什么,然后无数的研究一起去研究这个问题,把里面东西搞得特别清楚。所以现在我们从现代角度来看里面很多的细节我们是不需要知道的,然后也加入了很多新的细节使得我们在过去一些年里面,深度的卷积神经网络在图片世界以及完全打败了人类。
因为我们之前已经看过摘要和结论了,我们直接可以从介绍这一块往下读,我们就是一段一段的往下读,这样大家可以随时暂停一下,看一下这一段在讲什么,然后再继续播放,往下看我们是怎么讲的,但我们不可能给大家一句句的过,就是说大家可以扫一遍,我来讲一下每一段在干什么事情。
第一段就是说一篇论文的第一段通常是讲个故事,就这样子,我们在做什么研究,哪个方向这个方向,有什么东西,然后为什么很重要。
他讲的第一句话是说,我们要做object recognition就是物体的识别或者就图片分类,然后我们为了提升它的性能 我们要收集更大数据及训练更厉害的模型,使用更好的技术来避免过拟合。
这基本上是机器学习的正常的途径,这也是在这篇文之前,在大数据年代,大家一直在关心的,收集更大的数据 , 更大数据当然有更强的模型了,更强的模型当然是有过拟合, 其实这个过拟合这个东西是代表了深度学习的一个派别,深度学习说我可以用很大很大很大的模型,然后我通过正则来使他不要过拟合,这个是整个深度学习界在当时的一个认知,在未来几年之内大家都是这样做的,但实际上来说,你从现在观点来看,好像大家又觉得说,正则好像没那么重要,就是说叫Regularization这些东西好像并不是最关键的,最关键是你整个神经网络的设计,使得你很大很大神经网络一样的, 在没有很好的正则情况也一样样都能训练出来,但这一块大家还在做出新的方向,就是理论工作也好,实验工作也好都在推进,但是整个这一块观点代表了是整个深度学习就在很长时间之内的一个看法。
然后后面还在讲,讲数据就是说你就有Caltech-101一样最后过渡到imageNet这个数据集。
主要是因为这个标题是讲用ImageNet,所以我的吹一波刷ImageNet的这个特别好 因为它数据量大然后类别多。
然后他说,为了去识别上千种不一样的类别,在百万的图片里面,我们需要一个很大的模型,就是一个Large learning capacity,然后他就直接说我们的神经网络了。
所以这个东西是说,他们那一块人当然是一直做神经网络,所以对这块的了解比较深的。
所以他就直接说,我们要怎么样做神经网络,主要用CNN来做,然后怎么样把CNN做的特别大。
所以这段文章的意思是说,大家应该用CNN来做这个事情,因为CNN这个是一个很好的模型,因为做大很容易overfitting(过拟合), 或者训练不动,所以我们要去怎么看它。
他这个写法是有问题的,因为写法的问题,当时候的主流大家不用CNN,当你主流的模型是用别的,所以就说你半句话不提别人的算法,然后直接只提CNN 是一个非常一个很窄的一个视角,所以你写论文的时候,千万不要只说我这个领域这个小方向大概怎么样,但是你要提到别的方向怎么样,就是做一个稍微公平一点的一个介绍。
第三段是说,CNN虽然很好,但是很难训练,训练不动, 但是好处是说我现在有了gpu了,gpu能够算力能跟上,使得我能够训练很大的东西,而且这个图片、数据集够大我确实能够训练比较大的CNN。
基本上前面三段是讲了一个故事,我做什么东西,现在为什么人做了。
第四段是讲的是我这个paper的一个贡献,他第一句话当时说我们训练了一个最大的神经网络,然后取得了特别好的结果,然后我们使写了一个实现了一个GPU上性能很高的一个2D的卷积,然后我们的网络有一些新的和不常见的一些特性,然后能够提升他的性能,然后降低他的训练时间,然后他说我在第三节会给大家讲。
第四节讲的是说这个网络很容易为很大就会过拟合我们做一些什么样过拟合的方法使得它的变好。
最后 我们的网络有五个卷积层、三个全连接层 ,然后深度好像很重要,我们觉得我们发现移掉任何一层都不行。
这基本上你看到是他说第三节讲的是说我们做了一个新的网络,第四节讲的是怎么样避免过拟合,跟前面的说法其实对了,就是说我需要大的数据集、大的模型,然后要避免过拟合,大数据集不是我们做的,是ImageNet,我们用它了,然后我们说我们怎么样做一个更大的网络,怎么样避免过拟合,所以这是他们主要的贡献,当然他的主要的结果是说,我训练一个很大的模型,结果特别好。
这个东西写的是没问题的,我觉得写的是,你要做一个东西的话,如果你说我在ImageNet上取得特别好的结果 拿到第一名,但是我是怎么做的呢,我就是拿了100个模型,把它融合起来做了拿了第一名,这个就没什么意思了,比如说你在模型上似乎没有太多创新,更多是一些工程上的技术上的创新,所以你写论文的时候,别人大家可能不会那么喜欢。
