前言
Swin Transformer是 ICCV 21的最佳论文,它之所以能有这么大的影响力,主要是因为在 ViT 之后,Swin Transformer通过在一系列视觉任务上的强大表现,进一步证明了Transformer是可以在视觉领域取得广泛应用的。
我们先来看一下, Swin Transformer这个代码库,我们可以看到这里有一系列的更新,Swin Transformer是3月份传到 arxiv上的,然后4月份这代码库就放出来了,然后紧接着5月份,5月12号他们就又放出来了,这个自监督版本的 Swin Transformer,他们管他们的方法叫 moby,moby其实就是把MoCo的前两个字母和 BYOL 的前两个字母合在了一起,从方法上和性能上其实和MoCo v3和DINO呢都是差不多的,只是换了个骨干网络,所以我们上次这个对比学习串讲也没有提这篇论文。接下来又过了一个月,Swin Transformer 就又被用到了这个视频领域,他们推出了这个 Video-Swin-Transformer,然后在一系列数据集上都取得了非常好的效果,比如说在 k-400这个数据集上就已经达到了84.9的这个准确度,然后紧接着又过了几天,就在7月初的时候,因为看到了有 MLP Mixer 这篇论文,他们又把 Swin 的这个思想用到了这个 MLP 里,推出了这个 Swin MLP,然后又过了一个月,在8月初的时候,他们又把 Swin Transformer 用到了半监督的这个目标检测里,然后取得了非常好的效果,然后10月份的时候,他们就获得了ICCV 的这个最佳论文奖,然后到12月份受到了 BEiT 和 MAE 的这个推动,他们又用 Swin Transformer基于这个掩码自监督学习的方式做了一个叫 SimMIM 的论文。
所以说在这大半年的时间里,这个原作者团队就以每个月一篇论文的速度,基本把视觉领域所有的任务都刷了个遍,而且Swin Transformer 不光是应用范围广,他的效果也非常的炸裂。
那我们现在就再回到 Paperswithcode 的这个网站上,看一下它到底在每个数据集上的表现如何,鉴于 Swin Transformer 的提出主要是用来做视觉的这个下游任务的,所以这里呢我们就看一下 COCO 和 ADE20K这个是两个数据集上它的表现,我们现在往下拉看一下这个排行榜,然后你就会发现排名第一的是一个叫 Swin V2 的模型,其实也就是作者原班人马提出的这个Version2,他们就是做了一个更大版本的这个 Swin Transformer ,有30亿参数,而且提出了一系列技术,使得这个 Swin Transformer ,可以在1536乘1536这么大的图片上去做预训练,最后这个下游任务的效果就非常的好,这里我们可以看到 COCO 都已经被刷到63.1了,而大概去年这个时候,大家用卷积神经网络的时候达到在54、55的这个准确度上挣扎。然后我们往下看排名第二的其实是一个叫 Florence 的模型,这个是一个多模态的工作,它里面负责视觉的那一部分用的是这个叫 CoSwin 的这个模型,也是 Swin Transformer 的一个变体了,然后再往下我们就可以看到GLIP 也是用的 Swin large,Soft Teacher 也是 Swin large,然后 DyHead Swin large,总之排名前十的方法全都用到了 Swin Transformer。那我们现在来看 ADE20K这个数据集,我们可以看到排名第一的还是这个 Swin V2,因为模型实在是太大了,然后接下来排名二三四的都是叫一个 SeMask 的论文,他也是基于 Swin large 的,但是第五名这个 BEiT 用的是 ViT,而不是 Swin,但是紧接着后面排名的这个6、7、8、9全都还是用的是 Swin Transformer。所以说在 Swin Transformer作者团队不懈的努力之下,Swin Transformer 在大部分视觉领域上很多数据集上都取得了最好的结果,所以这就导致 Swin Transformer成了视觉领域一个绕不开的Basler,接下来再想在这些数据集上刷分或者说再想发这些领域的论文,那多多少少都得提到Swin Transformer或者跟它比,所以说 它对这个影响力是巨大的。
标题
Swin Transformer: Hierarchical ViT using Shifted Windows
题目说 Swin Transformer是一个用了移动窗口的层级式的Vision Transformer,那这个 Swin 这个名字其实也就来自于 Shifted Windows ,就是这个 S 和 win,而这个 Shifted Window这移动窗口也是 Swin Transformer这篇论文的主要贡献。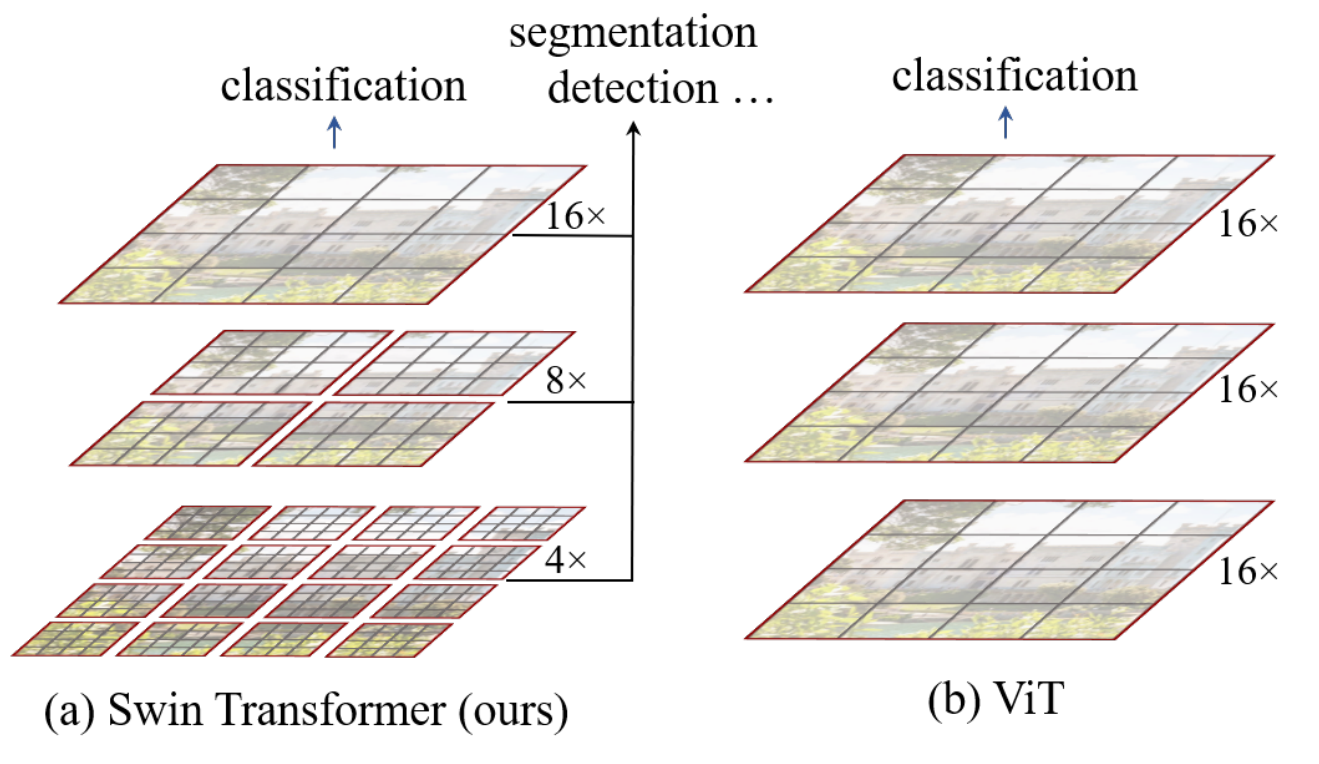
而这个层级式 Hierarchical也可以从底下的这个图1里的 a,可以简单的看出来到底在干什么,其实Swin Transformer就是想让 Vision Transformer像卷积神经网络一样,也能够分成几个 block,也能做这种层级式的这个特征提取,从而导致提出来的特征有这个多尺度的概念。
摘要
作者说这篇论文提出了一个新的 Vision Transformer,叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络。
他为什么这么说呢,因为我们上次在讲ViT的论文的时候,ViT在结论的部分指出,他们那篇论文呢只是做了分类这个任务,他们把下游任务比如说检测和分割留给以后的人去探索了,所以说在 ViT 出来之后,大家虽然看到了Transformer,在视觉领域的这个强大的潜力,但是大家并不确定Transformer能不能把所有视觉的任务都做掉,所以 Swin Transformer这篇论文的研究动机就是想来告诉大家用 Transformer没毛病,绝对能在方方面面上取代卷积神经网络,接下来大家都上 Transformer就好了。
然后接下来作者说,但是你直接把Transformer从这个 NLP 用到 Vision 这边是有一些挑战的,这个挑战呢主要来自于两个方面。
一个就是这个尺度上的问题,因为比如说你现在有一张街景的图片里面有很多车和行人,里面的物体都大大小小,那这时候代表同样一个语义的词,比如说行人或者汽车,他就有非常不同的尺寸,那这种现象在 NLP 那边就没有。
另外一个挑战也是之前我们提到过很多次的,就是说这个图像的这个 resolution太大了,如果我们要以这个像素点作为基本单位的话,这个序列的长度就变得高不可攀。
所以说之前的工作要么就是用这个后续的特征图来当做Transformer的输入,要么就是把图片打成 patch减少这个图片的 resolution,要么就是把图片画成一个一个的小窗口然后在窗口里面去做这个自注意力。
所有的这些方法都是为了减少这个序列程度。
那基于这两个挑战,本文的作者就提出了这个 hierarchical Transformer,它的这个特征是通过一种叫做移动窗口的方式学来的。
然后作者紧接着说移动窗口的好处,不仅带来了更大的这个效率,因为跟之前的工作一样,现在这个自注意力是在这个窗口内算的,所以这个序列的长度大大的降低了,同时通过shifting就移动的这个操作能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有这种cross-window connection,从而变相的达到了一种这个全局建模的能力。
