Deep Residual Learning for Image Recognition
基于深度残差学习的图像识别
大家好,今天是我们论文精读系列的第二篇文章,我们选用的是深读学习的另外一篇经典之作——ResNet,这篇文章发表于2015年,但是假设你今天还是在用深度卷积神经网络的话,那么有一半的可能性,你是在用 ResNet或者是他的变种。
那么我们就来仔细读一下提出来ResNet的这篇文章,我们跟之前一样,还是采用两遍或者三遍的读法,我们首先假设自己回到过去,第一次看这篇文章的时候,如何从一个第一人称的视角给大家读一下这篇文章,另外当然我们会回到现在去看一下,论文里面的哪些结论现在看是不是已经过时了还是仍然是成立的。
第一遍
1.标题
首先我们来看一下这篇文章的标题,标题的第一个叫做Deep Residual Learning,这个是 ResNet整个后面的一个核心的思想。第二个是图片识别也就是图片分类,当然是计算机视觉里面最大的一个应用。
2.摘要
接下来,我们来看一下这篇文章的摘要,摘要的第一句话是说深的神经网络非常难以训练,这个就是提出了他的问题,第二句话是说我们干了什么事情,我们做了一个使用残差学习的框架来使得训练非常深的网络比之前容易很多,这个是这个文章关心的重点。接下来他来讲他们提出的方法,他说他把这些层作为一个学习残差函数相对于层输入的一个方法,而不是说跟之前一样的学习unreferenced方式。
当然你在没有看懂这篇文章之前,也不知道他在说什么,反正知道有一个关键词是residual,毕竟这个residual也在标题里面出现了。
接下来说我们提供了非常多的实验的证据,说我们这些残差网络非常容易训练,而且能够得到很好的精度,特别是在当你把层增加了之后,在 ImageNet 这个数据集上,他们使用了152层。
这个层数也是非常夸张的,虽然当时候已经有 GoogLenet应该是在差不多的时候也就出来了,但是他不是用了152层深,就他是有很多并行的一些层。
他是说我有152层的深度,这个是非常厉害的。他说我比VGG还要多了8倍,但是有更低的复杂度。
这个东西比较有意思,就是说我比你深八倍,但是计算复杂度还要更低一点。
然后他说用了这些残差网络做了一个ensemble之后,得到了3.57的测试精度,这个结果让他们赢下了ImageNet2015年的竞赛,然后他们还演示了怎么在CIFAR-10上训练十甚至到一千层的网络。
我觉得这两个结果都比较有意思,第一个结果当然是说我赢下了ImageNet竞赛,我们之上一期讲过AlexNet也就是赢下了应该是第二期还是第三期的ImageNet竞赛,这个就是另外赢下的一个结果,让任何能够获得冠军甚至亚军的一个文章都值得大家关注,特别是那些提出了很不一样的架构、方法的文章,通常是会被大家追捧,所以你看到这句话的话,你通常会选择我要继续往下读一下。
另外一个有意思的是说,在CIFAR-10这是一个非常小的数据集,但是在计算机视觉里面也是最常见的一个数据集,他训练的100-1,000层的网络,这个是非常夸张的,之前你可能都没见过一千层的网络长什么样子。
摘要的第二段话是说,对很多视觉的任务来说,深度是非常重要的,第二句话是说我仅仅就是把我的网络换成了我们之前学习到的残差网络,我们得到了28%的相对改进,在coco这个目标检测数据集上面,然后他也是通过这个东西,他赢下了第一名,在ImageNet的检测,然后localization,然后 coco 的detection,coco 的segmentation上面。
所以这也是一个非常厉害的结果,就是说我就是把你背后的cnn的主干网络替换成了我们提出来的残差网络,我能够在这一系列的任务上都取得了非常好的结果,然后在赢下了竞赛第一名,如果大家做物体检测的话,大家知道 coco应该是这一块最大的也是最有名的数据集了。
3.结论、图表
按照我们的办法,我们接下来要看一下他的结论,比较有意思的是这篇文章是没有结论的,这篇文章发表在CVPR上面,CVPR 是要求每篇文章的正文不能超过8页,这篇文章的结果相对来说是比较多的,因为他毕竟要放上我的ImageNet的实验和我在coco 和目标检测上的一些结果,所以导致作者没有空间去放下他的结论的部分,所以这个也是一个非常不同寻常的写法,我建议大家结论还是要有的,你没有结论,大家会觉得比较奇怪了。
所以没有结论的话,那我们就直接看一下这里面有些公式表格是干什么事情的。
我们首先看一下我们的第一张图: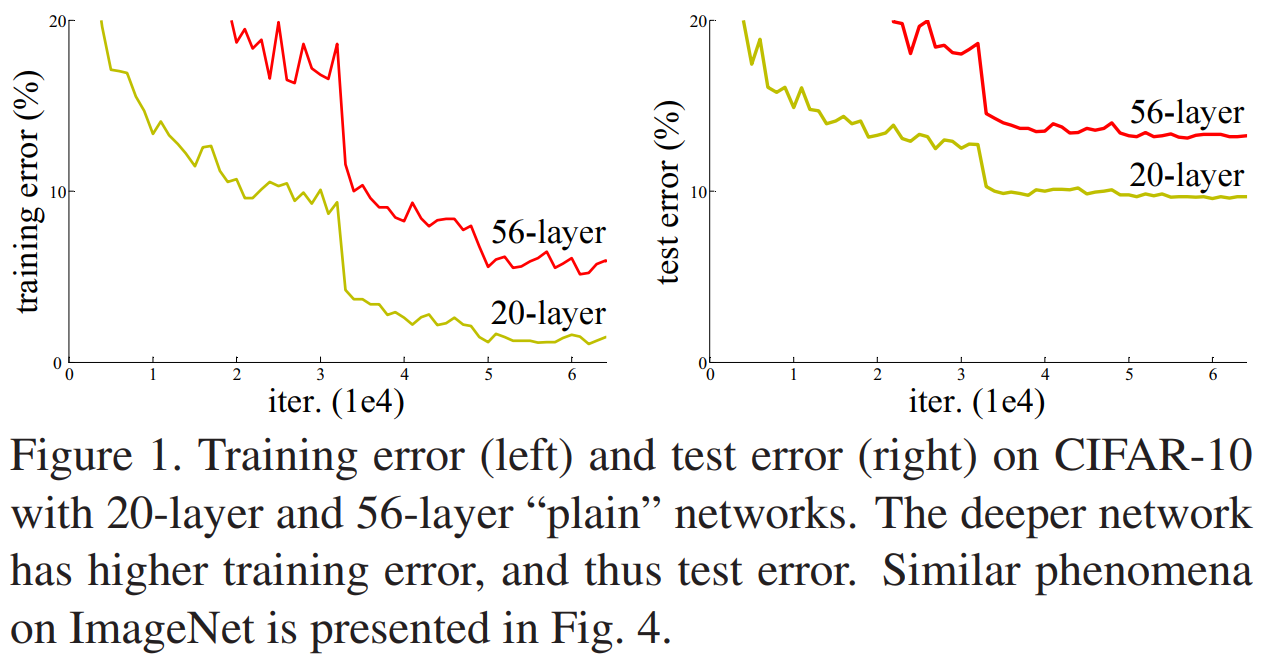
论文的第一张图出现在论文的右上角,这个是计算机视觉论文的惯例,一般我们会在第一页放上一张比较好看的图,不管是我对这个问题的一个描述也好还是我的主要结果也好,越好看越好,所以大家会看计算机视觉的文章的话,第一眼是去看一下他的图是在画什么东西。
当然更有意思的是,如果大家去开计算机图形学的文章的话,他也很有可能把一张图放在你的标题的上面,因为对图形学来说视觉更重要一点,所以他要把最好看的结果放在最上面,据说开创了这个风格的第一人是Randy,他是CMU的一个教授,但是他最著名的事件是他上了最后一课,这一个课非常非常的有名,这是他得了癌症之后,给CMU的同学上的最后一堂课,讲的是他小时候的梦想以及他是如何实现这些梦想的,非常的感人,建议大家一定去读一下,当然我对Randy的印象非常深刻,因为我在CMU的时候,每天路过一座桥,桥是以他的名字命名的,桥他是一个彩虹的颜色,非常的耀眼,每天晚上路过它,就是能在上面会看很久。
图1 CIFAR-10上的训练错误(左)和测试错误(右),20层和56层“普通”网络。更深的网络具有更高的训练误差,从而具有更高的测试误差。ImageNet上的类似现象如图4所示。
我们下面来看一下这张图, 这张图描述的是一个非常有意思的事情,他说我们的左图是我的训练误差,我的右图是我的测试误差,是在 CIFAR—10上的,他说我用了20层和56层的plain network,就是没有加你的残差的时候,你的 x 轴当然是你的轮数,你的 y 轴是你的错误率,可以看到是说,56层就是更深的更大的网络,他的误差率反而更高,他的训练误差更高,他的测试误差也会更高,他用来提出说其实你在训练更深的网络上面大家是训练不动的,不仅仅是过拟合,更多是你的训练误差,他都不能达到很好的效果,所有篇文章的摘要里面第一句话就是说训练很深的神经网络是件很难的事情,这篇论文的主要关心的是说让更深的神经网络更容易的训练,所以这张图是表示的一个观察到的现象、他要解决这个问题。
然后我们来看一下,还有没有别的有意思的图,我们可以往下翻一翻。
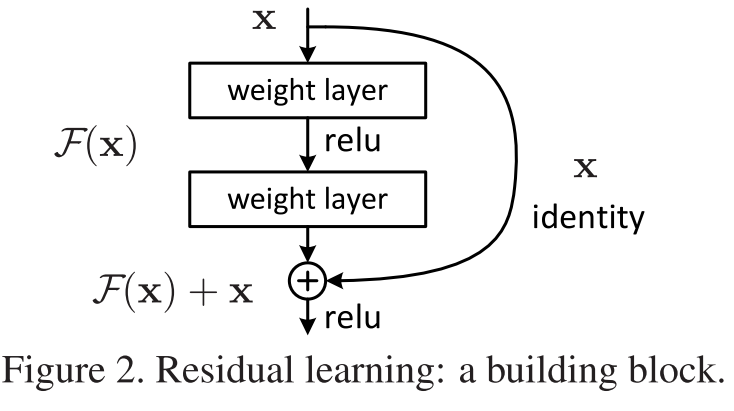
第二张图当然是讲他的一个整个架构的实现,我们可以在等会在讲方法论的时候再给大家看一下这个图。