但是你现在说我虽然拿了第一,但是我用了一些Unusual feature,新的一些没用过的一些东西,然后使得它可以做很大,然后有一些新的一些技术,可以让我来降低过拟合,新的技术是比较有意思的,就是说你用新的技术又取得了比较好的成绩,那就是挖了一个大坑,别人能够继续往下做,你用了就说你炫技,把很多技术放在一起拿了一个最好成绩,对别人是没有太多的启发性的,别人就说这东西做的太好了,就是这东西自叹不如,就像说我做了一个世界上最大什么东西,就是你上传到b站娱乐下,大家是行的,但是你作为一个研究工作来讲就说,你这个东西过于复杂,然后过于的难以复现,我只能说你厉害我不行 我跟不了你,就说你可能能重一篇篇文章,但是你很难得到一个引用率特别高的文章,所以这篇文章当然是说我不仅做了,效果很好,毕竟是我还是有创新在里面的会在第三章和第四章来讲,所以这个就可以看到是说这篇文章最重要的就是第三章第四章,虽然我的卖点还是说我的结果很好,但是我还是有新东西的,因为反过来讲如果你就结果很好,没有新东西,大概是不会成为奠基作对吧。
然后在后面是说我们是在GPU上训练的,但他用的是GTX580显卡,如果大家打游戏的话会知道,这个其实是一个很弱的一个gpu了,然后就3G的内存,所以他说我需要把我的整个网络切开放到我的GPU上面,这个使得我的能训练。
虽然从他的角度来讲,从Alex一作的角度来讲,它确实是一个很大的工程量的一个东西,但是从后面大家对他的反应,大家其实这个东西不重要,虽然你可能花了你的80%时间就花在写这个东西上面,但是从一个研究工作角度来讲,还是这是技术上的东西,但是能够存下来东西很难,是那些很工程性的细节。
这篇文章第二章讲的是数据集,并且你的标题第一句话是因为ImageNet对吧,他就讲了下,你的卖点是因为ImageNet的结果,当然你要讲一下这个数据集吧,他就大概讲了一下数据集,我们就不仔细讲了,就基本说我有1500万的数据,然后有2万类,然后他做了竞赛2010年开始他做竞赛,竞赛的话大概是有1000类,每一类有1000张图片,1000类,所以共是100万张的图片,然后他说2010年这一届是他把他的测试集给你公布出来了,所以是说你有测试集就能够报告测试精度,这是为什么在摘要里面说我的测试精度是多少,但是从2012年开始就是他们参加的是2012年这次竞赛,2012年开始他就没有公布自己的测试集了,你只能去网上提交,提交结果就要看到结果,所以就是说他说我就只能报告一些结果,所以就是为什么在摘要里面,它能够才有两个不一样的top one和five的一个错误率,这也是源自于这个地方。
然后后面一段其实是非常重要的一段话,但是当时要读可能就没有感觉太出来,就是说ImageNet它的图片的分辨率是很不一样的,就很多时候别的数据集的分辨率都给你做好了,就是帮你裁好了,但ImageNet是没帮你裁好了,他说我怎么做呢,我就是说把每张图片变成个256x256的图片,他具体怎么做,就是说,他首先把这张图片的短边,把你减少到256 长边是保证高宽比也往下降,但是如果你多出来怎么办呢,多出来就是说长边如果多于256的话,他以中心为界能把两个边会给你裁掉,就裁成一个256x256的图片。他说我没有做任何的预处理了,就是剪裁一下,然后他说我们的网络是在raw RGB Value上训练的。
就这个东西可能你是要做计算机视觉人才会理解,就是说当时候大家都是一个图片过来,然后把特征抽出来,抽SIFT的也好,抽别的特征好,就算是image net的数据集他也提供了一个SIFT的版本的一个特征,但是这个工作说我不要抽特征,我直接是在原始的Pixels上做了,所以这篇文章并没有把它做一个卖点,但是在之后的工作里面基本上卖点主要是End to End(端到端)。
所谓的End to End 是说我原始的图片 原始的文本直接进去,我不要做任何特征提取,我的神经网络能帮你做出来。
虽然这篇文章讲到时候我是这么做的,但是他也没有大概是意识到这篇文章这个东西的重要性,所以为什么是说这篇文章写的一般呢,是说有可能是你从当时的历史局限性你没有看到这个东西对整个业界的影响,就是你就报告了我是怎么做的,并没有说哪些东西重要,那些东西不重要,所以就说没有把你的亮点写出来,但是这个是一个足够重要的工作 在之后的无数人去读这篇文章、复习的篇文章把它里面种东西提出来,这样慢慢的会变成整个深度学习一些核心的价值,在这个地方你很多时候你是一些原始的东西,你可能是要自己真正的去动手去关注的工作,然后去往下做研究,你大概理解到我用原始的rgp图片有多舒服。
所谓的SIFT的,我现在没有搞清SIFT得到有什么抽的,但是我知道AlexNet是怎么做的,所以就是说,现在我能够搞清楚整个原始图片到最后结果一步步是怎么来的,我不需要你知道那么多一些专业的知识,我也不想知道计算机视觉在过去30年之内做特征是怎么做的,其实我一我我曾经去读过,但是我其实很很早之前后我就忘了,所以说简单有效东西是能够持久。
第三章这前面提供的就是讲我整个网络的架构,这个是它文章的主要的贡献之一,另外的贡献是怎么样避免过拟合,这是第四章。
他说我这个架构在图二。
我们图二刚刚看了一眼,就是那个一个很复杂一个图,如果你是没有相关的背景的话,看到个图是有困难的,我们先看下文字是怎么讲的。
他说首先我们最重要的一个叫做ReLU的一个非线性的东西,在标准的里面你神经网络里面的激活函数用的是tanh或者是一个Sigmoid的。
如果你学过的话,大概也知道Sigmoid是什么东西。