然后作者说这种层级式的结构的好处,它不仅非常灵活,可以提供各个尺度的这个特征信息,同时因为它这个自注意力是在这个小窗口之内算的,所以说它的这个计算复杂度是随着这个图像大小而线性增长,而不是平方级增长,这其实也为作者之后提出 Swin V2 铺平了道路,从而让他们可以在特别大的分辨率上去预训练这个模型。
然后因为Swin Transformer拥有了像卷积神经网络一样这种分层的结构,有了这种多尺度的特征,所以它就很容易使用到这种下游任务里。
所以在这篇论文里,作者不光是在 ImageNet-1K 上做了实验,而且达到了非常好的准确度87.3,而且还在密集预测型的任务上,比如说就是物体检测,还有物体分割上取得了很好的成绩,比如说在 COCO 上,他们都刷到58.7的这个 AP,比之前最好的方法呢是高了2.7个点,然后在语义分割上呢, ADE上,他们也刷到了53.5的这个效果,比之前最好的方法呢高了3.2个点。
那这些数据集其实都是大家常刷的数据集,在上面往往你只要能提升一个点,甚至可能不到一个点,只要你故事讲的好可能都能发论文,但是Swin Transformer提了大概3个点,对这个提升是相当显著的。
所以作者这里接着说,这种基于 Transformer 的这个模型在视觉领域是非常有潜力的,然后为了凸显他们这篇文章的贡献,也就是 Shifted Windows移动窗口这个作用,他们在这个版本又加了一句话,他们说对于这种 MLP 的这种架构,他们用这种 shift window 的方法也能提升,这句话其实这个版本才加入的,他们之前第一个版本就是投稿上那篇论文其实没有这句话的,因为当时还没有MLP Mixer这篇论文。
引言
这个引言还是相对比较长的,而且里面有两张图,图一作者就是大概介绍了一下Swin Transformer想干个什么事,图二作者就介绍了一下Swin Transformer主要的一个贡献,就是这个shifted window移动窗口。
引言的前两段其实跟ViT是非常一致的,都是先说在视觉领域之前卷积神经网络是主导地位,但是呢Transformer在NLP领域又用的这么好,所以我们也想把Transformer用到视觉领域里面来。
但因为ViT已经把这件事干了,所以说Swin Transformer在第三段的开始,他说他们的研究动机呢是想证明Transformer是可以用作一个通用的骨干网络,就是对所有视觉的任务,不光是分类,在检测、分割视频上也都能取得很好的效果。
那不看文字,我们先来看一下它这个图一。
一般像写的好的论文,尤其是这种已经得了最佳论文的论文,它的图一应该是画的非常好了,就是说你只看这张图,你就大概知道这篇论文在讲什么了。
Figure 1. (a) The proposed Swin Transformer builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. (b) In contrast, previous vision Transformers [19] produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.图1.(a)所提出的Swin Transformer通过在更深层中合并图像块(以灰色示出)来构建分层特征映射,并且由于仅在每个局部窗口(以红色示出)内计算自我注意,因此具有与输入图像大小线性的计算复杂度。因此,它可以作为图像分类和密集识别任务的通用骨干。(b)相比之下,以前的视觉变换器[19]产生单个低分辨率的特征图,并且由于全局计算自我注意力而具有输入图像大小的二次计算复杂度。
作者这里先说了一下Vision Transformer,把它放在右边做一个对比,他说Vision Transformer 干一件什么事呢,就是说把这个图片打成patch,因为ViT里用的这个patch size是16x16的,所以说他这里的这个16 ×,也就意味着是16倍的这个下采样率,这也就意味着这里的每一个 patch,也就是每一个 token,它自始至终代表的这个尺寸都是差不多的,它每一层的这个Transformer block看到这个token的尺寸,都是这个16倍下采样率,16倍、16倍下采样率。虽然它可以通过这种全局的自注意力操作达到这个全局的建模能力,但是它对多尺寸特征的这个把握呢就会弱一些。
那我们知道对于视觉任务,尤其是这些下游任务,比如说检测和分割来说,这个多尺寸的特征是至关重要的。
比如说对目标检测而言,运用最广的一个方法就是FPN,a feature pyramid network,它的意思就是说,当你有一个分层式的这种卷积神经网络之后,你每一个卷机层出来的那些特征,它的这个 receptive field,感受也是不一样的,能抓住物体这个不同尺寸的特征,从而能够很好的处理这个物体不同尺寸的这个问题。
那另外对于物体分割这个任务来说,那最常见的一个网络就是UNet,那UNet里为了处理物体这个不同尺寸的问题,它们就提出来一个这个skip connection这个方法,意思就是说,当你一系列这个下采样做完以后,你现在去做上采样的时候,你不光是从这个bottleneck里去拿特征,你还从之前也就是每次下采样完之后的这个东西里去拿特征,这样你就把那些高频率的这些图像细节又全都能恢复出来了。
当然分割里大家常用的网络结构还有 PspNet,还有 DeepLab,这些工作里也有相应的处理多尺寸的方法,比如说使用空洞卷机,比如说使用psp和aspp层。总之,对于计算机视觉的这些下游任务,尤其是这些密集预测型的任务检测、分割,有多尺寸的特征是至关重要的。
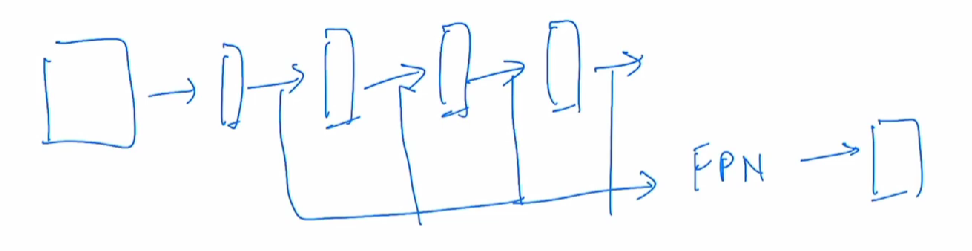
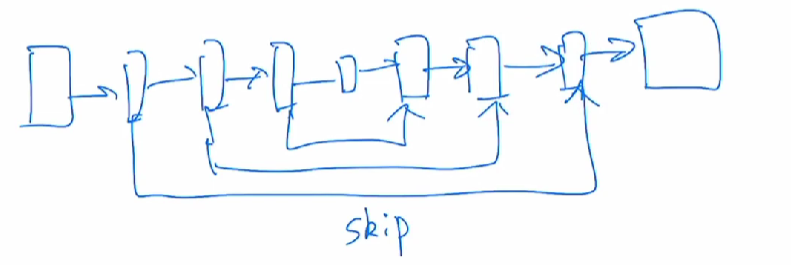
那我们现在回到Swin Transformer,作者就说但是在 ViT 里,它处理的特征都是单一尺寸,而且是这个low resolution,也就是说自始至终都是处理的这个16倍下采样率过后的特征,所以说,它可能就不适合处理这种密集预测型的任务。同时对 ViT 而言。它的这个自注意力始终都是在这个最大的窗口上进行,就是始终都是在整图上进行的,所以它是一个全局建模,所以说它的这个复杂度是跟这个图像的尺寸进行平方倍的增长。
那像检测和分割领域,那一般大家现在常用的这个输入尺寸,都是800乘以800或者1000乘1000了,那你之前虽然用patch size 16能处理这种24x24的图片,但是当你这个图片变到这么大的时候,即使你用patch size16,你的这个序列长度呢还是会上千,这个计算复杂度还是难以承受的。
所以基于这些挑战,作者提出了Swin Transformer。Swin Transformer其实是借鉴了很多,卷积神经网络的这个设计理念,以及它的先验知识。比如说呢为了减少这个序列的长度,降低这个计算复杂度,所以Swin Transformer采取了在这种小窗口之内算这个自注意力,而不是像ViT一样在整图上去算自注意力。
这样只要你这个窗口大小是固定的,你这个自注意力的这个计算复杂度呢就是固定的,那整张图的这个计算复杂度就会跟这张图片的大小而成的线性增长关系。就是说如果你图片增大了x倍,那你的窗口数量呢也就增大了x倍,那你的计算复杂度呢也就是乘以x,而不是乘以x的平方。
那这个其实就算利用了卷积神经网络里的这个Locality 的这个 Inductive bias,就是利用了这个局部性的这个先验知识,就是说同一个物体的不同部位或者语义相近的不同物体还是大概率会出现在相连的地方,所以即使我是在一个 Local、一个小范围的窗口,那去算这个自注意力,那也是差不多够用的。全局去算这个自注意力对于视觉任务来说,其实是有点浪费资源的。