然后当然你可以往下翻,往下翻的话,可以看到一个特别特别长的一个整个架构的图: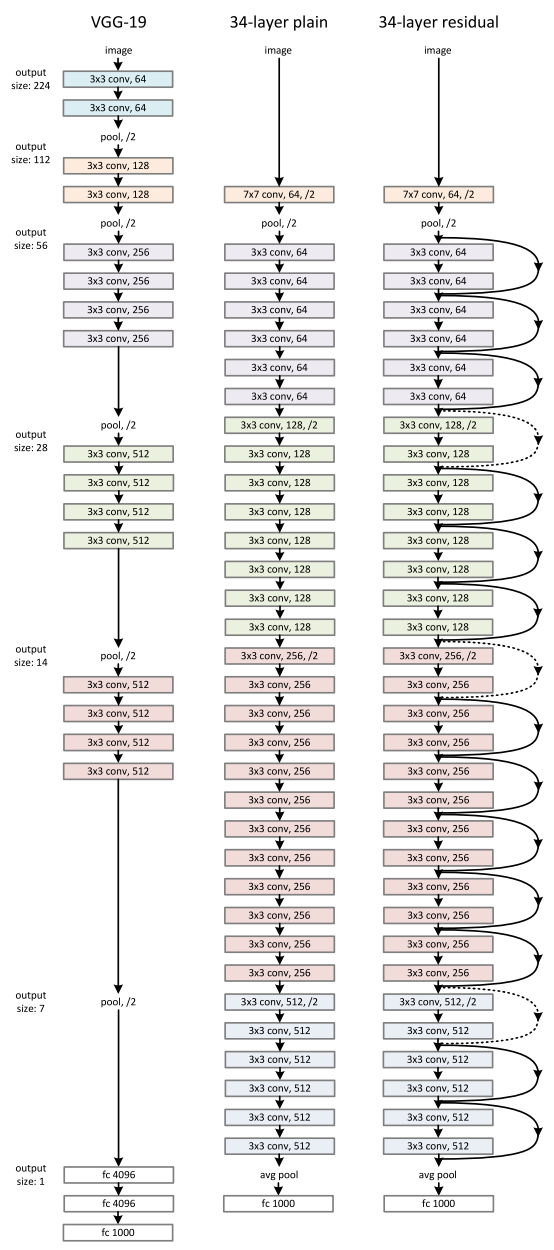
反正对于神经网络来讲,一般来说,我们会把整个网络的架构给你画出来,所以你可以选择去看一眼,如果你对这个架构相关比较少的话,如果你不熟的话之后看也没关系。
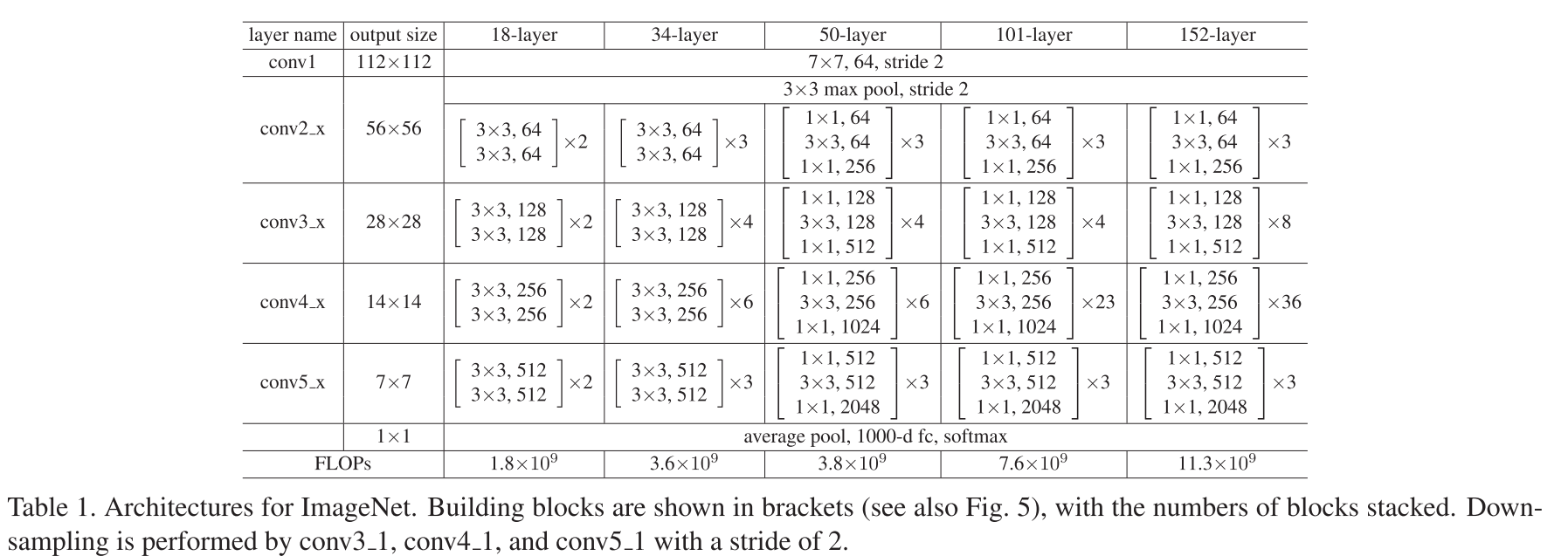
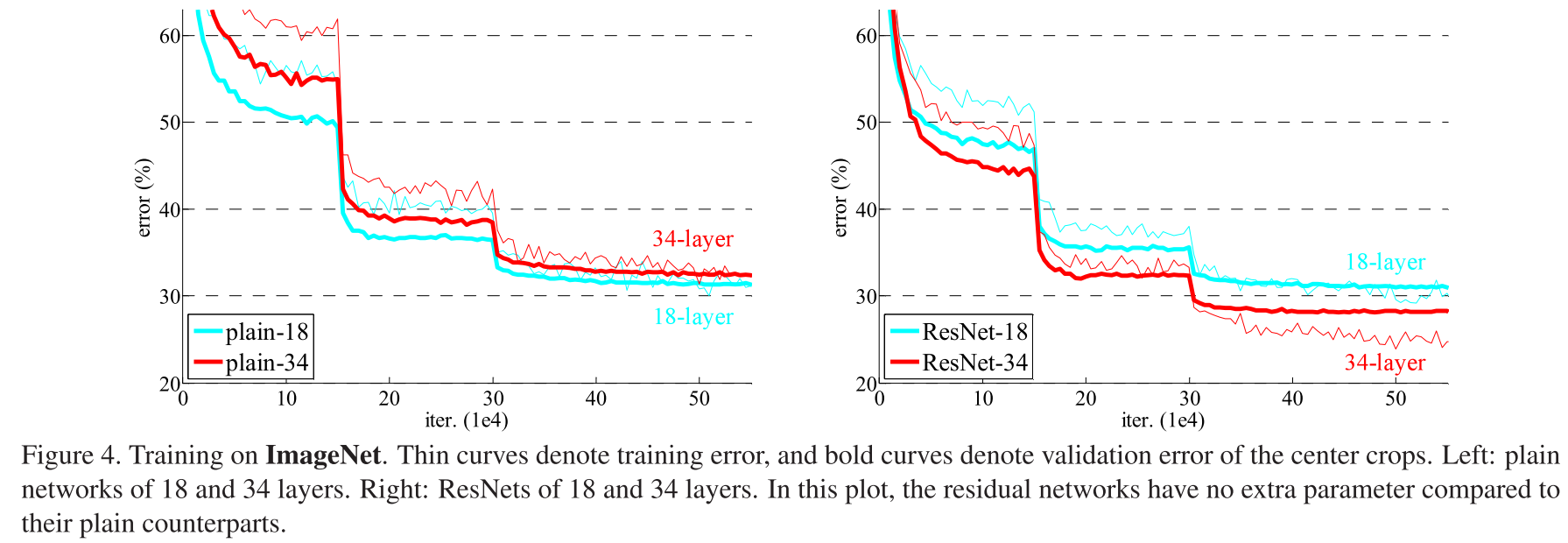
那再往下当就是一些表一些图,图的话可以看一下实验结果,就这个实验结果是跟之前那个图是有一对应关系的,这个是在ImageNet 这个数据集上了,然后这个一样的,还是说没有加残差的时候,用了18层和34层的结果,这个是加了他提出的ResNet的时候,可以看到是说,在你没有加入residual这个残差连接的时候,34层的网络其实比18层的网络在训练误差上其实还高一点,也就是回应了之前的CIFAR的结果。
下面这个图当然是整个论文的核心图了,他说用了我们这个方法之后,使用了34层的结果的误差更低,这个地方应该是粗线是你的测试精度,这个是你的训练精度,所以看到是说,不管是训练精度还是测试精度,在加了之后跟之前没有加的比当然是区别很明显了。
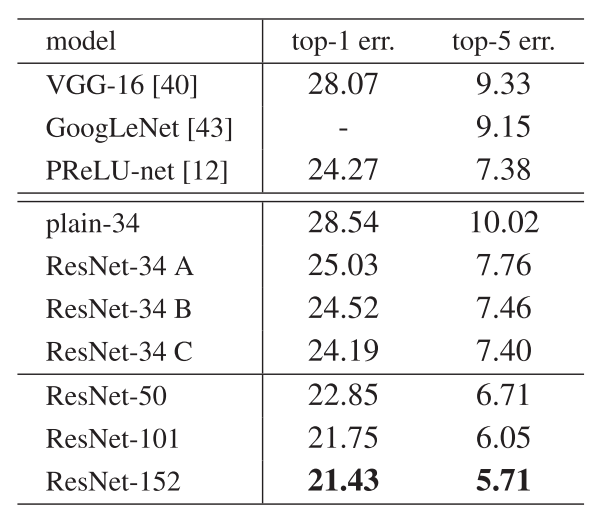
这个是他这个图的一个表的总结, 一般来说,图是给大家一个直观的表示,但是表我们可以把这些数字详细的写出来,这个东西是同样一个东西我用两种东西不同的方式来表达都有各有各的用处,图的话含有的信息更多,但是表的话这些数字对于大家是比较重要的,特别是你后面的引用者要引用一些文章跟你对比的话他可以使用这些数字,可以看到是说34层的ResNet的结果做 top 1的错误率是25.3%,但是如果你没有加的话你是28%,所以这个区别还是会挺大的。

往后面看的话可以看到更多的结果,这个是 ResNet152的结果,再往下的话就是跟一些别的结果的比较,他的152层的结果跟 GoogLenet以及 VGG在上一次竞赛的结果比,可以看到他还是会低的很多,将几乎是7.89降到了4.5,降了30%40的样子也是非常厉害了,然后这个是他赢下了15年比赛,最后的结果可以看到是做到3.57%,而且这个结果基本上是到了人类的极限了。
但后面还有一些在 CIFAR的结果基本上可以跟前面的模式的差不多,主要是说我的效果有多好。
这个就是这篇文章的一个非常简单的介绍,我们在接下来会给大家详详细细的把这篇文章每一段给大家过一遍。
第二遍
在第二遍里面我们就给大家详详细细每一段给大家过一遍ResNet这篇文章,我们之前已经看过摘要和其中的一些结果图了,我们接下来从导言开始。
导言
文章的第一段话当然是讲我这篇文章是关于哪一个领域了,他是说深度卷积深就网络好,为什么好是因为我们可以加很多层,这样子把网络变得特别深,然后不同程度的层他会得到不同的level的一些feature,比如说低级的一些视觉特征和高级的语义的视觉特征。
文章的第二段就提出了一个问题,就是说随着我们的网络越来越深,但是学一个好的网络就是简简单单的就把所有的网络堆在一起就行了吗?如果那么简单的话,那我就把网络做很深就行了,当我们知道这个里面有一个问题是说,当你的网络变得特别深的时候,你的梯度就会出现要么就爆炸要么就消失,解决他的一个办法是说我在我的初始化的时候要做的好一点,就是我权重在随机初始化的时候权重不要太别大也不要特别小。第二个是说我们在中间加入一些normalization,包括了BN就是batch normalization,可以使得校验每个层之间的那些输出和他的梯度的那些均值和方差,相对来说比较深的网络是可以训练的,避免有一些层特别大,有一些层特别小, 然后我们发现使用了这些技术之后是能够训练,就是说你能够收敛,虽然现在你能够收敛了,但是你的另外一个问题是当你的网络变深的时候,你的性能其实是变差的,就是你的精度会变差,这个也是之前这张图给大家讲的事情:
当你的网络从20层变成30、56层的时候其实你的精度不管是训练还是验证或者测试精度都会变差,他说这个东西不是一个因为你的层数变多了然后你的模型变复杂了导致的一个过拟合,就是说他这里写了一段话就是not caused by overfitting,,因为这是为什么,是因为你的训练误差也变高了,overfitting是说你的训练误差变得很低但是你的测试误差变得很高,中间有个比较大的区别,但是现在你观察到的是说你的训练误差和你的测试误差都会变得很差,所以他不是overfitting,所以更大的像说虽然你的网络似乎是收敛,但是好像没有训练得到一个比较好的结果。
第三段就是深入地讲了一下加了更多层之后,其实精度会变差这个事情,他说我考虑一个比较浅一点的网络和他对应的比较深的版本,所谓深的版本就说我在浅的网络里面再多加一些层进去。他说如果你的浅的网络效果还不错的话,你的深的网络是不应该变差的,为什么呢,就是说你深的网络新加的那些层,我总是可以把这些层学的,他就变成一个identity mapping,就是说所谓的identity mapping就是说你的输入是 x,我的输出也是x,就等于是说我可以把一些权重学成,比如说一些简单的 n 分之一,使得你的输入和输出是一一对应的,但实际情况下是说,虽然理论上你的权重是可以学成这个样子,但实际上你做不到,就是说假设我就让SGD去优化的话,虽然这里存在一个比较好的解法,就是下面那些层学到一个跟那些比较shallow的网络那个精度比较好的网络一样的结果,但是上面那些层就是变成identity,举例到前面那个例子就是说,我20层的网络权重跟他一样,后面接加的那14层全部变成了一些identity mapping,所以如果你这样子,那就不应该精度会变差,跟之前是一样的,但是实际上他发现说你SGD他找不到这个事情,他unable to find,就是说虽然存在一个这样看上去比较优的解,但是你 SGD 找不出来,那么你怎么办,这篇文章呢就是提出了一个办法使得你显示的构造出一个identity mapping,使得你深的网络不会变得比你浅的网络更差,所以他把这个东西叫做deep residual learning framework,他这一段就详细的解释了一下,他是在干什么事情,我们来看一眼,首先他说我要学的东西叫做h(x),那假设我现在已经有了一个浅的网络了,我换一个框在这个地方,他的输出是一个叫做 x 的东西,然后我要在上面再新加一些层,比如说我要新加上一些新的层在上面让他变得更深,之前说我新加的层那我就继续跟之前一样的学习就行了,他说我新加那些层我不要直接去学 h(x),而是应该去学h(x) - x,就是说x是之前比较浅的网络已经学到的那个东西,但是原始的数据进来我们就叫做什么东西都行,叫做z也行,叫做图片也行,首先进来就是说以前我已经学到了 x 表的表示是 x,我新加的层的话我就不要去重新学个东西,我只是到的东西和真实的东可能是你的标号也行什么也行,他们之间的那个残差,我让这个层去学这个东西,所以最后的结果是说整个东西的输出是他的输出再加上 x,等价是这个东西,假设说你的红色的东西学的东西是 F(x)的话,那么再加上浅的网络的输出 x,那么就作为整个的输出,那么他的优化的目标呢就不再是你原始的 h(x),而是 h(x)减去 x 就这个东西,这个其实说白了就是他的核心的思想。