他说但是这些饱和的非线性激活函数会比那些非饱和的非线性函数要慢,他说非饱和的叫做f(x)等于是0和1输入取个最大值。
但是其实你如果刚读的话你也不知道是什么东西,就是说我们圈一下 ,饱和的和非饱和的是什么东西呢,我们其实不知道的,我们第一第二遍没关系,就是我画出这是什么东西,我画一个问号是,这个东西我现在不理解,我们之后再理解没关系,但你先看下他怎么说的。
然后他说你如果用的ReLU。
这个东西叫做ReLU,深度学习的Hinton老爷子是取名界的大师,整个深度学习叫DeepLearning的名字取得多好,整个深度学习界大家都是取名的大师到最新的,BERT呀什么东西,大家的取名都Attension All you Need的,就是说取标题大家都很厉害,当然是说UP主也是取标题的大师,就是说一个东西能流行,标题是非常重要的,名字特别重要,那些搞理论的取标题不行的人都大家都被遗忘掉了。
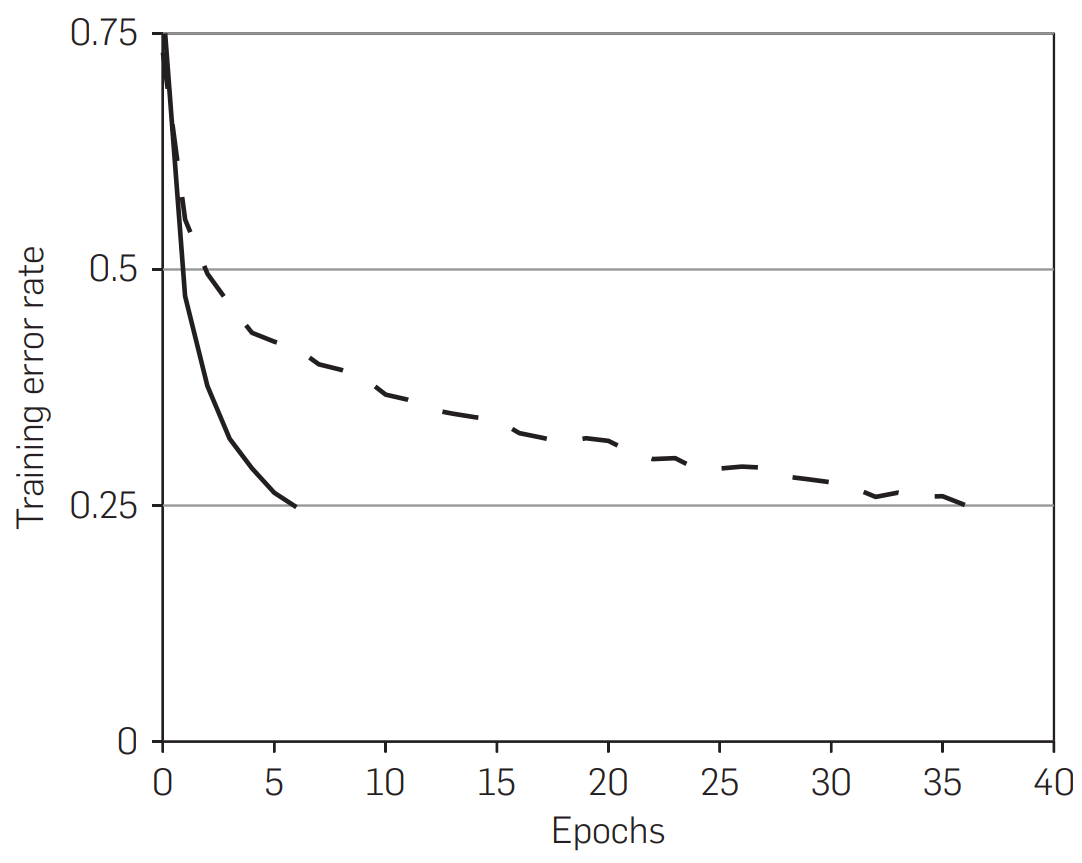
他说我用了ReLU之后,效果特别好特别快,然后你看图一就显示了,图一是说numberEpoch就是你扫多少遍数据,然后这个是你的训练的误差,基本上看到是Solid line也就是识别度,实线是ReLU虚线是tanh。
就是说这个图的卖点是说我用了它之后训练的特别快,但是他为什么那么快是没有说了,就是说告诉你说我用了他之后很快,为什么呢,请你看一下别的文章会怎么想,当然你可以去读一下别的文章,因为这个地方我们应该圈出来这篇文章看一下,这个东西特别告诉你特别重要东西,我们圈出来这分钟没有读过,我们只有在第三遍或者第三遍以前,我们应该去读一下这篇文章讲什么东西。
然后他说我们也不是第一个用了这个东西了,之前有人说用了一些别的方法效果也不错,就是比如说tanh取个绝对值效果也不错,然后他说不管怎么样了能够训练更快的话当然是很重要,因为毕竟这一个深度神经网络训练起来是很贵的。
用ImageNet在九年前训练是非常贵的一件事情,如果能够快一两倍,当然大家会去愿意会去试,但现在看起来其实ReLU也没有觉得比别的人快多少,别的技术增加之后,而且当时候觉得ReLu快的一些原因,其实现在看来都不是那么的正确,而且现在来讲换一个别的激活函数也问题不大,但是大家还是用ReLU并不是他真的比别人好太多,是因为他简单,他就是一个跟0比下最大值,那我都不需要去记他tanh、Sigmoid是什么东西,所以就是简单就是胜利了。
第二个他觉得很重要的是说我用了多个GPU做训练,他说我的580的卡只有3Gb的内存,然后我整个神经网络需要占资源,我要训练120万的图片可以用比较大的网络,当然内存就放不下,他说我怎么样用多个GPU来做训练,他做的比较多。
就是这里其实说句真话,你第二遍可以不看他,因为什么你发现你看不懂就是说它是一个非常的工程的一个细节,如果你读论文读到这工程细节,除非你是系统方向的论文,如果是机器学习论文的话,你可以忽略掉,就说这工程的细节你可以之后真的要复现的时候再去看,因为毕竟不是方法上的东西, 当然你可以读一下这个东西,就是说他怎么样切切切切,我们当之后会给大家讲一下是怎么切的,但是我们第二遍的时候是可以忽略掉不计的。
第三个东西叫做local Response Normalization是一个正则化的、一个归一化的东西,他说虽然ReLU的性质很好,它不需要input normalization。
写这句话你不是那么看得懂的,就是说看不懂的话也可以圈一下,就是说他说ReLU不需要input normalization来避免他你饱和,他之前有提到过饱和和不饱和,其实我们也是没听懂了,就是你不知道ReLU到底有什么性质,所以我可以圈一下,你就可以说第二遍的时候你可以打个问号,就说之后我们再慢慢研究。
但是他又说其实如果你还是能够做一下Normalization,效果还是挺好的,他说这个东西怎么做
就你可以大概扫便会发现,他能讲了很多细节的东西,但这个地方他并没有讲说你为什么一定要用它,然后他效果怎么样,他就告诉你说我是这个东西定义是什么东西是怎么来的。
我们第二遍看了这么复杂公式可以忽略掉,其实也不复杂,但是你对他的记号这一块不是那么懂的话,你在第二遍多少时候你可以忽略到,但是你知道是说他是一个Normalization的东西,然后他能够使得避免你饱和,你就知道这个东西就行了。
我们可以在第三遍的时候再回来看,但是我们如果回到现在可以看到这个东西不重要,这个东西在之后几乎上没有别人用到它,所以这个东西在现在看来是一个没有太多必要东西,而且现在我们有更好的我们有Normalization的技术,如果你第三遍没有读他也不要紧,你不知道他其实也没关系。
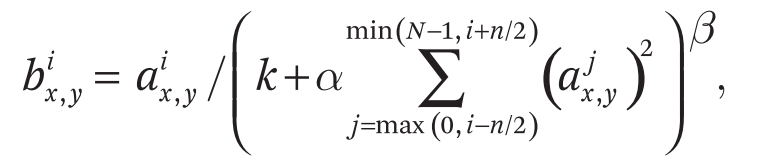
3.4讲的是overlapping Pooling,就是说Pooling这个层是把一些输入给你总结一下,一般来说两个Pooling东西是不会overlap的,就不重叠的,就是说我现在要overlap。