那另外一个挑战就说,我们如何去生成这个多尺寸的特征呢。
那我们继续回想卷积神经网络,卷积神经网络为什么会有这种多尺寸的特征呢,主要是因为有Pooling池化这个操作,池化这个操作能够增大每一个这个卷积核能看到的这个感受野,从而使得每次池化过后的这个特征抓住物体的这个不同尺寸。
所以类似的Swin Transformer这里也提出来了一个类似于池化的操作,叫做patch merging,就是把相邻的这个小patch合成一个大patch,那这样合并出来的这一个大patch,其实就能看到之前四个小patch看到的内容,它的这个感受野就增大了,同时它也能抓住这个多尺寸的特征。
所以也是像图一里左边画的这样,Swin Transformer刚开始的这个下采样率是4倍,然后变成了8倍、16倍,之所以刚开始是4×的,它最开始的这个patch是4乘4大小的,那一旦你有了这种多尺寸的特征信息, 你有了这种4乘8乘16乘的这个特征图,那很自然的,你就可以把这些多尺寸的特征图呢输给一个 FPN,从而你就可以去做检测了。那同样的道理,你有了这些多尺寸的特征图以后,你也可以把它扔给一个 UNET,然后它就可以去做分割了。
所以这就是作者在这篇论文里反复强调的,Swin Transformer是能够当做一个通用的骨干网络的,不光是能做这个图像分类,它还能做这种密集预测性的任务。
第四段
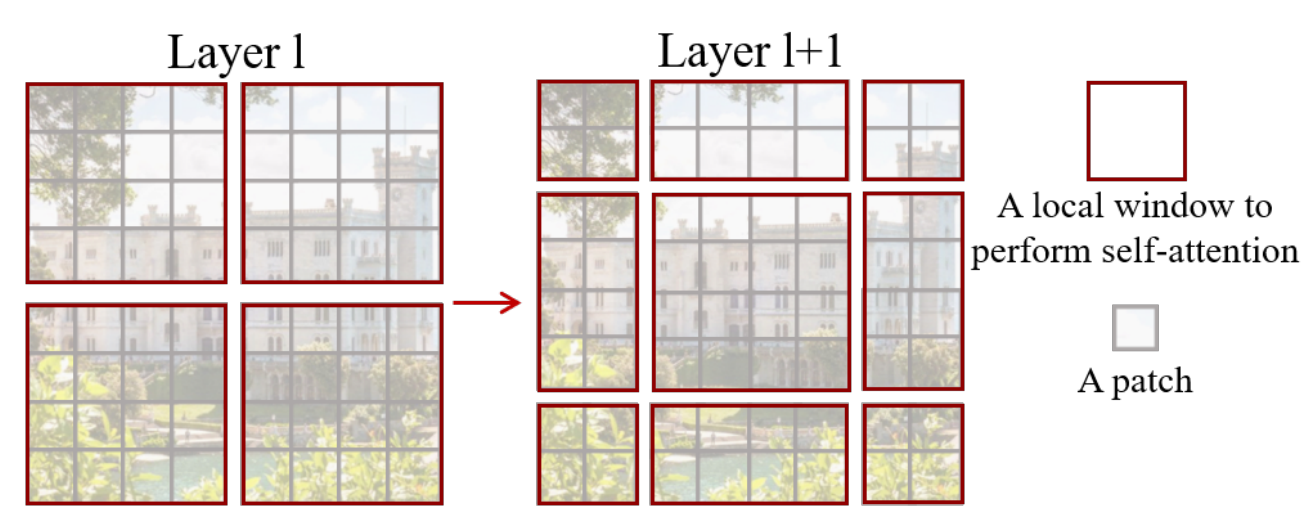
那按照图一讲完引言的第三段,作者在第四段主要就开始讲Swin Transformer一个关键的设计因素,也就是这个移动窗口的操作,具体的内容呢我们直接来看图二。Figure 2. An illustration of the shifted window approach for computing self-attention in the proposed Swin Transformer architecture. In layer l (left), a regular window partitioning scheme is adopted, and self-attention is computed within each window. In the next layer l + 1 (right), the window partitioning is shifted, resulting in new windows. The self-attention computation in the new windows crosses the boundaries of the previous windows in layer l, providing connections among them.图2.在Swin Transformer架构中计算自我注意力的移位窗口方法的说明。在层l(左)中,采用常规窗口划分方案,并且在每个窗口内计算自注意。在下一层l + 1(右)中,窗口分区被移位,从而产生新的窗口。新窗口中的自注意力计算跨越层l中的先前窗口的边界,提供它们之间的连接。
图二里它首先说,如果在这个Transformer第L层把这个输入或者说这个特征图分成这种小窗口的话,那就会有效的降低序列程度,从而减少这个计算复杂度。
那作者右边的这个图里也说了,这个灰色的小patch,就每一个这个小 patch是最基本的这个元素单元,也就是4x4的那个patch,然后每个红色的框是一个中型的计算单元,也就是一个窗口。
在Swin Transformer这篇论文里,一个小窗口里面默认是有七七四十九个小patch的,那在这里就是画个示意图,主要是来讲解这个 shift 的操作是怎么完成的,那如果我们现在用一个大的这个蓝色的正方形来描述这个整体的特征图呢,其实shift这个操作呢,就是往右下角的方向整体移了两个 patch,也就变成了像右图这样的格式,然后我们在新的这个特征图里去把它再次分成这个四方格,那最后shift完,我们就有这么多窗口了,这样的好处就是说窗口与窗口之间现在可以进行互动了。
因为如果我们按照原来的方式,就是没有shift,那这些窗口它们之间都是不重叠的,那如果每次自注意力的操作都在这个小的窗口里头进行了,那这个窗口里的patch就永远无法注意到别的窗口里的那些patch的信息,这就达不到使用Transformer的初衷了。因为Transformer的初衷就是更好的理解上下文,那现在如果你这些窗口都是不重叠的,那这个自注意力真的就变成一个孤立自注意力了,它就没有这种全局建模的能力。
但现在如果我们加上这个shift的操作,比如说这个patch,原来就只能跟这个窗口里的别的patch去进行交互,但是现在你shift之后,这个patch就可以跟新的窗口里的别的 patch就进行交互了,而这个新的窗口里所有的patch其实来自于上一层别的窗口里的这些patch,这也就是作者这里说的,能起到一个cross-window connection,就是窗口和窗口之间可以交互了,那在配合上之后提出了这个patch merging,那合并到这个Transformer最后几层的时候,他每一个 patch本身的感受野就已经很大了,就已经能看到大部分图片了,然后再加上这个移动窗口的操作,现在它所谓的这种窗口内的局部注意力,其实也就变相的等于是一个全局的自注意力操作了,这样就是既省内存效果也好,所以一石二鸟。
第五段
接下来第五段,作者就再次卖了一下结果,因为Swin Transformer的结果确实非常好。
第六段
然后最后一段,作者就展望了一下,作者说他们坚信一个 CV 和NLP 之间大一统的框架是能够促进两个领域共同发展的。
这个也确实如此,因为我们人在学习的过程中也是一个多模态的学习过程,但我觉得Swin Transformer还是利用了更多的这个视觉里的这个先验知识,从而在视觉任务上呢大杀四方,但是在这个模型大一统上,也就是这个unified architecture上来说,其实 ViT 还是做的更好的,因为它真的可以什么都不改,什么先验信息都不加,就能让Transformer在两个领域都能用的很好,那这样模型不仅可以共享参数,而且我们甚至可以把所有模态的这个输入直接就拼接起来,当成一个很长的输入,直接扔给这个Transformer去做,而不用考虑每个模态的它的特性。
结论
第一段
结论的第一段是非常中规中矩的,上来就说这篇论文提出了Swin Transformer,它是一个层级式的Transformer,而且它的计算复杂度是跟这个输入图像的大小呈这个线性增长的,然后作者又说了一下Swin Transformerr在COCO和ADE20K上的这个效果都非常的好,远远的超越了之前这个最好的方法,所以作者说基于此,我们希望这个 Swin Transformer能够激发出更多更好的工作,尤其是在多模态方面。
第二段
然后这个结论的第二段呢是非常有意义的,作者说因为在Swin Transformer这篇论文里,它最关键的一个贡献就是这个基于Shifted Window的这个自注意力,这个东西对很多视觉的任务,尤其是对这些下游任务,这些密集预测型的任务是非常有帮助的。
但是也就跟我们刚才在引言最后一段说到的一样,如果这个Shifted Window这个操作不能用到NLP领域里,那其实在模型大一统上,那这个论据就不是那么强了。
所以作者说接下来他们的这个未来工作,就是要把这个Shifted Windows用到这个NLP里面,而且如果真的能做到这一点,那Swin Transformer真的就是一个里程碑式的工作了,而且这个模型大一统的故事也就讲的圆满了。