然后我们来看一下就是说到之前这张图是干什么事情,这张图就讲了这个东西是干什么事情的,就他当然是说他的这个东西是在上面,就他的浅的网络是在这个地方,浅的网络输出的是 x,这两个假设是我新加的东西的情况下,那么他的 x 进来,进入他的一个层,进来一个relu一个激活层,再进到一个新的层,他的结果是继承 f(x),那么他最后的输出是x直接过来加上 F(x) ,这个加号的这个事情,再做一个激活层relu做为新的输出。
所以他跟之前的直接加的唯一的区别就是加了这个东西identity,加了一条这样子的路, 这个东西是做一个加法,等于是你的输出不再是你自己的输出,还是说你的输出加上了你的输入,这个东西叫做 residual。
然后我们接下来会来讲说到底为什么在做residual这个事情,核心思想就是这个东西就是在神经网络要实现的话,可以通过一个叫做 shortcut connections的东西,当你数学上实现就是加一下对吧,然后你在神经网络上画的话就是多画一条线过来,这个东西不是很新叫shortcut,其实他给了几个文献,那个文献你可以去看一下,都是90年代很早很早以前就上一次神经网络时代大家早就提出过了,大家肯定是用过这个东西了,所以这个东西他其实做的是一个identity mapping,然后他说这个东西好,为什么呢,因为我就是加一个东西进来,他没有任何可以学的参数就是说我不会增加任何你要学的参数,就不会增加你的模型复杂度,也不会让你的计算变高,因为我就是一个加法而已,而且他整个网络是仍然是可以被训练的,就跟之前的东西是没有改变的,我只是在整个实现里面加了一点点东西而已,比如说他那个年代15年的时候,大家还是用Caffe用的多一点,在Caffe里面,你可以不用改他的代码直接可以实现,所以这个两段呢主要就是讲的是他提出的方法以及稍微告诉你说到底residual 在干什么事情。
接下来在introduction里面,他还说我们接下做些实验,我的非常深的residual nets非常容易去优化,但是如果不加这个残差连接的话, 他的plain的版本就是效果会很差了。第二个是说他们深的网络可以得到你越深你的精度就越高,这样子他们就赢下了比赛。然后他在摘要里面有说过 CIFAR的结果,他在这里再强调一遍说我把这个结果放在CIFAR上我能train到1000层的东西,最后当然是讲了一下我的 ImageNet上的结果,怎么样赢下了第一名。
所以这个基本上他导论,可以认为是他摘要的一个增强版本,在结果上我说的东西更多一点,然后主要是解释了residual那个东西在干什么事情,就我解决一个什么问题,然后他的问题是什么,然后我的一些猜想,然后我具体来说我整个东西设计是什么样子的,然后给大家一个简单的一个思想,然后你读到这里的话,你大概就知道了他的核心的设计,你甚至就可以不用往下读了,你都再就知道这篇文章的核心精髓在讲什么东西了, 当然你还没有看到ResNet是怎么设计的,但是你知道他的核心就是这个residual connection,然后用了它之后效果很好,如果你不是在做这一块的话,很多时候,你就可以停在这个地方了,这也是这篇文章我觉得写的比较好的,比较标准的一个地方,就是 intro 是你的摘要的一个比较扩充的版本,也是一个比较完整的对整个工作的一个描述。
相关工作
接下来我们来看第二章,第二章一般来说就是相关的工作了。Residual Representations,就说因为我毕竟是用的 residual,他说了在计算机视觉里面是怎么做这个事情的。
residudal 这个词其实在机器学习或统计里面用的更多一点,大家知道其实线性模型最早的解法就是不断的靠residual 来迭代的,然后另外一个在机器学习里面比较有名的叫说gradient boosting,他其实就是不断的去通过残差来学习一个网络,然后把一些弱的分类器把它叠加起来变成一个强的分类器,在20年前是曾经是也是非常火的,但是这个地方他没有去回顾这一块也能理解,这是计算机视觉的,我们发在 CVPR上面,所以他确实没有太多去考虑机器学习在干的事情。
另外一个是说他的Shortcut Connection这个东西其实在之前也用的比较多,比如说叫做highway networks,然后这些东西他说之前其实用过的比较多,当然之前的工作相对来说比较复杂一点,他那个connection相对来说fancy一点,他在这个地方就是一个加法,就是最简单的一个做法。
所以看到这里的话,大家其实觉得你会发现ResNet他不是第一个提出residual,或者说shortcut这种原创的文章,很多时候你看任何文章、任何经典的文章,你会发现它里面的技术不一定是原创的,你看Alexnet它里面的dropout的也好,很多别的东西也好,那些神经网络你也没有觉得他特别是原创的,但是一篇文章之所以成为经典,不见得他一定要原创性的提出了什么什么东西,他很有可能是说我把之前的一些东西然后很巧妙的放在一起能解决一个现在大家关心的比较难的问题,所以一样的能够出圈能够出名,然后大家觉得你是经典工作,然后甚至大家都不记得之前谁谁谁做过,所以对于研究者来讲也是一个好事情,就是说你会发现任何的想法呀,你随便想个什么东西,前面有那么多聪明的人基本上就把你的东西已经想过了写过文章了,你写任何一个说我做了一个什么什么东西,很有可能你会发现前面有人做过了,很多事没关系,就是说你就在文字面写清楚我前面前面谁谁谁做过了,现在我们有跟他们有什么不一样地方,比如说用同一个东西解决了一个新的问题,或者是说你反正新的问题你可能考虑上跟总会有一点点细微的区别,另外一块有可能是说你的文章太久远了,就是说可能别人一些工作30年前、40年前发表了,他的工作可能也没什么引用,就几个引用,你可能没有找到的文章,所以说你在论文里面说我提出了什么东西我觉得我是第一个,在作者来说,一般会说to our best knowledge,其实说我们真的是搜过了没有找到,所以我觉得我可能是第一个做这个事情的,但很有可能别人发现你不是的,那没关系,如果你确实很久远的文章找不到的话,对于一个review来讲,或者是你一个读者来讲,发现其实也没有太多问题,可以善意的告诉他说你这个工作很有意思,但是我这里有一个相关工作,你可以看一下就是跟你的idea有点像,就你提醒他一下,他可能会下一个版本会把它加上就行了,但也没必要特别愤怒是说你一定抄袭了什么东西,当然抄袭的是说你一个最近的工作跟他长得真的差不多,然后你也没引他,甚至你可能看上去你跟他的东西可能你在写的时候你其实看过,但是没引他当然是有问题的,所以我觉得这一块大家在对待技术的原创性来讲,其实要一个稍微客观一点,也是稍微容忍一点的态度,因为而且对于研究者来讲,你也不要觉得说什么东西都被做过了,那我没什么东西做可做了,其实也不是这样子的,你去看一下基本上深度学习的经典文章,你往前走20年前,基本上那些idea也都被用过了,只是现在可能问题还是同一个问题,但是我的数据量更大,我的计算能力更强,也是新的挑战后过来,旧的技术但是有新的应用有新的意义,也是一个非常重要的事情。