这东西在你第一遍读的时候,其实你可能也不算理解他要干什么事情,就说你都不知道Pooling,首先你都不一定知道Pooling是干什么东西的,我们先圈出来,这东西我们第一遍都没有看懂 东西都圈出来,然后Pooling是干什么的东西的,我们得去回过头来搜一下Pooling是干嘛,然后再说Overlapping的Pooling是在干什么东西,但是你大概理解上来说,就是说他对一个传统的用Pooling的方法做了一定的改动,改动不大,但是他说效果会很好,就是你知道他改的东西就行了。
最后 3.5是一个overall的一个架构,他讲的是说在图二里面显示了我们有八个层,然后前面五个层是卷积,后面三个层是全连接,然后最后是一个softmax,然后他说但是因为他使用多个GPU,所以他整个架构是比较麻烦的。当然大概读一下,然后然后再往下的是说我们第一个卷积层是224x224x3的一个输入图片,你看到是一个原始的图片进去了,他跟别的方法用预先抽Feature是不一样的。
所以他并没有说给大家卖一下说你看我们跟别人是不一样的,不需要预处理图片,所以这篇文章真的就是一个技术报告,就讲我做了什么东西,也不讲跟别人的区别是什么,也不讲我们这个东西到底为什么是这样子,为什么重要,但是只要你工作重要,技术报告也能够成为奠基作。
当我们现在回到现在的角度来看一下他在干什么事情,就可以看下这个图,这个图是大家讲神经网络的时候,经常会把这个图截屏给大家看一下整个网络架构。但是这个图我觉得能看懂他人不多,因为这个图根本就是一个特别复杂的一个OverEngineer就是过度的扣细节扣出来东西。
首先可以看下在框框表示什么东西,如果你第一次看的话 可能不一定理解,这框框是表示每一层的输入和输出这个数据的一个大小,他进来的时候是一张图片,是一个高宽分别是24x24的图片,它的宽度rgb的那个通道数是三,它有三个图片,就RGB它的高宽是24这个东西进来,然后第一层卷积,卷积他的一个窗口是11x11,就大家回顾一下卷积是在干什么,他是11x11然后进来,他第一层卷积有48个输出的通道,他这里有Stride等于4,但卷积的Stride的就是每次往前后往往左后往下跳四下,这里比较有意思是说他有两个GPU,就Alex小哥有两个GPU,所以他为了把这个东西塞进去,他把整个网络给你切开,横的切了一刀,这个东西是放在就是说这个地方我画一下: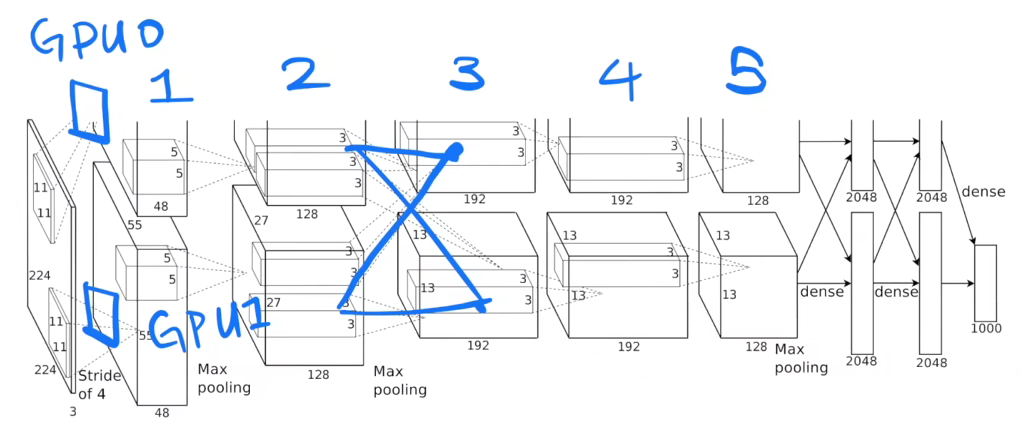
这个地方换一个颜色,这地方是有个卷积的一个层在这个地方,这个地方也有个卷积层,这个东西放在gpu0上的,这个东西是放在gpu1上的,所以gpu1和gpu0都有自己的卷积的那个核的参数,他们拿到同一张图片各做各的东西, GPU0做出来东西写来这个地方,GPU1做东西写在这个地方,所以这个这一块是在gpu1上,这一块是在gpu0上,这是他的输出的结果,那GPU1的东西然后继续往下 第二个卷积层,就是说这是第一个卷积层,就是这第一个这第二个、第三个、第四个、第五个这个是表示12345的卷积层的输出,卷积层是在前面中间那个绿色的蓝色的框框里面,可以看到是说第一个卷积层在两个gpu上各有一个,然后第二个卷积层他是在每个gpu把当前的那个卷积层结果拿过来,就是说第二个卷积层读的是gpu0的第一个卷积上输出直接进来,中间是没有任何通讯的。然后这有个奇怪的设定,到第三个的时候,小哥觉得说如果你们个搞个的不是办法,那么第三个的时候还是每个gpu上有自己的卷积核,但是他每个人会去看别人,你看一下这个东西,就是说第三个他的话他会把第二个卷积层的输出在gpu0上gpu1的都拿到,然后再看一眼,对这个也是一样 他会都拿的都看一眼,所以在这个地方他两个GPU之间会通讯一次。然后继续往下做,第四也是各搞各的,就中间是没有任何通讯的,第五个也是各搞各的,只是说每个都不一样,就是你能看到是通道数的有增加,通道数从48变到128变到192变到192,那他的高宽是有在变化的,就是说你看到它的这个地方本来是224x224现在你的变成了高宽变成了55x55,然后变成27x27、13x13,就基本上你看就是说你的输入来是一个很瘪的很宽的一个图片,然后把它高宽慢慢的变小,但是深度的慢慢的增加,你随着你的网络增加,我慢慢的把空间信息压缩,24x24高宽,我慢慢的压缩我的空间信息压到最后是13x13,就是你认为这个里面的每一个像素能够代表前面一大块的像素,然后我再把我的通道数慢慢的增加,就是说你可认为每个通道数是去看一种特定的一些模式,就192个你可以简单认为是说我能够识别图片中间的192种不同的模式,就每一个通道去识别一个是猫腿还是一个边,还是一个什么东西,所以就是说他在慢慢的压缩你的信息,把空间信息压缩,但是这个是个语义的一个空间慢慢的增加,到最后卷积完之后进入全连接层,全连接层你看到这个地方又来了一个在机器之间的就两个卡之间的通讯,全连接层的输入是每个gpu第五个卷积的输出合并起来,合并成一个大的做成全连接,全连接虽然还是各搞各的,就每个人做一个2048的一个全连接,但是最后的结果是要拼回成一个4096的,就是实际上来说一个24x24x3的图片最后再进入你最后的分类层在这个地方的时候,它是表示成了一个4096长的一个向量,包括了说每一块是来自两块卡一片是2048一片是2048最后拼起来,所以说说一张图片会表示成一个4096的这个维度,然后最后用一个线性分类去做链接,这是他整个架构的事情,所以他没写,但是整个这一个东西是一个奠基性的工作,所以他来我们在第一遍的时候有讲过,这个长为4096的向量其实是很好的能够抓住你的语义信息,如果你两个图片它的4096的向量特别相近的话,这两个图片很有可能是同一个物体的图片,所以在深度学习一个主要的用处是说一张图片通过前面这些东西最后把它压缩成一个长为4096的一个向量,这个向量能够把中间的语义信息都能表示起来,就说他变成了一个机器能懂的东西,这是一个人能看懂的像素,通过这一块做特征提取之后变成了一个长为一个4096的机器能看到东西,这个东西第一可以用它来做 