模型整体架构
那接下来我们回到正文一起读一下这个主体的方法部分,鉴于这个相关工作跟ViT的相关工作是非常相似的,所以我们这里就不再复述了。作者就是先大概讲了一下卷积神经网络,然后又讲了一下自注意力,或者Transformer是如何用来帮助卷积神经网络的,最后就是纯的Transformer用来做这个视觉里的骨干网络。
那我们现在直接就来看一下方法部分,作者在这个章节主要分了两个大块。
第一个大块是3.1,作者就是大概把整体的流程讲了一下,主要就是过了一下这个前向过程,以及提出的这个patch merging这个操作是怎么做的。
第二个大块基于这种Shifted Window的自注意力,Swin Transformer是怎么把它变成一个transformer block,然后进行计算。
那我们现在直接就对着这个模型总览图来过一遍这个模型的前向过程,这个比对着文字讲还要清晰很多。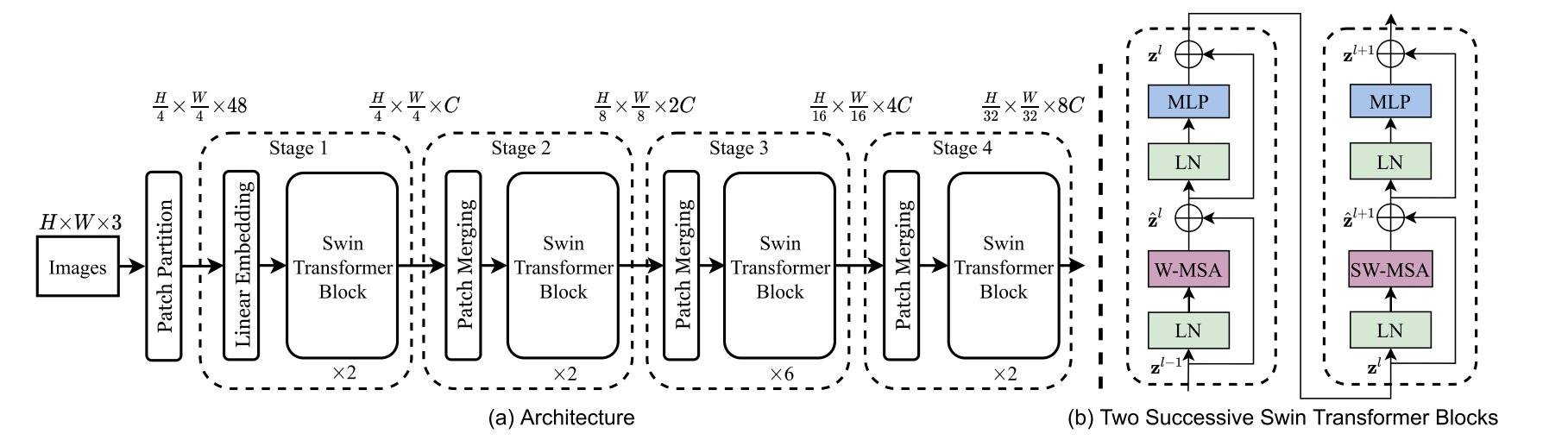
Figure 3. (a) The architecture of a Swin Transformer (Swin-T); (b) two successive Swin Transformer Blocks (notation presented with Eq. (3)). W-MSA and SW-MSA are multi-head self attention modules with regular and shifted windowing configurations, respectively.图3.(a)Swin Transformer(Swin-T)的架构;(B)两个连续的Swin Transformer块(用等式1表示的符号);(三))。W-MSA和SW-MSA分别是具有规则和移位窗口配置的多头自注意模块。
那假设说我们现在有一张输入图片,那就是ImageNet的标准尺寸,224x224x3的一张图片,那首先第一步就是像ViT那样把这个图片打成patch,那在Swin Transformer这篇论文里,它的patch size是4x4,而不是像ViT一样16x16,所以说它经过这层 patch partition,就是打成 patch 之后,得到这个图片的尺寸是56x56x48。
56就是224/4,因为你 patchsize是4,然而这个向量的维度48是因为4x4x3,3就是图片的这个 RGB 通道。
然后打完了patch,接下来就要做这 Linear Embedding,也就是说我们要把这个向量的维度变成一个我们预先设置好的值,就是这个Transformer能够接受的值,那在Swin Transformer的论文里,它把这个超参数呢设为c,对于Swin tiny这个网络来说,也就是这个图里画的这个网络总览图,它的c是96,所以说经历完这个Linear Embedding之后,我们这个输入的尺寸就变成了56x56x96,那前面的56x56就会拉直变成3136,变成了这个序列长度,后面这个96就变成了每一个token的这个向量的维度。
其实这个Patch Partition和 Linear Embedding就相当于是ViT里的那个Patch Projection那一步操作,而这个在代码里也是用一次卷积操作就完成了,那这个第一部分,跟ViT其实还是没有区别的。
但紧接着区别就来了,那首先我们可以看到,这个序列长度现在可是3136这么长,如果大家还记得的话,对于ViT来说,它用patch size 16x16,它的序列长度就只有196那么长,是相对短很多的,那这里的3136就太长了,是目前来说Transformer不能接受的这个序列长度,那怎么办呢,所以Swin Transformer就引入了这种基于窗口的自注意力计算,那每个窗口按照默认来说,它都只有七七四十九个 patch,所以说序列长度就只有49就相当小了,这样就解决了这个计算复杂度的问题。
所以也就是说,这里这个swing transformer block是基于窗口去算自注意力的,至于每一个block里具体做了什么,我们接下来马上就讲,我们现在暂时先把这个 transformer block当成是一个黑盒,我们只关注这个输入和输出的这个维度。
那大家也知道,如果你不对Transformer去做更多的约束的话,那Transformer输入的序列程度是多少,那它输出的序列长度也是多少,它的这个输入输出的尺寸是不变的,所以说在经过这两层Swin Transformer block之后,我们的这个输出还是56x56x96。
那到这,其实Swin Transformer的第一个阶段就走完了,也就是先过一个Patch Projection层,然后再过一些 Swin Transformer block,那接下来,如果想要有多尺寸的这个特征信息,那就要构建一个层级式的transformer,也就是说我们需要一个像卷积神经网络里一样,有一个池化的操作。
那在这篇论文里,作者就提出来这个Patch Merging的操作。
Patch Merging其实在之前一些工作里也有用到,我个人觉得它很像之前一个操作的一个反过程,就是Pixel Shuffle的那个上采样,Pixel Shuffle是lower level任务中很常用的一个上采样的方式。
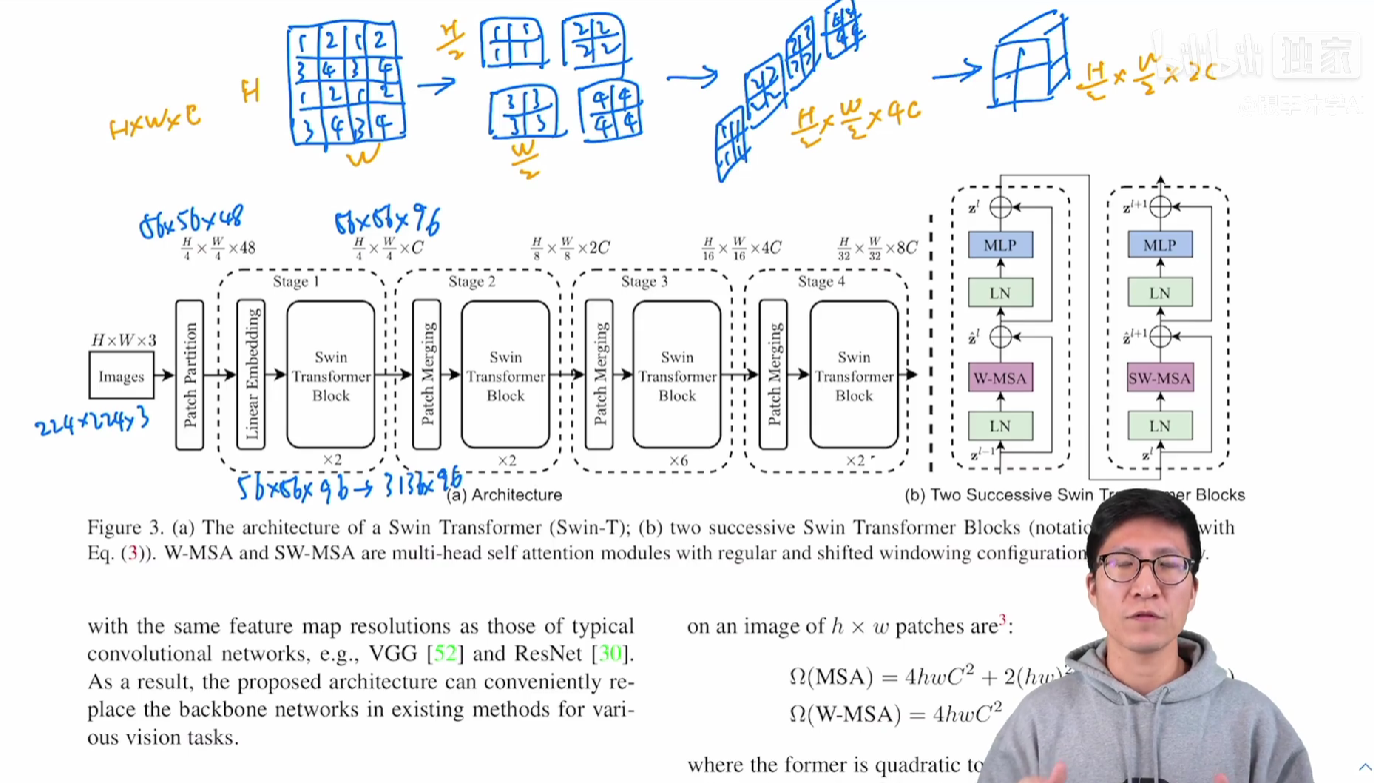
那么我们现在来简单看一下Patch Merging到底是怎么做的,假如说我们这里举个简单的例子,这有一个张量,那Patch Merging,顾名思义,就是把临近的小patch合并成一个大 patch,这样就可以起到下采样一个特征图的效果了,那这里呢因为我们是想下采样两倍,所以说我们在选点的时候,是每隔一个点选一个,也就意味着说对于这个张量来说,我每次选的点是1、1、1、1,所以其实在这里的1、2、3、4,并不是这个矩阵里有的值,而是我给它的一个序号,同样序号位置上的这个patch就会被 merge 到一起,对这个序号只是为了帮助理解。那经过我们这个隔一个点采一个样之后,我们原来的这一个张量就变成了四个张量,也就是说所有的这个1都在一起了,2也在一起,3在一起,4在一起。如果说原来那个张量的维度呢是 h * w * c , 当然我这里 c 没有画出来,假设说 c 是这个维度,那经过这次采样之后,我们就得到了4个张量,每个张量的大小呢是 h/2、w/2,它的这个尺寸都缩小了一倍,那现在我把这四个张量在 c 的这个维度上拼接起来,也就变成了这种形式,那这个张量的大小就变成了h/2 * w/2 * 4c,就是说他相当于用空间上的维度去换了更多的这个通道数。
通过这么一个操作,我们就把原来一个大的张量就变小了,就像卷积神经网络里的这个池化操作一样,然后为了跟卷积神经网络那边保持一致,因为我们知道,不论是 VGGNet 还是 ResNet,一般在这个池化操作降维之后,它的通道数都会翻倍,从128变成256,从256再变成512,所以说这里我们也只想让他翻倍,而不是变成4倍。
所以紧接着他又再做了一次操作,就是在 c 这个维度上,它用一个1*1的卷积把这个通道数降下来变成一个2 c,通过这个操作,我们就能把原来一个大小为 h*w*c 的张量变成了 h/2 * w/2 *2c 的一个张量,也就是说空间大小减半,但是通道数乘2,这样就跟卷积神经网络那边完全对等起来了,整个这个过程就是Patch Merging。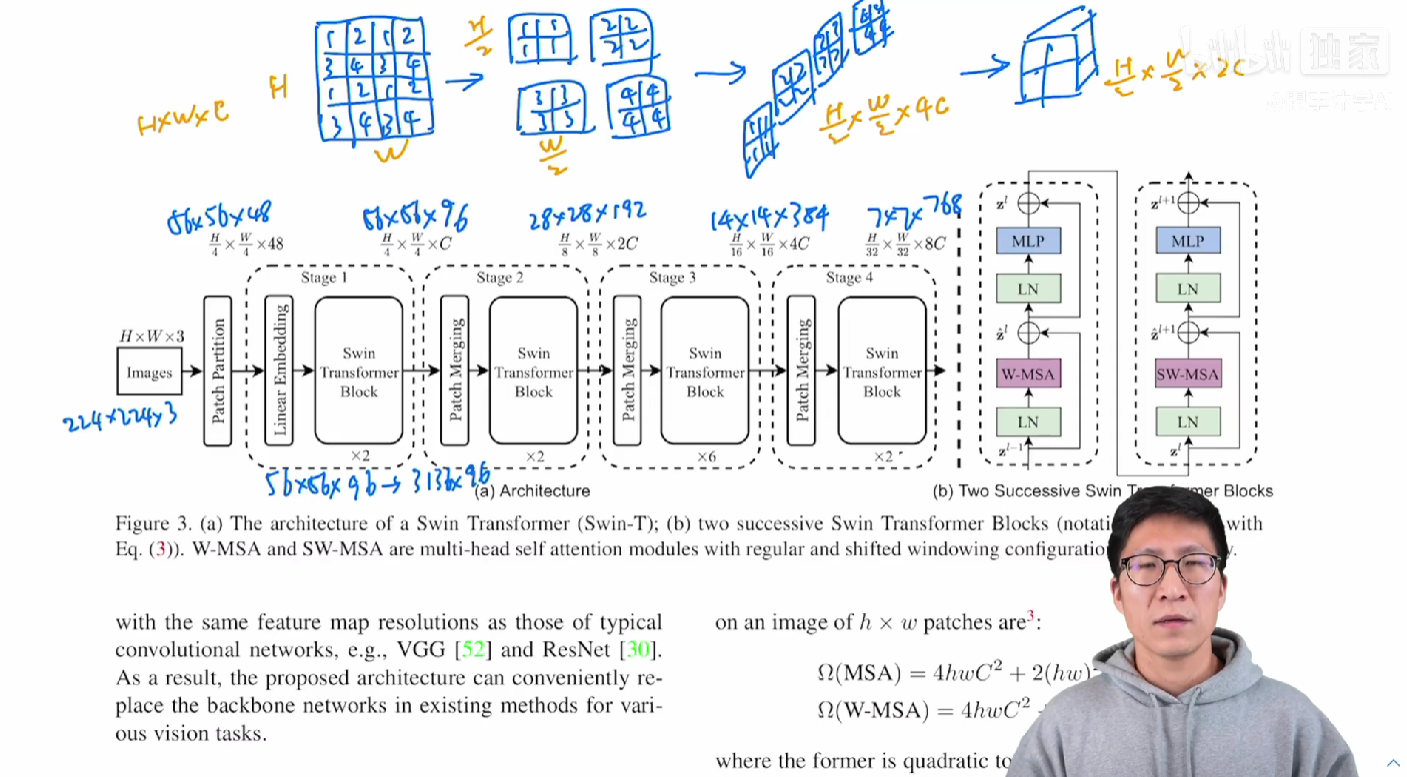