接下来我们看一下残差连接如何处理你的输入和输出的形状是不同的情况,这里他提供了两个方案,第一个方案是说他在输入和输出上分别添加一些额外的零,使的这两个的形状能够对应起来,然后可以做相加。第二个是之前提到过全连接怎么做投影,当然如果你做到卷积上的时候,他是通过一个叫做1x1的卷积层,这个解决层的特点是他在空间维度上不做任何的东西,但是主要是在通道维度上做改变,所以他只要选取一个1乘1的卷积,使得你的输出通道是你的输入通道的两倍,这样子他就能够把你的残差连接的输入和输出跟你对比上了。另外一个是说,我们知道ResNet里面,如果我们把一个输出通道数翻了两倍,那么你的输入的高和宽通常都会被减半,那这个地方,所以你在做这个1x1的卷积的时候,你也同样会用一个步幅为2,使得你这样做出来的话在高宽和通道上都能够匹配上。
然后我们看一下实验,讲了一些他实验的一些细节,他说我们用了一些正常的practice说,他把短边随机的采样到256和480。
这个跟我们之前的AlexNet有一点不一样,AlexNet就直接把短边放到256,这个地方是随机的放这个地方。
随机放到比较大的地方的好处就是你在做随机的那个切割的时候,切成224乘224的时候,你的好处是你的随机性会更多一点。另外一个说他把每一个pixel的均值都减掉了里面他用了一些颜色的增强。
在AlexNet 里面,我们用的是 PCA做一个颜色增强(PCA Color Augmentation),现在其实用的比较简单了,就是 rgb 上的,把亮度、饱和度各种地方调一调就行了,觉得photoshop能干的事他都能干。
另外, 他当然用了 batch normalization, 然后另外一个是说, 他说我的所有的权重啊全部是跟, 13这个 paper 里面用的是一样的, 这个其实当然是说, 你可以这么写了, 这样子的话你可以省下很多空间, 但是对读者来讲就比较尴尬了, 就是说我如果没有读过你这个论文, 我怎么去知道我还得去读你的论文, 实际上论文是13其实是, 这些作者之前的一篇文章, 他自己写的就很方便, 因为是前面这篇文章是我的, 所以我就已经说, 我们跟前面那篇文章是一样, 但实际上来说 对读者这个不是很好, 所以如果大家要写论文的话, 尽量能够, 使得别人能够不要去看里面的文献, 能够了解到你在做什么, 如果让别人去点开这个文献, 然后再去搜一下的话, 其实是不那么方便的, 另外一个是他用的, 批量大小是256, 学习率是0.1, 然后呢每一次除10, 为什么时候除10呢 当你的错误率啊, 比较平的时候他就会除10, 这个也是 AlexNet 用的方法啊, 我们之前提到过, 我们现在也不怎么用了, 因为这个东西你得守着啊, 你不守着你是谁知道什么是应该除10, 他说我的模型训练了, 60乘以10的四次方次 一个小批量 , 这个写法我有点奇怪, 我不知道这个10的4次方, 为什么有这个东西出现啊, 我的建议是说, 大家最好不要写这种iterations(迭代次数), 为什么 是因为, 这个东西跟你的批量大小是相关的, 如果我变了一个批量大小, 那你这个东西就会变了对吧, 所以现在很多人一般会写, 我迭代了多少遍数据 , 相对来说稳定一点, 另外说, 他用了一个weight decay0.0001, 然后 momentum 0.9 都是标准的, 另外一个是说他没有用 dropout, 这是因为我没有全连接层了, 所以 dropout, 在这个地方没有太多用, 在测试的时候呢, 他用了, 标准的, 10个 crop testing, 就是你给到测试图片, 我会在里面随机的, 或者是有按照一定规则的, 去采样10个图片出来, 然后在每个子图上做预测, 就会把这个结果做平均, 这样的好处就是说, 因为你的训练的时候, 你每次是随机把图片出来, 我在测试的时候也大概模拟这个东西, 另外我做, 10次预测的话, 当然是能够降低我的一些方差了, 然后他说最后是我们把这些, 而且他是做了很多个, 分辨率啊就是在不同的分辨率上, 然后去做采样, 这样子你相对来说在测试的时候, 你做工作还是挺多的啊, 你又做了, 不同的 crop, 又做了不同的分辨率, 当然是说你要刷榜的话, 这个是很常见的一个办法, 但是在实际上我们用的比较少, 因为这个这样的话你的测试就太贵了, 一般来说, 我们不会为了那么一点点精度, 把自己的线上的性能搞的, 特别糟糕, 因为毕竟是要掏钱的 好, 这个就是我们整个模型这一块的实现, 接下来第四章讲的是实验, 实验包括来说我怎么去评估 ImagNet, 以及我的各个不同版本的ResNet, 是怎么设计的, 第一段讲的是ImageNet是怎么回事, 他这个是很标准的东西我们就不讲了, 第二个是说 他比的是一个, 没有带残差的时候, 他使用了一个18层和34层, 34层我们之前已经讲过, 就刚刚那个图, 就这个角落那个图我们已经讲过了, 我们可以看一下18层是在干什么, 这里有时候是说他在表1里面有把, 细节的架构给大家讲了, 我们来看一下表1是怎么回事啊, 表1是这一张比较大的表, 也就是大家经常截图用的一张表啊, 就是整个 ResNet不同架构之间的, 构成是什么样子的, 我们来看一下, 首先看到啊我们, 这个地方有不同的版本啊, ResNet 18, ResNet 34、50、101然后152, 这里一共有5个版本, 然后五个版本呢 他们的第一个, 就是第一个卷积 就77, 这个卷积当然是一样的, 接下来呢 那个pooling层也是一样的, 当最后那个全连接层带是一样的, 就是啊, 最后一个全局的pooling, 然后再加一个1,000的全连接层做输出, 他的不同架构之间呢, 主要是中间不一样, 也就是那些复制的那些, 卷积层是有不一样的, 我们首先看一下34, 啊我们之前已经看过了, 这个东西表示的是一个, 残差块里面的东西, 块里面我们知道是有两个卷积层, 他用的是, 第一个模块 这个是conv2、3、4、5, 加上的讲的是四个模块, 我们之前数过的, x 就表示里面其实有很多个不同的层, 就很多个不同的块吧, 然后呢, 第一个块里面 他的组成是33, 然后通道数是64, 然后他有三个这样子的块, 如果回到前面看的话, 他对应的其就是这里对吧, 他有一个块两个块三个块, 每个块里面是这样子, 然后块之间他是通过一个, 