各种搜索也好,做分类也好,做很多事情都可以,所以整个机器学习你都可以认为是一个知识的压缩的过程,你前面的原始的数据不管是图片文字还是语音还是视频,它通过中间一个模型最后压缩成一个向量,这个向量机器能够去识别,然后机械的识别之后,他就能够在上面做各种各样的事情,这才是整个深度神经网络的一个精髓之所在,这个地方就是说已经这个雏形已经很明确了,所以说是怎么做了,但是它的重要性在后面的研究者把它们做出来。
反过来讲这个模型我是说大家都其实很多事都没仔细看过这个模型长什么样子,是因为他太复杂了,可能有两个原因。第一是Alex小哥为了能在他的那两块卡上训练这个东西,他强行把你切开,切成了一个上下都有的,他觉得是一个贡献,因为他可能花了很多时间去写代码去把它做出来,但是在现代角度来去看这个东西是一个过于复杂的技术细节,因为其实你就算是3Gb的内存你一样的能训练,你把你的代码实现好一点也是能训练的,我记得caffe是能够训练的。第二个是说这个东西你把它做到了两个gpu上,如果我有三个gpu我有四个gpu怎么办,我怎么切它,所以是说你真的就是一个数据集在你自己的机器上是这么训练的,但是他没有一定的通用性,所以导致说在未来大家基本上是忽略掉整个这一块的工作了,就是说基本上大家是就算我要做多gpu卡的训练我也不那么切模型。
但是这个世界就是30年河东 三十年河西,虽然在AlexNet出来之后在过去的起码6、7年之内大家都没有这么做过这个,其实你可以认为叫做模型并行叫model parallel,但是到最近过去两三年,就是更大的模型出来了GBDT、BERT出来了大家又发现又训练不动了,现在大家又回到了 我要把这个模型切成几块的部分,虽然这个技术再出来之后在未来几年这大家都觉得这是一个没用的东西,但是现在大家又发现这东西又很有用了(真香),在计算机视觉里面用的不多,但是在自然语言处理里面现在又成为一个主流的一个办法,把模型切开是能训练100亿的1000亿的或者甚至10000亿的模型,所以这个是整个模型,你可以认为是整个第三章它的主要的贡献就是在这一个图上面了,这个地方已经结束了,大家可以去看一下里面一些细节。
第四节讲的是如何降低过拟合,就是说我训练了一个很大的神经网络,现在说我要避免我过于的过拟合,我应该怎么办,但如果不理解过拟合的话,可以去看一下我们之前的课程,就是说过拟合就是说给你一些题你就把它背下来,你根本就没有理解题是在干什么,所以考试的时候肯定考不好,这就是过拟合,他提到几个方法,一个叫数据增强叫Dat Augmentation,Data Augmentation就是说 我们去把一些图片人工的把它变大,就他使用了其实也是别人的工作,别人已经提出的东西,他使用了两种方法,第一种方法是说因为你的图片是256x256,他随机的在里面抠一块224x224的区域出来,就随机面扣一片,拿着一做一张新的图片,那他说你这样做的话,那么我的图的大小就变成了以前的2048倍的大小,因为你有2048种抠法在这个里面,所以这个东西大家之后不会这么算,就是说你不能直接这么算,因为你的抠下东西都长得差不多,所以 你不能说自己就变成2048倍了。 第一个是空间上的抠,第二个是说我把整个RGB的channel就是那个颜色通道上做一些改变,他用的是一个PCA(主成分分析)的方法,他后面有讲过他的PCA是怎么做的,大家可以去读一下,但是第你第二遍你可以忽略的,如果你不是很清楚PCA在干什么或者是他怎么做的话,你可以选择掉忽略的东西,但是你知道它是在通道上做的一些变换使得它颜色会有不一样,所以就是这样子的话,每次图片跟原始图片是有一定的不一样性在里面。
然后他又前面有说到说我这个东西用Python写的在GPU上跑的,然后在CPU跑,然后我的模型是在GPU训练,所以说我这个东西是free的就免费的,因为我在CPU跑的很好,他当时要这么看是因为我觉得gpu相对来说不强,然后他的cpu相对来说比较好一点,但是这个东西在过去很多就是算现在,你发现GPU的发展远远的超过cpu的速度,所以导致说你如果把这个东西用python来写在cpu跑你基本上做数据增强可能是你最花时间的东西,模型训练比他快多了,所以这个结论在当时是成立的,现在看起来是说你的Date Augmentation很容易成为你的性能的瓶颈,你很有可能要搬到gpu上获得用很好的c++来实现,不过就是他觉得最重要的一个东西。