所以我们回到模型总览图,那经历过这次Patch Merging操作之后,我们的这个输出的大小就从56*56*96变成了28*28*192,那同样的经过这个 Transformer block,尺寸是不变的,所以除了还是28*28*192,这样第二阶段呢也就完成了。
那第三和第四阶段都是同理,都是先进来做一次Patch Merging,然后再通过一些Swin Transformer block,所以这个维度呢就进一步降成了14*14*384,以及7*7*768。
这里其实我们就会发现,这个特征图的维度真的跟卷积神经网络好像,因为如果你去回想残差网络,它的这个多尺寸的特征就是经过每个残差阶段之后,它的特征图大小也是56*56、28*28、14*14,最后呢是7*7,而且其实为了和卷积神经网络保持一致,Swin Transformer这篇论文,并没有像ViT一样使用那个CLS token。
大家如果还记得 ViT 的话,ViT 就是给刚开始的输入序列又加了一个CLS token,所以这个长度呢就从196变成了197,然后最后拿这个CLS token的这个特征直接去做分类,但Swin Transformer这里没有用这个 token,它是像卷积神经网络一样在得到最后的这个特征图之后用了一个global average polling,就是一个全局池化的操作,直接把这个7*7就取平均拉直变成1了。
作者这个图里并没有画,因为Swin Transformer的本意并不是只做分类的,它还会去做检测和分割,所以说它只画了这个骨干网络的部分,它没有去画最后的这个分类头或者这个检测头。但是如果我们是做分类的话,那这里最后就变成了1*768, 然后又变成了1*1,000,而如果我们是做ImageNet的话,这就完成了整个一个分类网络的这个前向过程。
所以说大家看完整个前向过程之后,就会发现Swin Transformer,它有四个这个 stage,它还有类似于池化的这个patch merging操作,然后它的自注意力还是在小窗口之内做的,以及最后它还用的是 global average polling,所以说Swin Transformer这篇论文真的是把卷积神经网络和Transformer这两系列的工作完美的结合到了一起,你也可以说它是披着Transformer皮的卷积神经网络。
窗口自注意力
那说完了整个模型的前向过程,现在我们就来看一下文章的第二大块,也就是文章的主要贡献,就是基于窗口或者移动窗口的这个自注意力。
这里作者又写了一段他们的这个研究动机,就是为什么要引入这种窗口的自注意力,其实跟之前引言里说的都是一个事情,就是说这种全局的这种自注意力的计算会导致平方倍的复杂度,同样说,当你去做视觉里的这种下游任务,尤其是这种密集预测型的任务,或者说, 当你遇到就是非常大尺寸的这种图片的时候,这种全局算自注意力的计算复杂度就非常贵了。
所以紧接着作者就说,那我们就不去全局的做这种自注意力,我们现在就用这种窗口的方式去做这种自注意力。那这里我们就举个例子,来说一下这个窗口到底是怎么划分的,作者说,原来的图片会被平均的分成一些没有重叠的窗口,那我们现在就来拿这个第一层之前的输入来举例子,它的尺寸呢就是56*56*96,也就说我们会有一个张量,它的这维度呢是56*56的,然后我们就把它切成一些不重叠的这些方格,也就是这里用橘黄色表示这些方格,这每一个橘黄色的方格就是一个窗口了,但是这个窗口并不是最小的计算单元,最小的计算单元其实还是之前的那个 patch。也就意味着说,每一个这个小窗口里其实还有 m * m 个 patch,那在 Swin Transformer 这篇论文里一般这个 m 是默认为7的,也就是说,这一个橘黄色的小方格里有七七四十九个小 patch,然后现在所有的这个自注意力的计算都是在这些小窗口里完成的,就说这个序列长度永远都是七七四十九。那我们原来这个大的这个整体特征图到底里面会有多少个窗口呢,那其实也就是每条边56/7就8个窗口,也就是说一共呢会有8*8等于64个窗口,就说我们会在这64个窗口里分别去算它们的自注意力。
我们之前虽然也提过很多次,就是这种基于窗口的自注意力模式,那我们从来好像也没有具体的讲过它们这个计算复杂度到底如何,也就是说到底这种基于窗口的自注意力计算方式能比全局的这种自注意力方式省多少。
在Swin Transformer这篇论文里,作者就给出了一个大概的估计,它这里写了两个公式。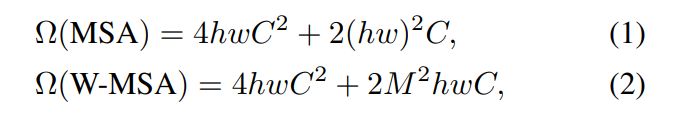
第一个公式对应的就是标准的这种多头自注意力,它的计算复杂度会有多少,那在这里呢 h、w 就像它上面说的这样,就每一个图片大概会有 h * w 个 patch。那在我们刚才的例子里,h 和 w 就分别都是56,c 就是特征的那个维度。
那基于窗口的这个自注意力计算的复杂度又会是多少呢,那作者在公式2里就给出了答案,这里的 m 就是刚才的7,也就是说一个窗口的某条边上到底现在会有多少个patch。
那这个公式是怎么推算出来的呢,我们先拿这个标准的这个多头自注意力来举个例子,就说如果我们现在有一个输入那这个自注意力,首先就是说我先把它变成 q k v 三个向量,这个过程其实就是原来的向量分别乘了三个系数矩阵,然后一旦得到 query 和 k 之后,它们就会做一个相乘,最后得到这个 attention,也就是自注意力的这个矩阵,然后有了自注意力之后,它就会去和这个 value 做一次乘法,也就相当于是做了一次加权,最后因为这是多头自注意力,所以最后还会有一个这个 projection layer,这个投射层就会把向量的维度投射到我们想要的那个维度。
那现在如果我们给这些向量都加上它们该有的维度,也就是说刚开始这个输入是 hw * c,第一步q k v这个函数相当于是用一个 hw * c 的向量去成一个 c * c 的系数矩阵,然后最后得到了 h w * c,所以每一个计算的复杂度呢是 h * w * c^2,那因为你有三次操作,所以是三倍的 h*w*c^2,然后现在到了算自注意力,这那就是 h*w*c,然后乘以 k 的这个转置,也就是 c*h*w,所以得到了 h*w*h*w,那这个计算复杂度呢就是(h*w)^2*c。那接下来是这个自注意力矩阵和这个value的乘积,它的计算复杂度呢就还是 (h*w)^2*c,所以现在这块就成了2*(h*w)^2*c,那最后一步这个投射层也就是h*w*c乘以c*c变成了 h*w*c ,它的计算复杂度就又是 h*w*c^2,所以这里再加1那就是3变成4,这个其实就是最后的公式1了。
那基于窗口的这种自注意力计算复杂度又是如何得到的呢,因为我们在每个窗口里算的还是多头自注意力,所以我们可以直接套用这个公式1,只不过它的这个高度和宽度变化了,那现在高度和宽度不再是 h * w,而是变成这个窗口有多大了,也就是 m * m,也就是说啊现在这个 h 变成了 m,w 也是 m,它的序列长度就只有 m * m 这么大,所以当你把 m 值带入到这个公式1之后,我们就得到计算复杂度是4 * m^2 * c^2,加上这个2 * m^4 * c,这个就是在一个窗口里算多头自注意力,所需要的计算复杂度,那我们现在一共有多少个窗口,其实我们现在是有 h/m * w/m 这么多个窗口的,那我们现在用这么多个窗口乘以每个窗口所需要的计算复杂度,就会得到接下来这个公式。我们可以看到,虽然这两个公式前面这两项是一样的,只有后面这块从 (h*w)^2变成了 m^2 * h * w,看起来好像差别不大,但其实如果你仔细带入数字进去算,你会发现这个计算复杂的差距是相当巨大的,因为这里的 h w,比如说是56*56的话,你这里的 m^2 其实只有49,所以是相差了几十甚至上百倍的。
移动窗口自注意力