残差连接来连接, 好的, 所以这个地方表示的是, 第一个块, 接下来是第二个块第二个块就是, 通道数是128, 这个都是一样的3乘3都是一样的, 但是通道数是64, 128,256,512, 然后中间就是说你复制多少次, 他复制的是3, 4 6 3, 统计下来那就是34层, 我们看一下为什么34层就是, 3加4加6是16, 然后以每个里面是2就是32, 再加上第一个加上最后一个, 那就是一共是34层, 18层呢, 18层跟34层其实是一样的, 主要是把这个东西变了, 他把所有这个数字啊全部变成了2, 222所以就说这一块一共是, 8乘以2一十六, 然后再加上第一个卷积层, 最后一个全连接层那就是18, 所以就是这么算出来的, 所以, 为什么你这个东西取成这个样子呢, 这也是比较好玩的, 现在论文里面, 并没有讲你为什么取成这个样子, 啊这就是超参数了是作者调出来的, 实际上来说你这些参数啊, 你可以通过一些, 网络架构的自动选取啊, 在之后的工作 有 大家有去调说, 具体你这个东西选成什么样子, 其实是可以调的, 接下来还有三个模块啊我们等会再讲 , 因为它里面有一点点不一样的地方, 他一个残差块里面是有三个层啊, 还不是之前的两个层, 我们之前之后碰到的时候再回来讲他, 好最后看一下就是你的FLOPs, 就是, 你整个网络要计算多少个浮点数运算, 这个东西是可以算出来的, 就是说卷积层的浮点运算就是等价于, 输出的高 乘以 他的宽, 乘以通道数乘以输出通道数, 再乘以你的, 和的窗口的高和宽就是一乘, 然后你在, 全连接再一层就 , 基本上就可以算出来了, 可以看到是说, 18-34基本上是翻了一倍啊, 1:8-3.6, 但是50的话其实没有比, 34高多少, 你看到就是说他做了一些别的架构, 使得, 50的时候并没有像前面样的翻倍, 而是说差不多, 之后 当然之后是翻倍的关系啊, 但是在这个地方是有一点特殊的架构, 啊我们之后再来讲, 好接下来他说他的结果, 在表2对比的18和34层, 啊有残差连接还没有残差连接的结果, 然后他的图四呢也啊, 可视化这个结果我们之前其实有讲过, 给大家再给大家重新看一下, 重新看一下就是说, 红色的线表示的是粗, 粗的那一根线表的是34的, 他的验证精度或测试精度也行, 你怎么说, 然后这个东西表示的是他的训练精度, 首先有意思的是说你的训练精度其实, 比你的测试精度要高的, 在一开始啊为什么呢, 是因为你在, 训练的时候用了大量的数据增强, 使得你的训练误差相对是比较大的, 然后你在测试的时候, 你没有做数据增强, 你的噪音比较低, 所以一开始当然是会低的, 然后他这里这个东西是干嘛的, 这个东西是你的学习率的下降, 就这个这个地方你学习率乘了0.1, 每一次乘了0.1就说本来收, 本来是SGD就是一个, 慢慢的慢慢的收敛呢突然乘了0.1, 然后整个他的步伐改变了, 就打乱了他的步子, 然后他就趴 跳到另外一个地方, 跳到另外一个地方呢, 你可以看到是, 对整个他的下降比较明显, 他这个地方是跳了两次啊, 基本上跳了两次的样子, 最后这个地方是没有跳了啊, 所以就说为什么大家也不再喜欢用啊, 乘0.1 乘0.1, 这种做法, 就是说你在什么地方跳, 其实是很尴尬, 就你在这个地方, 你说我在这个地方已经平了吧, 你为什么不在这个地方跳, 而且在后面跳, 实际上来说你不应该跳太早, 在这个地方呢你跳太早的话, 会后期收敛会无力, 就是说你最好, 其实你这个地方你还可以再往前, 训练一点, 再跳, 就是说虽然你看上去 他的没有, 做什么事情啊, 实际上他在里边做很多的微调, 但是做些微小的跳动, 但是你在, 这个地方这个宏观的数据上看不出来, 所以其实你多训练训练, 在晚一点跳其实是一个不错的选择啊, 晚一点跳的话, 你一开始就是找到方向更准一点, 到后面其实对你的后期是比较好的, 就跟你练内功一样的, 你先积累积累然后再突破对吧, 然后他主要, 其实这个图主要想说明的是说, 你这一块是没有残差连接的, 这一块是有残差连接的, 有残差连接, 当然是说, 你34的时候他会比18要好, 另外一个是说, 他的34跟这个34, 当然是会 有残差连接会好很多, 另外一个他讲到的一个事情是说, 如果有了残差连接的话呢, 他的收敛啊会快很多, 你可以比一下这个, 34和这个34, 他的收敛在这个地方你看这个地方, 大概是15乘1的4四次方的叠带的时候呢, 还在这个地方, 这个地方已经掉的很低了, 因为他的 y 轴是对应上的, 所以说他的核心思想是说, 在所有的超参数都一定的情况下, 有残差的连接收敛会快, 而且后期会好, 但你可以看到这个表啊, 就是讲的是, 最后对比说, 绝对数值上来说最后的数值啊, ResNet当然是比没有加残差的会好很多, 我们讲完这个就可以跳过一大段的实验的介绍啊, 通常论文上来说他会, 虽然你的实验结果都在你的图里面 表里面, 但是他也会在文字上重新解释一遍, 啊生怕你看不懂, 当然你能看懂的话, 你其实你也可以大量的跳过他的文字, 接下来看一下就是说他比较了不同的, 就是在你的输入输出不一样的时候, 形状然后怎么样做残差连接, 他之前有讲过两种方法啊 一个是填零, 一个是做投影, 第三个就是说, 他所有的连接都做投影, 意思是说, 就算你的输入和输出, 他的形状是一样的, 我一样的可以在那个连接的时候, 做一个11的卷积, 但是输入和输出通道数是一样, 然后做一次投影, 他对比呢这三个方案, 表3呢那, 表示的是这三个方案不同的结果啊, 就 abc 然后, 同样都是34层的 resnet, 这个是 top 1, top 1和 top5 具体是说, 你要看哪个都无所谓, 基本上你, top 1比较好的 top 5也比较好, 所以其实都没关系, 你就随便看一个都可以, 可以看到, 是说啊 top 1的时候你的 a, 就是你填0, 啊 b 就是你在不同的时候做投影, c 就是全部做投影, 基本就是说, 可以看到 b 和 c 都差不多啊, 但是他比 a 还是好一些的, 然后啊作者说我尽量不想用 c, 用 c 感觉跟他虽然好一点, 但是呢他的坏处是说, 因为你这个投影啊他相对是比较贵的, 然后给他带来了大量的计算复杂度, 所以就是说划不来, 他觉得但是 b 还不错啊 b, 他对计算, 量的增加是不多, 也毕竟你就有四次好像是会改变吧, 然后你假设, 150层的话也就4次会要做投影, 所以呢但是他结果会好一点, 所以他之后都是用的这一种方案, 也就是现在我们所谓的 resnet, 都是用的, 当你的输入输出改变的时候, 我们会用11的卷积做一次投影, 好 讲完这个之后接下来就是说, 怎么样构建更深的 resnet, 我们到现在为止, 他只讲的是 resnet34, 但是我们知道 resnet可以到50, 甚至到1,000怎么办啊, 所以他这个地方讲的是说, 我要做, 