第二个东西叫做Dropou,他第一句话是说很多个模型把你放起来是很有用的,叫做Model ensemble,大家做比赛都是搞好几十个模型,然后把它做融合,但是对深度学习来讲太贵了,就是说你神经网络本来就很贵了,你还要做模型融合当然更贵,所以他怎么办,他用了一个叫Dropout的技术,Dropout的是另外篇文章,虽然也是这帮人做的,他说他随机的把一些隐藏层的输出变成用50%的概率设成零,这样子就好比是说每一次我都是把一些东西设成零就等于是说这个模型就变了,就每一次得到一个新的模型,但是这些模型之间他的权重是共享的,就除了那些设成0的、非0的东西大家都是一样的,但是他觉得这个东西这样子的话,我就每一次能得到一个新的模型,然后等价也是最后变成了很多模型做融合,这是他的思路。
但是后来大家发现是说Dropout的其实好像也不是在做模型的融合,更多的是Dropout就是一个正则项,后来他们在几年抽又重新写了一篇JMLR的文章说Dropout的在现行模型上是等价一个L2正则项,但在更复杂上面说大概是一个正则的效果,但是无法构造出一个跟他相等的一个正则的东西,但是大家现在觉得Dropout的是一个正则的东西,但当时候大家是不怎么觉得的。,
然后他说我们把Dropout的放在了前面的两个全连接上面,然后如果没有Dropout的话,就是说overfitting非常严重,如果有Dropout的话,但是他就是说我的训练会比人家慢两倍,所以AlexNet这个设计用了三个全连接,最后一个是有的,因为人家输出中间了两个很大的4096全连接是他的一大瓶颈,这是他当时设计的一个缺陷,所以导致说整个模型特别大,你根本就放不进你的gpu里面,第二个是说你要用Dropout来过避免过拟合, 现在这CNN的设计通常不会使用那么大的全连接,所以导致说Dropout的也不那么重要,而且gpu内存也没那么的吃紧了,所以就导致你的模型设计的一个决定导致你的实现来好,你加了很多新的东西,但反过来讲 Dropout的在全连接上还是非常有用的,在RNN那一块、在Attension那一块Dropout用的非常多。
这下我们来看一下第五章,第五章讲的是它的模型是怎么样训练的,他说我们用的是SGD来训练,SGD(随机梯度下降)当然现在大家都知道是训练深度学习最常用的算法,但是在当年大家并不是这么觉得,因为SGD调参相对来说比较难调,大家可能更希望用一些更稳定的算法,比如说L-BFGS或者是甚至是Gradient Descent这样子算法来计算,相对是调参更容易些,但是后来大家发现sgd它里面的噪音对你的模型泛化性其实是有好处的,所以现在深度学习大家都是用这个了,也是说在这个文章之后,SGD基本上在机器学习界成为了最主流的一个优化算法。但是我用的批量大小是128 momentum是0.9然后weight decay是0.0005,然后他们说我们发现用了一点点的weight decay是非常重要的,然后他在后面实现了这个weight decay是怎么实现了,大家就可以看一下,如果你不知道SGD的话,你应该去查一下SGD的定义是什么,如果你知道的话,你大概也知道他是在干什么。
weight decay当时候在机器学习界主流上应该叫做L2 regularization就是L2的正则项,但是因为这篇文章以及整个神经网络里面,他们喜欢weight decay这个词来用,这样子他的这个东西不是加在模型上,而是加在你的优化算法上,虽然他两个是等价的关系,但是因为深度学习的学习,所以大家现在基本上把这个东西叫做weight decay了,然后当然是momentum这个东西也是因为这篇文章之后才用的特别多,虽然在2010年的时候有大量的加速的算法里面有很Fancy的各种加速SGD算法,但是现在看起来似乎你用一个简单的momentum也是不错,他直接上来就说当你的优化的表面非常的不平滑的时候,这个冲量使得你不要被当下的这个梯度太多的去误导,你可以保持一个冲量从过去那个方向沿着一个比较平缓的方向往前走,这样子就不容易陷入到,因为你的优化的表面不那么平滑掉到也坑里面去了,让大家可以看下这个是怎么定义的: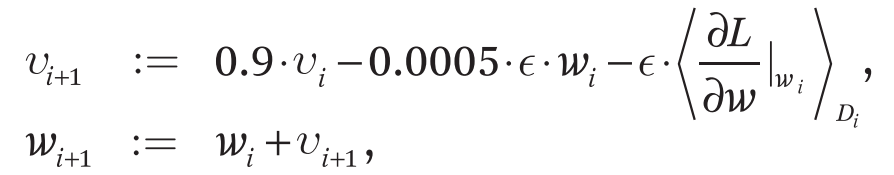
就是你的momentum项,它是等于0.9 x 过去的momentum减去你的weight decay再减去你的梯度,他的ε 这个地方其实是你的学习率一般,我们用η但是他用的是这个。
然后他说接下来我们的权重是用的一个均值为零,方差为0.01的高斯随机变量来初始化了。
我们当时要在d2l直播的时候也经常用这一个均值为0.01方差的来给大家初始化些权重,均值为你0.01是怎么选出来的,0.01也就是大家发现这个值还不错,也不大也不小,但对很多网络都是可以的,但是你如果特别深的时候,你需要更多的优化,但是对一些相对而简单。
AlexNet的从现在角度来看是一个比较简单的神经网络,0.01是一个不错的选项,你像现在就算是比较大的那些BERT 他也就是用了0.02,就大家都用0.02作为随机的初始值的方差。