然后接下来作者说,这种基于窗口的算自注意力的方式,虽然很好的解决了这个内存和计算量的问题,但是现在我窗口和窗口之间没有通信了,这样我就达不到全局建模了,也就文章里说的,会限制他这个模型的能力,我们最好还是要有一种方式,就是能让窗口和窗口之间互相通信起来,这样效果应该会更好,因为具有上下文的信息了,所以这里作者就提出来这个移动窗口的方式。
他刚开始提出这个移动窗口,其实我们刚才已经简单的提到过了,就是在这个图2里画出来的,如果原来的窗口长这个样子,我们现在就把窗口往下移一半就变成了右边这种形式,然后如果我们Transformer是上下两层,连着做这种操作,就是先是 window,然后再是 shifted window 的话,就能起到窗口和窗口之间互相通信的目的了。
所以说在 Swin Transformer里,它的这个 transformer block 的安排是有讲究的,它每次都是先要做一次基于窗口的这个多头自注意力,然后再做一次基于这个移动窗口的多头自注意力,这样就达到了窗口和窗口之间的互相通信。
如果我们看图呢,也就是说每次这个输入先进来,它做一次 Layernorm,然后做这个窗口的多头自注意力,然后再过 Layernorm 过 MLP,这就是第一个 block 结束了,这个 block 结束以后,紧接着我们要做一次Shifted window,也就是基于移动窗口的这个多头自注意力,然后再过 MLP 得到输出,这两个 block 加起来,其实才算是 Swin Transformer一个基本的计算单元。
这也就是为什么回头我们去看这个模型的配置,也就是这里的这个2、2、6、2,就是一共有多少层Swin Transformer block的时候,我们会发现这个数字总是偶数,那是因为它始终都需要两层 block连在一起,作为一个基本单元,所以一定是2的倍数。
那其实论文读到这里,Swin Transformer整体的这个故事和结构就已经说完了,那主要的研究动机就是想要有一个层级式的 Transformer,那为了这个层级式,所以他们介绍了这种Patch Merging的操作,从而能像卷积神经网络一样把这个Transformer分成几个阶段,然后为了减少计算复杂度,争取能做视觉里这些密集预测的任务,所以他们又提出了这种基于窗口和移动窗口的这个自注意力方式,也就是这里连在一起的两个Transformer block,最后把这些部分加在一起,就是这个Swin Transformer 的结构。
其实作者后面还讲了两个点,一个就是怎样提高移动窗口的这个计算效率,他们采取了一种非常巧妙的这种 masking掩码的方式,另外一个点就是这篇论文里没有用绝对的位置编码,而是用相对的位置编码。
但这两个点其实都是为了提高性能的一些技术细节,跟文章整体的故事已经没有多大关系了,鉴于移动窗口是 Swin Transformer的主要贡献,所以我们还是会讲一下这个巧妙的掩码方式,但是相对位置编码已经有很多别的视频和别的博客详细的讲解过了,这里我就不再复述了。
那我们接下来就来说一下,目前的这种移动窗口方式到底还有哪些问题,为什么作者还要提高它的这个计算性能。
我们直接来看图二,图二就是一个基础版本的移动窗口,就是把这个窗口模式(左边)变成了这种窗口方式(右边),虽然这种方式已经能够达到窗口和窗口之间的互相通信了,但是我们会发现一个问题,就是原来你计算的时候,你的这个特征图上只有四个窗口,但是当你做完移动窗口这个操作之后,你现在得到了9个窗口,你的这个窗口的数量增加了,而且每个窗口里的元素大小不一,那比如说中间的这个窗口就还是4 4 有16个这个 pitch,但是别的这些窗口有的有4个 patch ,有的有8个 patch,这都不一样了,那如果我们想去做快速运算,就是把这些窗口全都压成一个 patch,直接去算这个自注意力,现在就做不到了,因为你窗口的大小不一样。那有一个简单粗暴的解决方式,就说我把这些小窗口周围,我再给 pad 上0 ,把它照样pad成和中间这个窗口一样大的窗口,那这样呢我们就有9个完全一样大的窗口,这样就还能把它们压成一个batch,就会快很多,但是你会发现这样的话,你无形之中,你的这个计算复杂度就提升了,因为原来你如果去算这种基于窗口的自注意力,你只用算4个窗口的,但是现在你需要去算9个窗口的,你这个复杂度呢一下提升了两倍多,所以还是相当可观的,那怎么办,怎么能让第二次这个移位完的窗口数量还是保持4个,而且每个窗口里的这个patch数量也还保持一致呢。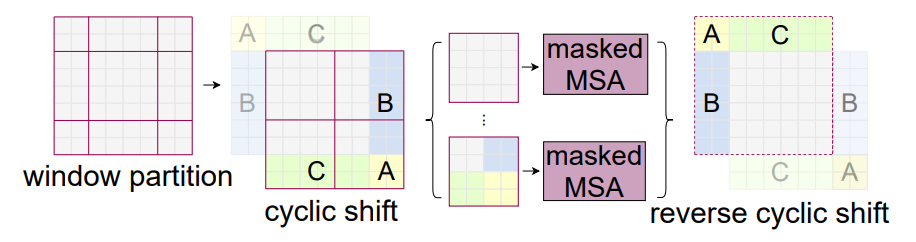
那作者这里就提出了一个非常巧妙的一个掩码的方式,我们现在直接来看这个图四,图四就是说,当你通过这种普通的这种移动窗口方式得到这9个窗口之后,我们现在不在这9个窗口上算这个自注意力,我们先再做一次这个循环移位,就这里这个 cyclic shift,具体的意思就是说,假如说我们把这个小窗口当成 a,这个横块当成 c,这个当成 b ,我们就先把这个 a 和 c 这一块,直接移到下面来,就是这块,最下面呢就变成了 a 和 c,然后我们再把左边这一块再搬到右边来,就变成了 b 和 a,所以说经过这次循环移位之后,原来的这个窗口,就变成了现在这个窗口的样子,那如果我们在这个大的特征图上,再去把它分成这个四宫格的话,我们现在不就又得到了四个窗口吗,意思就是说我们移位之前的窗口数呢也是4个,我移完位之后再做一次循环移位,那得到窗口数还是4个,那这样窗口的数量就固定了,也就说这个计算复杂度就固定了。
但是现在新的问题就来了,虽然对于这个窗口来说,它里面的元素都是互相紧挨着的,他们之间呢可以互相两两去做这个自注意力,但是对于剩下这几个窗口来说,它们里面的元素是从别的地方,很远的地方搬过来的,所以他们之间按道理来说是不应该去做这个自注意力的,就他们之间也不应该有什么太大的联系,比如说,像这里这块的元素和这块的元素,那这个 c 本来是从上面移过来的,也就意味着,假如说我们现在这个图片是上面是天空,下面是地面的话,那这个 c 原来是天空,这个块原来是地面,那你把这个 c 挪到下面来以后,难道这个天空就应该在地面之下吗,明显就是不符合常理的,那我们不应该让这种事情发生,所以就意味着,这块和这块是不应该去做这个自注意力计算的,同理那就是说,这块和这块也不应该去做自注意力,那这块这块这块这块那都是分开的,它们之间都不应该互相去做自注意力,那这个问题该怎么解决呢,那其实这里,就需要一个很常规的操作了,也就是这个掩码这个操作,这在Transformer过去的工作里是层出不穷,很多工作里,都有各式各样的这个掩码的操作,那在 Swin Transformer这篇论文里,作者也巧妙的设计了几种掩码的方式,从而能让一个窗口之中,不同的区域之间,也能用一次前项过程,就能把这个自注意力算出来,但是互相之间都不干扰,也就是它后面说的这个 masked 的Multi-head Self Attention,具体的掩码方式我们马上就讲,然后算完了这个多头自注意力之后,我们还有最后一步,也就是说我们需要把这个循环位移,再给它还原回去,也就是说我们需要把这里的a、b、c再还原到原来的位置上去,原因就是我们还需要保持,原来这个图片的这个相对位置大概是不变的,整体图片的这个语义信息也是不变的,如果我们不把这个循环位移还原的话,那我们相当于在做Transformer的这个操作之中,我们一直在把这个图片往右下角移移移,不停的再往右下角移,那这样这个图片的语义信息很有可能就被破坏掉了。
所以说整体而言,这个图4就是介绍一种高效的、批次的这种计算方式,比如说本来我们移动窗口之后,得到了9个窗口,而且窗口之间的这个patch数量每个都不一样,我们为了达到这个高效性,为了能够进行这个批次处理,我们先进行一次循环位移,把9个窗口变成4个窗口,然后用巧妙的这种掩码方式,让每个窗口之间能够合理的去算这个自注意力,最后再把算好的自注意力呢再还原, 就完成了这个基于移动窗口的自注意力计算。