到50或者50以上的层的时候呢, 他会引入一个叫做, bottleneck的design, 就是一个瓶颈的design, 就我们具体来看一下前面这个图啊, 就他想干什么, 就是说这个是我们之前的设计, 之前呢, 是说当你的通道数是64位的时候, 他进到一个33 33, 然后都是64啊最后做加法, 但是说你通道数是不变的情况下, 他说如果你要做到比较深的时候呢, 你这个维度啊, 就比较大一点, 就是当你很深的时候, 我可以学到更多的模式, 也就是说 我可以把通道数变得更大, 这个地方, 你是从64变成了256, 当你变得更大的时候会什么问题, 因为你的计算复杂度是, 你这里乘了几啊, 乘了4, 如果你再乘4的话, 他的计算复杂都是增加16倍, 也是平方关系, 所以他就划不来了, 他说这个样太贵了, 那怎么做呢, 他的做法是说, 他虽然你这个地方是256, 但我通过一个11的卷积把他映射, 投影回到64位, 就跟他这样子是一样, 然后再做33的, 通道数不变的一个卷积, 就等价于说, 这一个操作跟这个操作是一样的, 然后再投影回256, 为什么要投影回去, 是因为你的输入的通道数是256, 所以你输出要匹配上, 所以你再投影回去等价于是说, 你先把一个等于降一次维啊, 我们这个256, 等价于是他的特征维度, 我们先对特征维度降一次维, 在降一次维的上面, 再做一个空间上的一个东西, 然后再投影回去, 这是 bottleneck的设计是怎么样的, 是怎么做的, 那他说啊虽然, 我这个地方你的通道数是之前的4倍, 但我一旦这么设置之后, 啊, 这两个东西的算法复杂都是差不多的, 就说这一块和这一块的复杂度差不多, 然后再回到我们看之前的那个表一, 我们提到过的表一, 这样子我就能看懂这个50 100 152的设计了, 基本上可以看到是说, 这个就是之前我们提到的, 东西的设计就是, 你过来之后我们先投影, 然后在这个地方再回去, 然后你看这个地方, 这个地方的输出是256, 但是到下一个的时候, 他投影回128, 然后投影然后再投影回512, 然后他的因为这一层的4啊, 所以导致说他的下一个 block 就是, 512投影回128然后投影回去, 当然你可以看到基本上不管你是啊, 层数从50 101 152, 他的基本上差不多啊, 这一块这一块这一块差不多对吧, 都是一样的, 这个这个这个都是一样, 就是说虽然你的东西不一样啊, 就是你的层数不一样, 但是里面这个设计我都是一样的, 唯一的是说, 你看到这个东西的变化的, 后面我们做的一个2048, 因为我做的是比较深啊, 比较深的话, 我可以去里面抓取更多的信息, 这样子用一个, 等于是我用一个, 2048的向量来表示我的图片, 之前用的是一个512的图片, 然后 50的时候跟34呢 , 他这个地方是一样的, 就这一块是一样的, 所以34-50主要是加入了一个, bottleneck的设计, 然后呢 这里面通道数发生变化, 但是这个地方是一样的, 因为你这个地方从2变成了3, 所以呢他从34层变成了50层, 基本上通道数, 是从64变成256, 128变成512, 512变成2048, 通道数基本上翻了四倍, 但是因为你这个 bottleneck 设计, 我的flops 数, 就是计算复杂度是差不多的, 所以导致说, 你看一下 resnet34和 resnet 50呢, 在复杂度上增加是不大的, 当然这个是理论的复杂度, 在实际跑情况下这个东西会贵一些, 因为这是理论复杂, 因为他的这些东西啊, 1乘1的卷积啊, 在计算的有效性上确实没有别的卷积高, 导致了他是说, 在实际上来说, 50还是比34要贵了不少, 110的话那么主要的就是, 你看到就是把, 6变成了23, 别的都没变, 然后152的话就是4变成了8, 23变成36, 还是这个问题, 具体你为什么要这么设计, 我觉得是, 作者可能是在做实验的时候啊, 调了一些参, 然后最后调了一个还不错的结果, 但是当然也, ResNet 的计算量那么大, 也不支撑大家说做一个特别, 大的一个搜索, 那现在我们的计算资源够了, 我们现在可以更有能力去搜索它的结构, 所以啊 现在很多时候各种 resnet 的改版啊, 大家会在这个上面慢慢的调的更好一点, 这样我们就基本上讲了, resnet 整个的架构是什么样子, 最后看一下结果, 结果我们之前大概其实也讲了, 就是当你更深的时候呢, 你会发现你的精度或者你的错误率啊 会依次下降, 从21.84一直降到了19.38, 这个东西还是挺明显的, 然后他就说我跟别的算法比, 就是我们赢下比赛的那个是3.57啊, 这个地方为什么比这个地方低那么多, 是因为啊, 他做了大量的这样子的random crop , 最后做了融合, 所以导致效果要好一点, 他跟别人比还是很明显啊, 就3.57啊你看, 这个是别人的工作都是要低的1.6个点, 1.6个点已经挺厉害了啊, 你们想想就3.57啊, 你再往下还能够降两个1.6就基本上到顶了, 而且你是到不了底的, 因为ImageNet他的标号的错误率本来就挺高的, 估计有个1%估计是有的, 所以呢 你不应该到底, 这个就是基本上就是在ImageNet上的结果, 以及ResNet各个版本, 他到底长什么样子, 之前有说过他其实还做了一些实验, 就是说在CIFAR上面的实验, CIFAR是一个很小的数据集啊, 他之所以做这个就是跑起来容易吧, 就给大家看一下里面到底发生了什么事情, 我就不给大家特别讲CIFAR这个东西设计什么样子的, 他就是说啊 我又在CIFAR上面, CIFAR上面的ResNet和ImageNet上面的ResNet是不一样的, 因为 CIFAR它整个图片就很小, 它是一个32乘32的图片, ImageNet就是基本上300乘300以上, 所以呢 在设计上会有一点点不一样, 其实更加简单一点了, 他说啊 他主要的一个事情是说, 我在 CIFAR上面啊, 设计那么多, 然后他最后设计出了一个, 1,202层的东西, 他的参数当然不大了, 因为你的输入输出, 就输入的高宽本来就很小, 所以你当然是没ImageNet的那么大, 但是呢 比较有意思的是说, 虽然那么简单一个数据集啊, CIFAR就是一个也就5万个, 应该是5万个样本吧, 十类的数据集, 看到是说你, 即使是在往下加你的这个地方, 基本上在101层的时候还是有个, 往下降的趋势, 当然是 最后你大概是1,000多层的时候是会往上升, 但是也还好啊, 他也没说升的特别离谱, 就是说你的, 虽然这个地方你可以看到有一点点的overfitting, 但是也不那么严重, 然后这下面一张图啊也是 CIFAR上, 跟之前其实ImageNet是图差不多了的, 就是讲一个道理, 就是你假如 什么都不加入residual的话, 那么你的56层当时比20层的, 精度要差一些, 你加了之后就是跟之前是差不多效果啊, 另外一个是说, 