我在第二层 第四层和第五层的卷积层把我的偏移量初始化成1,剩下的全部初始化成0。就是说他全连接层也初始化1了,就这个东西就比较奇怪了,其实偏移本质上来说它如果你的数据比较平衡的话,你应该初始化是要零的,但是他这里说我发现初始化1效果不错,后来其实大家也没有去跟进这一个细节,大家觉得这个东西你到底是把2还是第几层数据化的1,这个东西调参怎么调,所以大家其实觉得全部初始化为零效果也不差,而且不需要调整,所以这一个技术在后面用的是比较少的。
然后还有一个是说我用每一个层用一个同样的学习率,但是他的学习率是从0.01开始,然后他发现如果你的Validation Error就是你的验证误差不往下降了,它就手动的把它乘以0.1就是降低十倍。
这个东西当然是假设你有很多时间的话,而且你的计算比较贵的,那你就盯着你的训练,然后发现它不动了,就停下来手动调一下,这个其实在很长一段时间当时大家都是这么做的,但是后来大家觉得其实也没那么复杂,比如说ResNet他的结果就是说每我训练120轮,就120个Epoch 然后每30轮我就下降0.1,然后这也是一种主流做法。
另外一种主流做法是说你前面可以做了更长一点必须能够60轮或者是100轮,然后再在后面再下降,也是另外一种主流做法。
但是在AlexNet之后的很多训练里面,大家都是做规则性的把学习率往下下降十倍这个是一个非常主要的做法。
但是现在我们很少用了,因为毕竟你为什么降十倍,什么是要下降是比较难的,现在我们用更平滑一点的曲线来下降我的学习率,比如说我会用一个cos的一个函数比较平缓的往下降,然后当然一开始的话 0.1是怎么选的也比较尴尬,就是说一开始你不能选太大,因为你太大你就容易炸掉了,但是你如果许的太小的训练也不动,所以现在的一个主流做法就是说你学习率从零开始,然后再慢慢的上去 慢慢的下去。
所以如果画出来的话,如果这是你的Epoch轴的话,你的学习率是从一个很小的值开始然后线性的上去,然后到一个比较大的数据值,然后再用一个比如一个cos的函数这么下来,相对来说是一个平话的,你如果是用着AlexNet的话,他其实就是一个这样子的一个值(蓝色),它是一个这样子的下降每次下降十倍,但是具体什么说下降是根据手动来选的,现在大家用红色这个线更加平滑,然后调参更少也是更常见了。

最后他还说我训练了90个Cycle,用现代话也就是我训练的90个Epoch给我扫了数据90遍,然后在每一遍用的是ImageNet完整了120万张图片,需要5-6天在两个NVIDIA GTX上面训练。
这个时间上对当时候的人来说是相对来说比较长的,我调次参我得等个5-6天才能知道我的结果是什么,然后我调的五次参,那我基本上一个月就没了,当时候大家基本上能够一个小时,或者几分钟能跑出来是比较好的,这样子调参你的效率会高一点。
在ALexNet这个文章出来的很长一段时间之内,大家花了很多时间去等待你的gpu把你的模型训练出来,一等可能就是几天或者甚至是一个星期,这个导致了大家特别的想去购买最新的gpu,也是导致了Nvidia的股价在过去的一些年暴涨的一个原因,当然在Image这一块领域在过去的一些年我们的训练确实得到了显著提升,但是现在在文本领域又是要训练一次要很多天,而且是在用几百甚至几千块卡的情况下还要很多天这个也是会迎来下一次的迭代,看看我们怎么在文本里把整个计算开销,或者说绝对的时间下降到一个合理的范围,我觉得一个合理范围是几个小时是比较合理的, 或者说半天也是可以,我晚上提交的任务早上起来能看到结果,这也是比较舒服的,但是一个运任务要训练个几天,我觉得是相对来说不能忍的一件事情了。
下面一章是实验,当然实验是这篇论文最重要的部分,我就再去反过来讲,他也没有太多东西,主要还是我们之前讲过的这张图:
他说我比别人相比是要好很多,但是别人的算法我比别人基本上好了一大截,里面当然是说这些东西我是具体怎么做的,现在看起来都是很标准的一些东西了。
就是我就不再给大家重复细节了,很多是我们读论文的时候,实验部分相对来说是不那么重要的,你关心的是实验的一个效果,但是具体实验是怎么做的呢,很多时候除非你是这个领域的专家,你扫眼大概也能听懂,如果你是刚来这个领域的话,你不用太关心这些细节,除非你要去重复他的实验,只有在你要重复他的实验或者审论文或者是你是这一块的专家的时候,你会大概去看一下他的实验。
比较有意思是说,最后他报告了他在完整的imagenet上数据的时间,就完整的ImageNet的图片是有890万,比我们之前说的120万要多个7、8倍的样子,而且它有1万类,这个是一个比较厉害的结果。
其实当时候这个结果我其实不是很清楚为什么大家没有特别去关心这个东西,可能毕竟对计算机视觉来说,能在竞赛中拿到第一次相对是比较重要,但是在一个完整的imageNet上训练出来的模型的预训练效果很有可能比你在120万张图片上预训练的效果在别地方用的时候会好很多,但是比较有意思是我并没有看到后面的很多论文用的是他在完整数据上训练的模型,当我在几年之后也训练过这些模型,发现它效果确实是好一些,但是就是很奇怪大家对imageNet的印象总是拿120万的图片,但是不知道是他的完整其实是更大,而且上面的模型相对来说质量更好一点,这个也是我一直不是很理解的一件事情。