那现在我们就通过一个例子来大概说一下这个掩码操作是怎么做的。
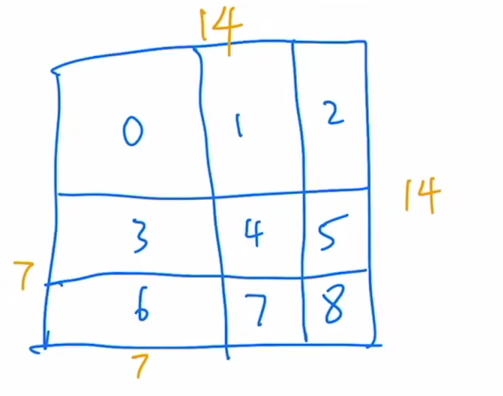
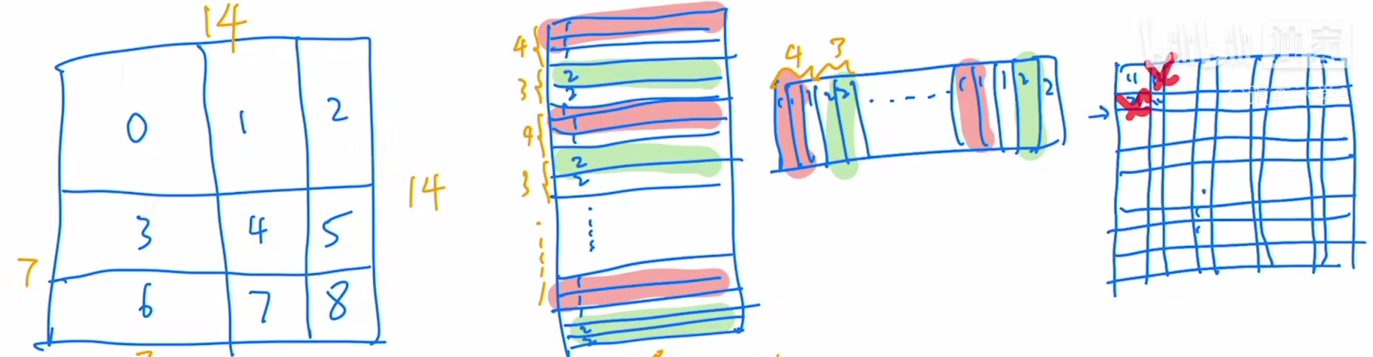
首先这里这个画的图是已经经过循环位移的,也就是说这块其实是原来的那个图,这块就相当于是已经从原来这块移过来的,就是刚才说的那个 a 这块其实也是原来左边的那个b,这块其实也是原来这块的那个上面的那个 c,但总之,这个就是已经经过了循环位移之后得到的,然后我们在中间画两条线就把它打成了4个窗口,也就这个窗口0、窗口1、窗口2和窗口3,整个这个特征图的这个大小,我们暂且说他是14*14的,也就是说这个高和宽这两边分别都有14个 patch,之所以化成4个窗口,也是因为每个窗口里应该有7个 patch,也就是说这块是7、这块是7,然后这个图里的这些012一直到8,并不是它里面真正的内容,而是我们用的一种序号,主要就是用来区分不同区域的,因为比如说对于这一大片区域来说,区域0也就是这个窗口0,它里面的元素呢都是相邻的,所以说它是可以互相去做自注意力的,所以这一大块里所有的这个patch,我们都用序号0来代替,但是作为这个窗口1而言,那左边的区域是原图,但它右边的区域2是从原来的这片区域里移过来的,所以说这两个区域是不相同的,它们之间就不应该做这个自注意力计算,所以我们就用两个序号去代替这两个区域里的 patch,那类似的对于这个窗口2而言,那下面的区域是从上面移过来的,所以说这块,我们也用两个序号去代替它,最复杂的就是最后这个窗口3了,因为它的这块区域是原图这块区域是从左边移过来的,这块区域是从上面移过来的,这片区域是从最左上角移过来的,所以说他这四个区域都不相同,它们之间都不应该去做这个自注意力,所以说我们就用四个序号去代替它。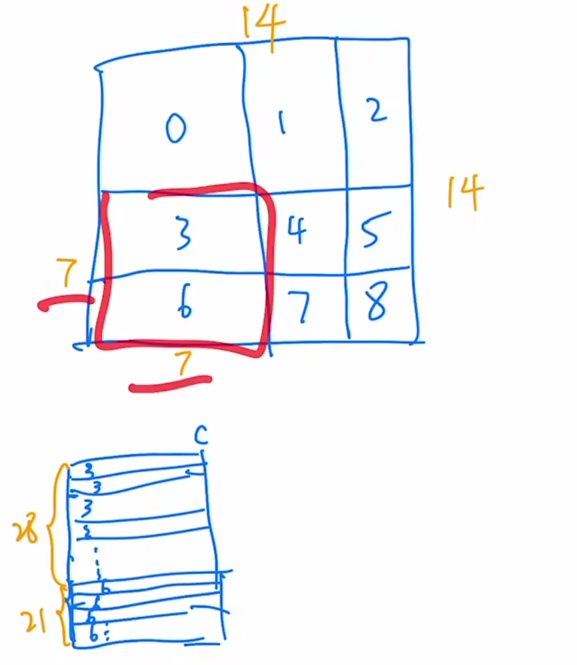
那现在我们先以左下角的这个窗口为例,讲一下整个这个自注意力是如何算的,以及这个掩码是如何加的。
首先我们知道在这个窗口内部,我们现在是有七七四十九个 patch,那每一个 patch 其实就是一个向量,那如果我们把这个现在这个窗口拉直,就会变成下面这个矩阵的样子,拉直就是说从这个 patch 开始,从左往右然后再往下,然后一点一点把所有的 patch全都拉直,变成一个向量,那也就意味着我们先得到的元素呢,就是3、3、3、3,都是3号位的元素,也就是都是3号序号的那个 patch,然后当这个3号循环完了之后,我们就来到了6号,所以下面呢就是6、6、6、6。那一共有多少个这个3号元素,因为你移动窗口的时候是移动窗口的一半,那在这里窗口因为是7,所以它每次移位是3,所以说,也就意味着这块呢是移动了3,那这块保留了4,那因为横边是7,所以说你一共就有7*4 ,28个这个3号位元素,也就意味着这块是28,那所以后面呢就是3*7 21,21个6号元素,所以就是说,当你把这个窗口拉直以后变成的向量就是这么一个向量,这个边呢一共有49个元素,前28个呢是3号patch,后21个是6号patch,这个就指的是向量的维度 c。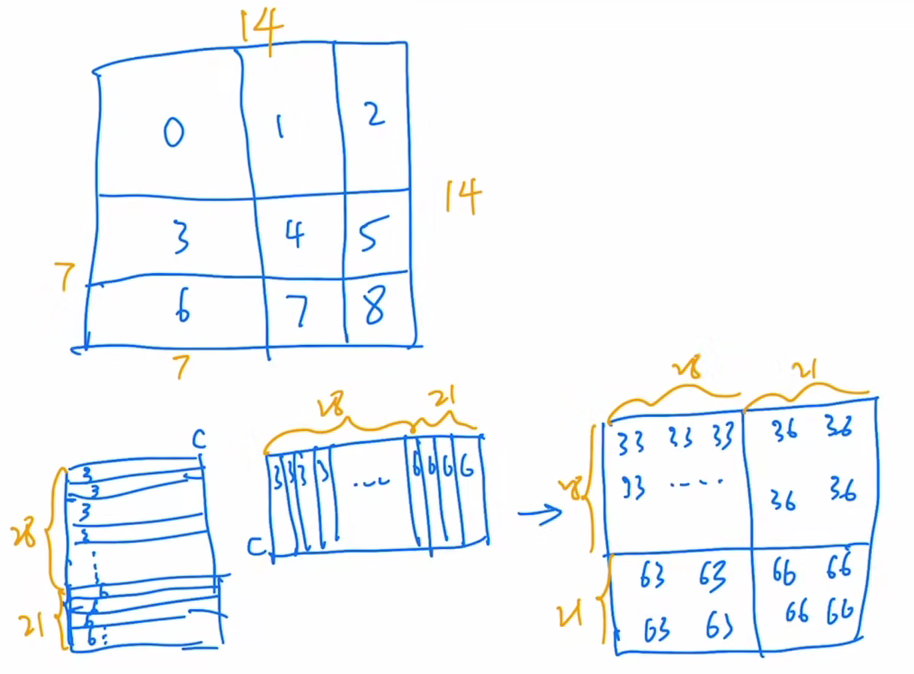
那有了这个拉直的向量之后,接下来就要做自注意力了,那自注意力就是自己跟自己去算这个attention,也就说把左边这个向量转置,得到这个向量,然后它俩之间相乘就可以了。接下来就是基本的这个矩阵乘法了,那就说我这个第一行就要跟我这边这个第一列相乘,也就是说我这个3号patch跟这边的3号patch去相乘,那结果我们就简单用33来代替,就说都是同样的这个 patch,也就说它们之间是可以去算这个自注意力的,然后紧接着呢还是这个行去跟这一列算还是33,所以就是第二个元素,然后还是33、33,然后一直到这块的时候,就算成了36,所以在这个第二块区域里,就是3号区域的元素和6号区域的元素在做这自注意力了,然而事实上,我们是不想让这两个区域内的元素去做这个自注意力操作的,也就是说回头我们是需要把这整个这个区域里的元素都Masked,然后我们继续做矩阵乘法,然后当这个矩阵的行数到这个6这的时候,刚开始我们是跟这个3去算,所以说就会得到63、63,然后这个6最后还会跟6去算,就得到了66、66。同样的道理,因为6和3是两个不同的区域,所以这里面算得的自注意力,我们也不想要也是要 Masked 掉的,而这两个区域(33、66)里算的自注意力,才是我们想要的,因为现在我们已经知道了哪个区域我们想要,哪个区域我们不想要,所以作者就针对这个形式设计了一个掩码的模板,也就是这个模板: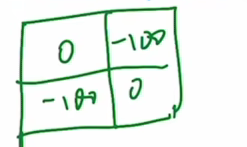
他的这个掩码这两个区域里都是0,然后这两个区域里都是-100,你其实可以理解成一个负的很大的数了,然后它让这两个矩阵呢去相加,因为原来的这个自制力矩阵里,它的值都是非常小的,所以当这两个区域的值加上这个-100之后就会变得是一个非常负的一个小数,然后再通过 softmax这个操作以后就变成0了,也就意味着说,我们把这两块区域里算得的自注意力就 masked 掉了。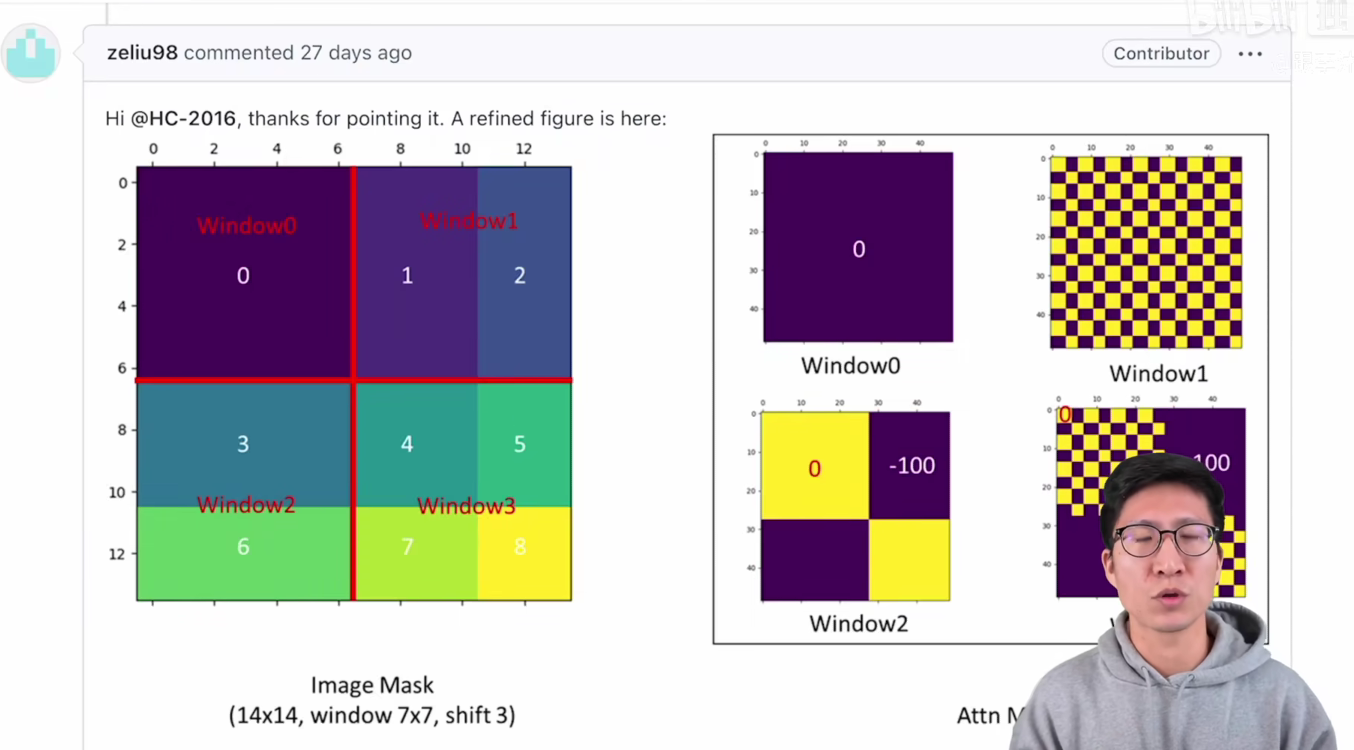
其实之前,也有很多人对这个掩码的方式不是很了解,所以就去 Swin Transformer这个官方的这个代码库里去问问题,作者也给出了很详细的回复,他在issue38里就做了这么一个掩码的可视化,左边这个图就是已经经过循环位移后的这个输入了,跟我们刚才画的也一样,里面有4个窗口也分成了0、1、2一直到8的这么多个区域,然后他把掩码的这个可视化画在了右边,那对于Window0来说,它里面其实不需要掩码的,所以这里面没有什么操作,那对于我们刚才刚讲过的这个Window 2里来说,他得到的这个掩码的可视化就跟我们刚才画的也是一样的。比如说左上和右下的这两个区域呢设成0,然后剩下的这两个区域设成-100,然后用这个模板去把算得的自注意力里面不该要的值去 mask 掉。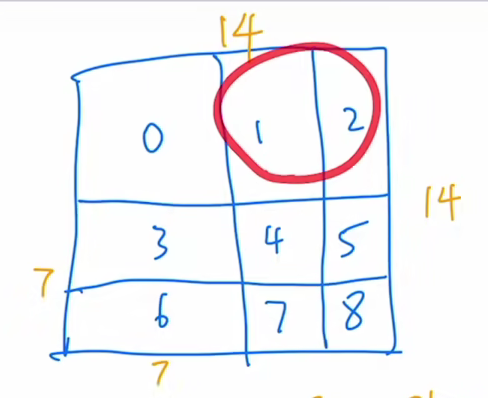
那接下来,我们再看一下这个窗口里的自注意力又是如何算的,它的掩码的这模板是如何得到的。
同样的,我们先把这个窗口里的元素都拉直,那这个拉直的过程中跟刚才那个窗口就不太一样,因为这里面你是先有四个1的元素,然后再有三个二的元素,然后又有四个一、三个二、四个一、三个二,所以就跟这个图里画了一样,就是它总是四个一、三个二、四个一、 三个二,也就是说,它的形式是一种条纹状的形式。接下来我们再去做这个自注意力,就把这个向量呢然后转置过来,然后去做矩阵乘法,那所以说最后得到自注意力,就会类似长这样,那刚开始就都是1号元素在和1号元素相乘,然后紧接就是1号和2号相乘,然后紧接就是1号跟1号,然后又是1号跟2号循环往复,那如果我们就在这一个小窗口里看的话,那左上角的这个1是我们要的,这块的这个22是我们要的,但是这里的12和21就不是我们要的了,我们回头就要想办法把它Masked。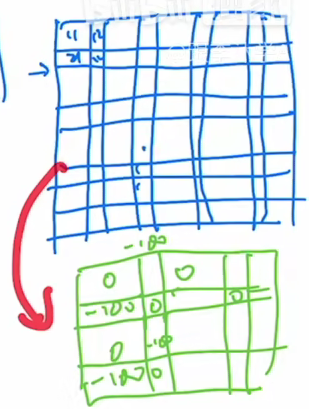
那所以说跟刚才也一样,那我们需要的地方这个掩码就是0,那不需要的地方,我们就把它设成-100,那接下来,让这个原来的自注意力和这个掩码相加,最后经过一层 softmax 操作,我们就能把想要的自注意力值留下,不想要的值就 mask 掉了。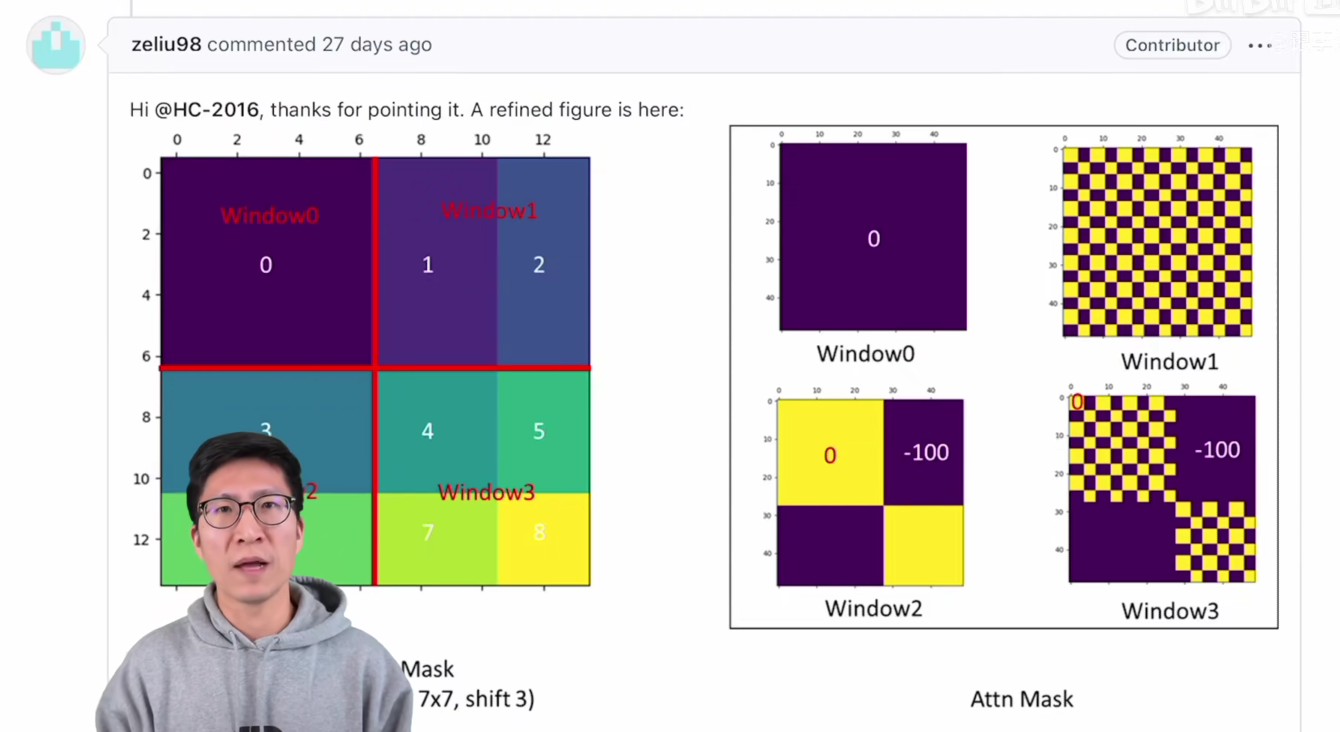