他主要想说的一个东西, 其实想说啊, 在整个 residual connection就是残差连接, 你要干什么事情呢, 就说在你的后面那些层啊, 新加上的层, 他说如果, 你的新加上的层啊, 不能让你的模型变好的时候, 那么呢 因为有残差连接的存在, 所以新加那些层应该是不会学到任何东西, 应该都是靠近0了, 这样子导致说等价于是说, 我就算是训练了1,000层的 ResNet, 但是呢 可能就前100层有用, 后面的900层就, 基本上因为没有什么东西可以学的, 他基本就不会动了, 所以他想讲的是这个道理, 然后他这个地方画的是说, 看一下那些最后那些层啊, 真的是在有没有用, 就是如果你没有学到东西, 那么最后那些层的他就不加输入的时候, 那些层的输出呢, 基本上是意味着0是吧, 所以他就是看了一下说, 最后那些层啊 你可以看到, 后面那些层对吧, 这是100层啊, 然后, 就看到是说如果你没有加残差的话, 其实还是大家还是比较大的, 如果你加的话大家就是, 比较小一点的, 所以他其实想说的是这个道理, 但是呢这个东西啊, 你就看一看吧, 为什么是因为, 虽然你没有加残差和加了残差, 你用的是同样的超参数, 在训练的时候同样超参数, 但是这是两个完全不一样的模型, 就加那么一点点, 就对这个模型的改变是很大的, 所以导致同样的训练超参数, 我觉得在, 没有加的时候其实收敛是不对的, 所以导致的这个东西根本就是, 没有收敛好的, 就说啊没有训练好的一个状态, 所以你在比他的话其实也很难比较, 我们有讲过啊 这篇文章他没有结论, 没有结论是因为最后这一段, 这个地方应该是用来画结论的东西, 他把它加上了一个目标检测的结果, 他说我们的结果在目标检测数据集上结果很好, 然后他的结果呢, 在这个地方就是你可以看一下啊, 就是啊 mAP就是在目标检测上最常见的一个精度的, 就是那个锚框的平均那个精度的一个东西, 然后 他是在不同的阈值下面 , 可以看到是说 跟之前比他是, 他这个东西啊 越高越好啊, 所以他是从21.2增加到了27.2, 这个东西是从70.4增加到了73.8, 然后 就是说因为他讲的这句话呀, 因为他说 details在appendix 里面, 所以你就往下看啊, 所以因为加了这个东西啊 , 所以他把结论啊讨论啊这东西都去掉了啊, 其实从我的角度来讲啊, 其实你这篇文章已经那么那么厉害了, 就前面的结果真的是啊, 很很吓人的情况下, 不写这个东西其实没关系, 甚至你可把这个东西放到下一篇文章, 写都没关系啊 你把这个东西一塞啊, 然后你就说, 后面是两页的appendix, 讲的是我这个东西是怎么做的, 我觉得这个东西啊没什么太多必要, 就是说, 我觉得一篇文章不要放太多的结果, 导致大家读起来比较难, 然后你, 这些结果其实是一个锦上添花的效果, 我觉得, 你就算不放这个结果, 你的引用数也不会变低, 你也不会被 CVPR拒掉, 可能作者觉得说这一块其实可能啊, 贡献不那么大, 毕竟没有太多新的东西, 主要是把那个CNN的主干模型换成了ResNet, 剩下都是一些实验, 所以如果你是写的是一个新的论文, 可能中的概率不高, 所以干脆放到这里, 给大家一并讲了算了, 这也我觉得这也是有一定道理啊, 但现在其实你说真话, 你就是写一个两三页的, technical report, 就是技术报告也不错了, 毕竟你在写, 因为做目标检测啊, 大家还是, 跟图片识别还是两波不一样的人, 你把这一块东西写的详细一点啊, 其实对做目标检测人是有好处的, 他们更容易复现你们的结果, 当然是我的事后的一些看法了, 就不讲那个appendix了, 大家有兴趣可以看一下, 就我想就是说给大家回顾一下就是说, 这篇文章啊, 我们读下来就是, 基本上还是挺顺利的啊, 就是从头读到尾就不需要读第三遍了, 我们好像也没有什么没有看懂东西, 有两个原因, 一个原因是这篇文章确实比较简单, 就是一个主要是一个残差连接, 在网络架构上的设计啊非常简单, 也是比 AlexNet 要简单一些啊, 然后, 所以导致说因为他东西比较简单, 写起来也不会那么复杂, 第二个是说, 我觉得作者这写作是非常厉害, 就大家可以学习一下就是说啊, 这导致说因为就算是简单的东西, 你写出来可能别人不一定看得懂啊, 有很多文章, 其实是还有一个很简单的思想, 但是写的特别烦, 然后大家看不懂啊, 这个所以是大家读起来, 这个文章是相对来说没有太多压力的, 另外一个是说, 当然是说我们从五年之后再来看这篇文章啊, 就是说他的主要贡献主要是把, residual connection就是残差连接用过来, 就是他当给了一些直观上的解释啊说, 使得一个更复杂模型能够, 如果训练, 如果新加的很多层的话效果不好的话, 我能够fallback, 能够变成一个简单模型, 使得你的模型不要给我过度的复杂化, 他其实是一个这么直观上的一个解释, 并没有做任何的分析啊, 他当然有一点点实验啊, 但我也讲过, 这个实验其实不那么特别可信, 另外一个他没有从方法论上就具体解释, 要从数学上来讲一下这是为什么, 因为这个文章也没什么公式啊, 大家从计算机视觉paper上来讲, 没什么公式挺正常的, 但是你要在, 那个年代那个年代可能还已经 ok 了, AlexNet那个年代, 你不写点公式你发NIPS是很难的, 那个年代可能一五年的, 已经可能问题不大了啊, 所以就是说, 他就是觉得啊, 给一些直观上的解释, 后来啊 事后大家其实去看, 其实大家不是特别的买原作者的账啊, 因为本来原作者的没有加太多东西, 后来其实大家觉得说一方面为什么, ResNet训练起来还比较快, 主要是因为梯度上他保持的比较好, 就如果你是正常的话, 你正常的话比如说我有一个啊, g(x)假设是你的, 原始的一个小的网络, 你在上面再加一些层, 那么等于是变成一个F(x), 再加一个 f 进去, 这个是新加进的层, 你对他求导的时候呢, 对 x, 求导的时候呢他当然是变成了啊 f(g(x)), 然后就是说对新加的这个项f, 他的求导啊, 再乘以你原来那个网络的求导, 对吧就是说, 他是一个累乘的关系, 就是说你新加一些层呢, 你的梯度啊你加的越多, 你梯度的乘法就越多, 这个是一个矩阵乘法, 让我乘东西就会 因为梯度是比较小的, 其实梯度一般来说在, 一个在0的附近的高斯一个分布吧, 就是值是比较小的, 大部分值跟零很近的, 所以你一乘一乘一乘就乘的特别小的, 就导致你很深的时候比较小, 也就是梯度的一个消失的问题, 虽然你 batch normalization, 或者什么东西让你比较好, 但是实际上来说他还是相对来说比较小, 但是如果你加了一个 ResNet 的话, ResNet的话他的好处就是说, 现在你的输出变成了是啊, f(g(x)) + g(x), 然后你对他求导的时候呢, 你就是这一块就说啊这一块是不变的, 但是你加号就是等于, 