到最后是说他们之前有提过ImageNet只有2010年是提供了测试数据,2012年的时候你是得去网上提交他的数据才行,所以他只报告了五层CNN和七层CNN的相对结果,这个两个是空掉了,所以这个就是他把这个东西叫做测试集,这把2010的叫做验证集。
我觉得这个写字和文章做了很对的地方,其实在机器学习里面,很多时候大家是搞混测试集和训练集的,还有验证集的,所谓的验证集就说你可以一直测用来调参,但是你的测试集相对来说你应该就测那么几次,当然ImageNet本身的测试集也是允许你每天提交个几次,所以导致说你也不是真正意义上的测试集。
曾经有团队国内的团队去不断的注册很多小号去提交,然后把根据测试集调参,然后被主官方抓出来,也曾经成为一个新闻,但是确实在机器学习界,我们对测试集和验证集的区别,我觉得不管是工业界好也是学术界的好,意思是存在很多的误解的。
第6.1讲的是说,我来看一下我这个网络会是什么样子,他说他发现了一个比较奇怪的一个现象,因为他是在两个gpu上训练的,他的两个gpu上他卷积的话,如果你是输出通道是256个的话,其中128通道是在一个GPU上算,另外128的通道是在另外一个GPU上算,大家知道每个通道你可认为去识别了一些图片里面一些特定的一些模式,他比较有意思是说他发现在gpu1上的通道基本上是跟颜色无关的,就是但是gpu2上学习到的东西,就是那些模式跟颜色是相关的,而且他说我重复了很多次实验发现总发现了一个这样子的事情,所以他也不是很理解。
其实从现在角度来讲,你其实也不是那么理解到底你发现了什么东西,很有可能你跟gpu也没有太多关系,很多时候,毕竟这个是一个随机的东西,所以这个东西他提出一个疑问了我觉得这个地方,但是在很多年之后,大家好像也忽略掉这个事情,好像大家也没有因为大家不再这么做了,而且都是在一个gpu上把所有通道上面训练,所以大家也没仔细去看每个通道在干嘛。
图四的话就是在一些比较难的图片的分类效果和用神经网络最后倒数第二层的输出那4096位的向量去对比,别的图片时候能够把相似图片找出来,就是干的事情,他说主要是用神经网络一直被人诟病的是你到底学的是什么东西,你那么多层的东西里面到底发生了什么事情得到一个好的结果,所以这个地方他做了一些工作,但是我觉得还是对后面还有挺有启发性的,他说你可以去看一下我的每一个Feature activations,就是每一个卷积层或者全连接层他的输出那些东西在干什么,然后他写了一些结果,
这一段就是讲看看那个图片怎么来的,在后面确实很多工作是沿着这一块往下走了,大家现在大概知道说虽然很多时候你并不知道在学什么,但是有一些神经元还是很有对应性的,他在底层的神经元学到了是一些比较局部的信息 比如说纹理方向偏上的话,他学到更多是一些比较全局点的,比如说这是一个洞这一个人的头这是个手这是个动物 或者是很多信息在里面,也很多有意思的工作去看到底神经网络是学什么,他到底是学一个东西的形状 还是去学一个东西的纹理,大家其实在这一块是要非常有意思的一些发现。
但是反过来讲,神经网络现在仍然是大家不知道到底在学什么,相对于别的相对来说比较简单一点的机器学习模型来讲,它的可解释性一直是一个大家诟病的地方,但最近些年大家慢慢的开始去研究他可所谓的公平性,神经网络的偏移也是大家乐意的一个重点,因为你如果想用一个机器学习模型来真的做决策的话,这个决策能影响到人的话,那 我们当下知道说你到底是用什么来做决策,你是不是决策是公平的。
第二遍我们当然留下了很多东西 ,留下了一些我们没有特别高的东西,但是我们整个读完一遍之后对里面的一些细节做什么想有一些比较知道的了解,而且你读到这的时候 相对说你比读一篇别人给你,总结好的 一篇博客一篇文章相对来说你能看到的细节更多。
接下来的话,你可以选择说,我继续往下走,继续往下走的话,你可以说我有些东西不是很懂,那么也不是很懂怎么办呢,去看一下他们引用的那些文章,比如说我们说ReLU也好,说SGD也好,他都有相对来说它的引用文献,你可以去引用文献看一下,那里面的技术到底是怎么描述的,然后再回个头来理解它到底是怎么用的。
但是你也可以说,我就不用看了,我大概知道他讲什么东西了,除非我确实要在这一块做研究的话,想了解每个细节的话,我读到这个地方也就差不多了,这也是另外个可能性。
所以我们来这个地方就不给大家讲第三遍了,为什么呢,是因为我们提到的一些,所以我觉得这个东西看上去很麻烦,没有给大家自己想很多说,从现在角度来讲你也不需要知道了。
另外一块的话,当然有一些卷积是怎么工作的,池化层是怎么工作的,大家也不需要去看真正的原始文章, 你随便在网上找一下,大家跟你讲的明明白白,这也是AlexNet读经典文章的时候我们的一个便利,如果是读最新的文章的话,那我们肯定要给大家讲第三遍,把所有的细节给大家讲清楚,不然的话,你去搜还真不一定能搜到这些新的技术是在干什么。
所以我觉得作为研究者来说,读论文绝对是获取信息最好的手段,比你去网上搜看Wikipedia,还是看看blog来的更加好一点,而且里面的东西更加详细一点,这次我们就给大家讲到这里,谢谢大家!