他等于是这一块, 这一块其实就这这一块下来, 就这一块下来, 但是他再加上了一个原始的一个, 就是没有, 就这个小的, 对吧 所以就是说, 我们知道, 这一块就是 这一块容易很小, 如果你加了很多东西, 但是这个浅层网络呢, 相对来说他相对来说会大一点, 所以这个东西梯度变成了一个, 你这块很小没关系, 但是我这一块能训练动, 就是一个加法, 就是一个, 这个如果你这个小数的话, 你这个数可能并不是很小, 所以是一个小数加上一个大数, 相对来说你的梯度还是会比较大的, 导致说, 就算你的不管你后面加你的 f加多少啊, 你加的特别特别深啊, 这个g本身 如果就是一个啊 , 前面的网络的话你不管加多少层, 我这个梯度在这里总是有用的, 而且是说他先把这一块给学好了, 所以这也是说啊, 从误差反传的时候角度来看, 为什么现在训练比较快啊, 另外一个比较有意思的是说, 在 CIFAR上面你加了1024啊, 就一千层以上啊, 他说我没有做任何太多的regularization(正则化), 他其实做了 他不是没做, 他是没有说任何special的东西, 然后效果也很好, 就是说你overfitting有一点点但是不大, 这一块其实是说你在, 你就不能用这个东西来解释了, 因为这个东西是说让你的训练比较快, 然后让你训练的动, 这个东西能解释什么东西呢, 能解释说你跟你 resnet34, 你没有加那个残差连接的时候, 你为什么精度会好, 是因为你没有加的时候, 你根本就没训练动啊, 如果你回到头看那一个图啊, 比如说你看啊, 你看这张图的话, 这个是你没有加的情况下, 就是说你这个东西, 这个东西叫收敛啊, 但收敛没意义就是说, sgd 收敛就是说你, 你就他收敛, 就是说你这里地方不切, 他就这么收敛过去了, 就假设你在这个地方, 你不把他的学习率降低, 他就这么下去了, 他就收敛在这个地方了, 所以收敛是没意义的, 这 sgd 你所谓的收敛就说, train不动了, 就训练不动了, 这个东西不叫收敛啊, 收敛就是说你, 最好收敛在有比较好的地方, 所以呢这个地方是说其实是因为, 你做深的时候呢, 你用那么简单的机器训练, 根本就跑不动, 你根本就不会得到比较好的结果, 所以你只看说收敛是意义不大的, 但是你现在加的残差连接, 你的梯度比较大, 所以就没那么容易, 因为梯度一直比较大, 就没那么容易收敛, 所以导致说你一直能够往前, 所以sgd 的精髓啊, 我之前写过篇文章就是说你知道就是说你怎么, 说人生就跟SGD一样, SGD的精髓就是说, 你得一直能跑得动, 对吧 你如果哪一天你跑不动了, 你就是梯度没了, 那你就那就完了, 你就是在一个地方止步 出不去了, 就是说SGD的精髓是 你梯度很大, 一直能够跑, 反正你有噪音吗, 然后就是说, 慢慢的慢慢的他总是会收敛, 所以就说你只要保证梯度一致够大, 然后你其实就最后的结果就会比较好, 这个是大家一些经验上的总结, 所以啊 你从, 这个角度来看, 就是说你为什么加和没加效果还是很不一样的, 另外一个是说, 我们这样说 resnet 这个, 那么就是说, 在CIFAR-10上,这么小的数据集上, 为什么他的过拟合啊, 不那么明显, 这个东西其实我, 我觉得目前还是一个 open question, 就大家有一些有研究啊, 特别现在那些transformer那些模型啊, 那么大一个的东西对吧, 那么大一个东西你是怎么样, 训练的动的, 就是说, 100个billion啊, 就是1千亿的那些参数啊, 你为什么不过拟合呢, 就大家现在有很多工作啊, 最近一些年有特别有一些很有意思的工作, 但我们在这里是没有办法给大家, 今天是没有办法给大家讲一遍了, 就是说, 其实虽然你的层数很深啊, 你的参数很多啊, 但是你的模型因为是这么构造的, 使得他的 intrinsic(内在), 就是他内在的模型复杂度其实不高了, 就是说很有可能就说你加了这个, 残差连接之后, 使得你模型的复杂度就降低了, 就是说, 你加了他 就和比他没加的时候, 他的复杂度大大的降低了, 所以他一旦模型复杂度的降低, 那么他其实过拟合就没那么严重, 所谓的模型复杂度降低, 不是说你不能表示别的东西了, 就是说你能找到一个很低的, 你能更方便的找到一个, 不那么复杂的模型去拟合你的数据, 就跟作者说的, 我不加残差连接的时候, 理论上, 我也能够学出一个有一个identity的东西, 就是后面那些层都不要, 但是实际上你做不到, 就是说因为你没有, 引导整个网络去这么走的话, 他其实这个理论上结果他根本就过不去, 所以一定是你得, 手动的把这个结果加进去, 使得他更容易能够训练出来, 所以啊 加了这个东西之后, 使得他能够, 整个resnet能够学习到一个, 相对来说更简单, 就是说如果真要做的时候, 就后面那些层都是0, 就前面那些层有东西, 就是说让你更容易的训练出一个, 简单的模型来拟合数据的情况下, 那么就是说, 等价于把你的模型复杂度都给降低了, 这个这一块有最近有很多工作啊, 有时间可以给大家讲讲, 这我觉得是, 这一块来解释这个可能是更好一点, 另外一块就是说大家如果知道, residual在机器学习是干嘛的话, 就是比如说 gradient boosting, 这个东西的话, 他的 residual 跟 gradient boosting是不一样的, gradient boosting是在标号上做residual , 然后这个地方是在 feature维度上, 但我们就不展开了, 就是说大家有兴趣可以去研究一下, 为什么这个residual 跟你的机器学习那边GBDT, 那些树上面的residual 有什么不一样, 大家可以去研究一下, 好我们这个就是对, resnet这篇文章的讲解, 基本上可以看到是说, 这篇文章提出了一个非常简单的方法, 来使得能训练更深的模型, 而且整个模型的构造是非常简单的, 虽然, 他说他的motivation为什么做的东西, 我们现在来看, 可能会觉得那个东西讲的不够深刻啊, 但是这个完全不掩盖这是一篇经典的文章啊, 你不能说我这文章实验又能飞起来, 然后还能够给一个漂亮的理论的分析, 这个是不可能的, 而且只要有一点做好了就行了, 你要么理论能飞起来, 实验根本就不做的没关系, 要么就实验能飞起来, 然后啊理论不说都没关系啊, 你只要有一个亮点, 大家认同你这个亮点, 大家会有无数人会来follow你的工作, 然后往下走, 这就是挖坑, 你把所有东西都做了, 大家怎么去跟你对吧, 然后你也给大家留口饭吃对吧, 所以你把你最大的那个肉吃了, 那么你就把剩下的饭留给大家, 所以现在说只要你的工作够厉害, 然后是很新的东西能启发的东西, 你把文章写差一点, 或者说你写很多东西没说明白, 这真的不要紧, 大家会后续的人会, 前赴后继的把你在一块往前推啊, 这个也是研究界一大魅力所在吧,