那我们再回过头来看作者提供的这个mask 的可视化,我们就会发现对于这个窗口而言,作者最后给出的可视化就是像我们刚才画出来的一样,这是一个横竖条纹状的模板,那最后这个区域也就是这个窗口3,我们就不多说了,他其实就是之前窗口1和窗口2的一个合体,最后的这个可视化就是这个看起来是不是相当的复杂,但是作者就通过这种巧妙的循环位移的方式,也通过这种巧妙设计的掩码模板,从而实现了只需要一次前向过程,就能把所有需要的这个自注意力值都算出来,而且只需要计算4个窗口的,就说窗口的数量没有增加计算复杂度,也没有增加非常高效的完成了这个任务。
那在方法的最后一节也就是3.3节,作者就大概介绍一下,他们提出的这个 Swin Transformer的几个变体,分别是四种就是 Swin Tiny、Swin Small、Swin Base和 Swin Large。
作者这里说这个 Swin Tiny的计算复杂度跟这个 ResNet-50 差不多,然后 Swin Small 的这个复杂度跟 ResNet-101 是差不多的,这样主要是想去做一个比较公平的对比,那这些变体之间有哪些不一样呢,其实主要不一样的就是这两个超参数,一个就是这个向量维度的大小 c,另一个就是每个 stage里到底有多少个 transform block,这里其实就跟残差网络就非常像了,残差网络也是分成了四个 stage,然后每个 stage有不同数量的这个残差块。
实验
接下来我们就一起来看一下文章的最后一部分,叫实验部分。
首先作者就先说一下分类上的实验,他这里一共两种预训练的方式,第一种就是在正规的这个ImageNet-1K上去做训练,也就是那个有128万张图片,有1000个类的那个数集,然后第二种方式就是在更大的这个ImageNet-22K,这个数据集上去做预训练,这个数据集就有1,400万张图片,而且里面呢有2万多个类别,当然这里面不论你是用ImageNet-1K去做预训练,还是用ImageNet-22K去做预训练,最后测试的结果都是在ImageNet-1K的那个测试集上去做的。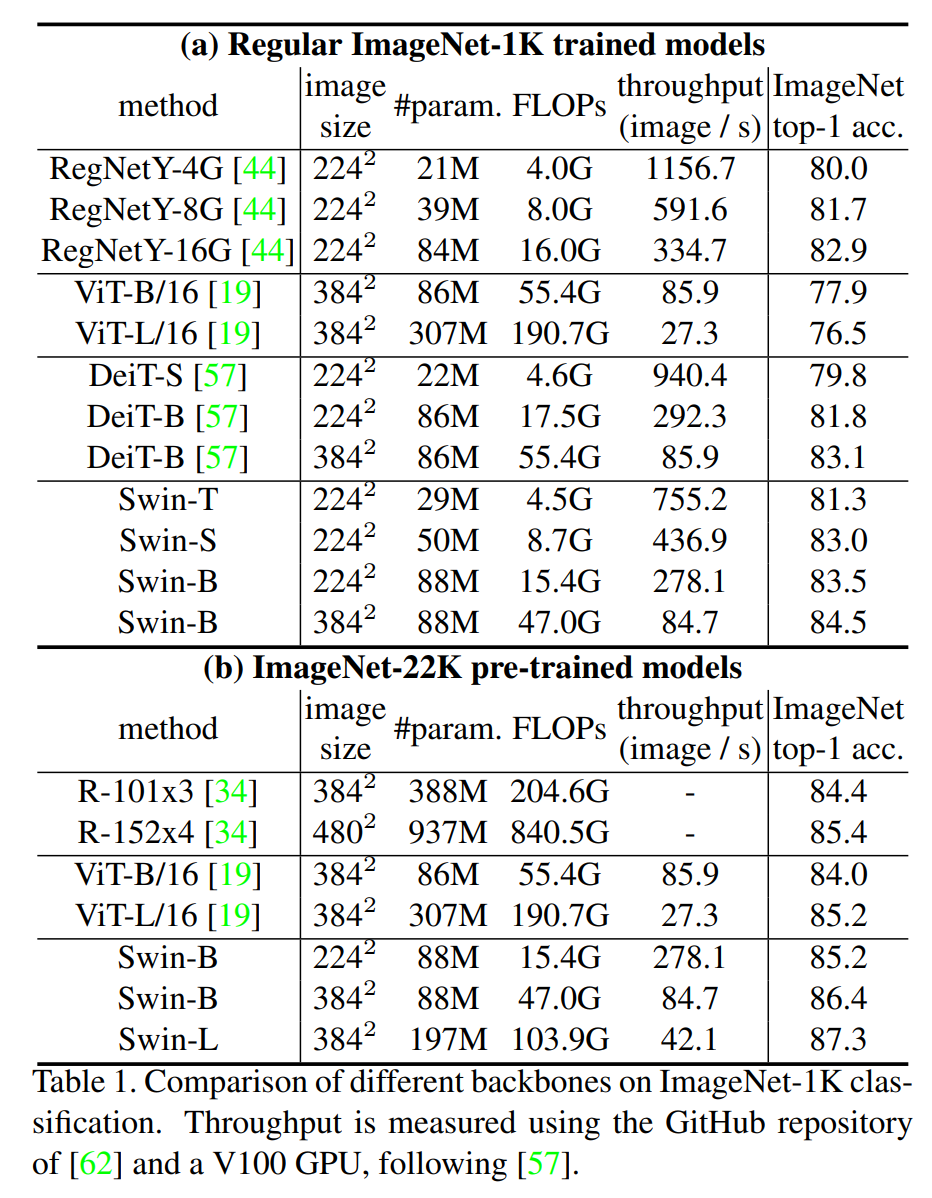
所有的结果作者都列在了这个表1里上半部分就是ImageNet-1K预训练的模型结果,那下半部分就是先用ImageNet-22K去预训练,然后又在ImageNet-1K上去做微调,最后得到的结果。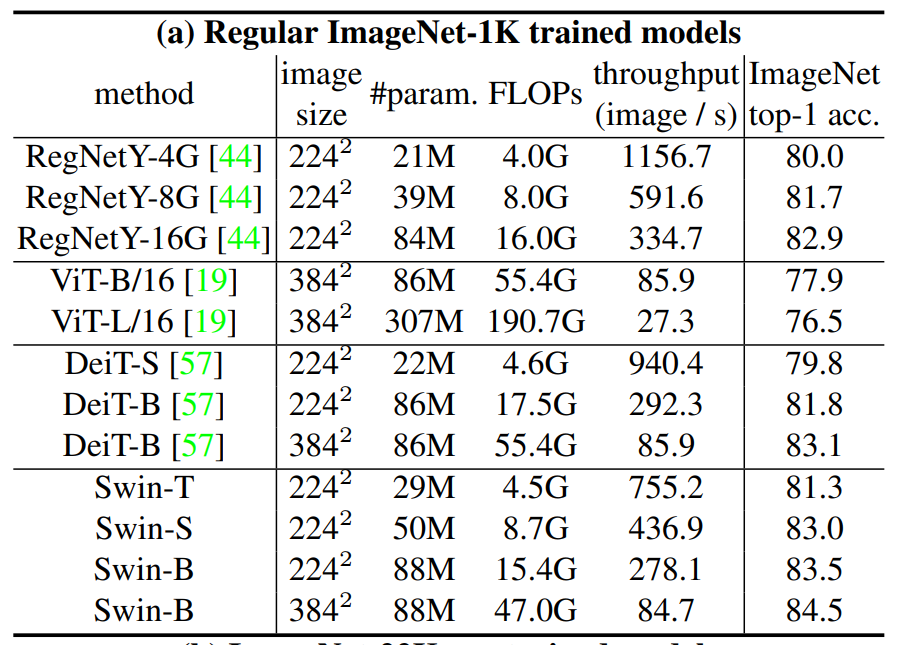
那在表格的上半部分,作者先是跟之前最好的那些卷积神经网络去做了一下对比,那这个RegNet是之前 facebook他们就用NASA搜出来的这种模型,然后EfficientNet是 google 用NASA搜出来的模型,这两个都算之前表现非常好的模型了,他们这个性能最高会到84.3,然后接下来作者就写了一下之前的这个 Vision Transformer会达到一个什么效果,那对于 ViT 这里来说,我们之前在讲 ViT 论文的时候也提过,因为它没有用很好的这个数据增强,而且缺少这种偏置归纳,所以说它的结果是比较差的,只有70多,然后换上 DeiT 之后,因为用了更好的数据增强和模型蒸馏,所以说 DeiT Base这个模型也能取得相当不错的结果,能到83.1,当然 Swin Transformer能更高一些,Swin Base 最高能到84.5,就是稍微比之前最好的那个卷积神经网络高那么一点点,就比84.3高了0.2,虽然之前表现最好的这个EfficientNet的模型是在600*600的这个图片上做的,而 Swin Base 是在384*384的图片上做的,所以说EfficientNet有一些优势,但是从模型的参数和这个计算的 FLOPs 上来说,EfficientNet 只有66M,而且只用了 37G 的这个 FLOPs,但是 Swin Transformer是用了88M的模型参数,而且用了47G 的这个 FLOPs,所以总体而言呢是伯仲之间。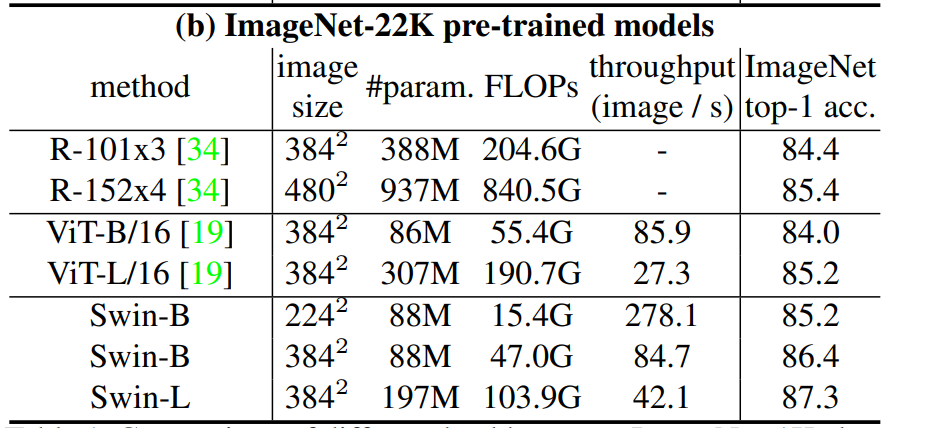
那接下来再看表格的下半部分,就是用 ImageNet-22k 去做预训练,然后再在ImageNet-1k上微调,最后得到的结果,这里我们看到,一旦使用了更大规模的数据集,原始的这个标准的 ViT 的性能也就已经上来了,对于ViT large来说,它已经能得到85.2的准确度了,这相当高了,但是Swin Large更高,Swin Large最后能到87.3,这个是在不使用JFT-300M,就是这种特别大规模数据集上得到的结果,所以还是相当高的。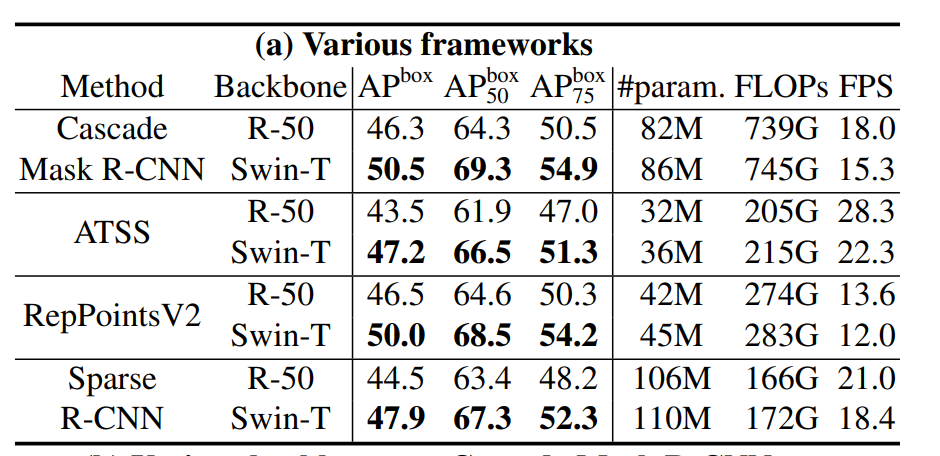
那做完了分类,接下来就是看目标检测的结果了,作者这里是在 COCO 这个数据集上训练并且进行测试的,他首先在这个表2 a 里面测试一下在不同的这个算法框架下Swin Transformer到底比卷积神经网络要好多少,因为他主要是想证明 Swin Transformer是可以当做一个通用的骨干网络来使用的,所以他这里比如说他用了 Mask R-CNN,然后ATSS、RepPointsV2 或者SparseR-CNN,这些都是表现非常好的一些算法,然后在这些算法里,过去的这个骨干网络选用的都是 ResNet-50,现在他就替换成了 Swin Tiny,那我们刚才也讲Swin Tiny 的这个参数量和 FLOPs 跟 ResNet-50是比较一致的,我们从后面的这些对比里也可以看出来,所以他们之间的比较是相对比较公平的,然后我们可以看到Swin Tiny 对ResNet-50 是全方位的碾压,就在四个算法上都超过了它,而且这个超过的幅度呢也是比较大的,比如说在这里超过4个点、4个点、4个点。
接下来,作者又换了一个方式去做这个测试,他现在是选定了一个算法,就是选定了Cascade Mask R-CNN 这个算法,然后他去换更多的不同的这个骨干网络,比如说呢他就换了 DeiT-S、ResNet-50或者 ResNet-101,这里他也分了几组,比如说这里他就选的是 Swin Tiny,因为他们之间的这个模型参数和FLOPs 是比较接近的,然后接下来他是比较了这个 Swin Small和 Swin Based结果,我们可以看出来,在相似的这个模型参数和相似的这个 Flops 之下,Swin Transformer都是比之前的这个骨干网络要表现好的。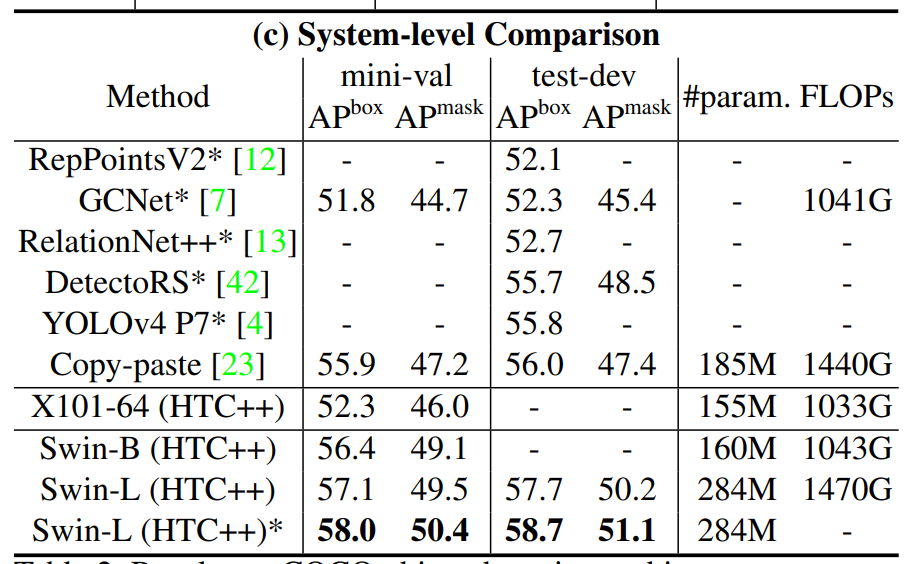
接下来作者又做了第三种测试的方式,就是这个 table 2里的这个 c,就是系统层面的这个比较,那这个层面的比较就比较狂野了,就是现在我们追求的不是公平比较了,你什么方法都可以上,你也可以使用更多的数据,你也可以使用更多的数据增强,你甚至可以在测试的时候使用这个 test time augmentation,就是 TTA 的方式,那我们可以看到之前最好的这个方法,Copy-paste它在 COCO Validation Set上的结果是55.9,在 Test Set上结果是56,而这里如果我们跟最大的这个Swin Transformer、 Swin Large 比,它的结果分别能达到58和58.7,这都比之前高了两到三个点。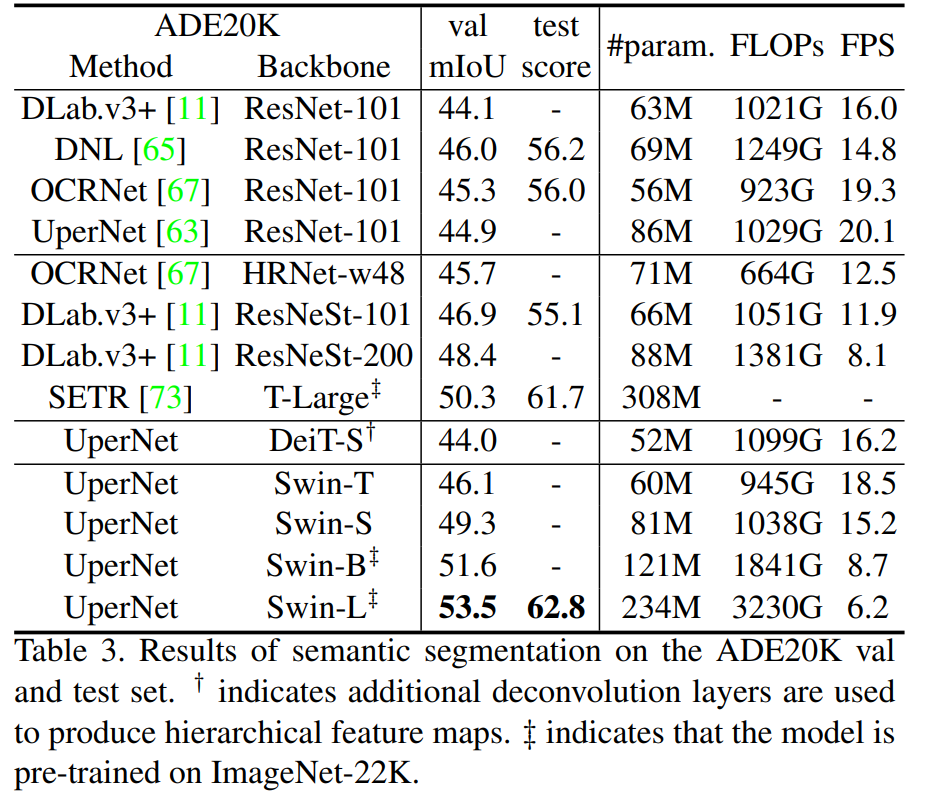
那第三个实验,作者就选择了这个语义分割里的ADE20K数据集,就在这个表3里,我们可以看到之前的这些方法,一直到这个 DeepLab V3、ResNet。
其实都用的是卷积神经网络,然后这个 ResNet 其实也是我们组之前的一个工作,我们当时最高是能刷到48.4的这个结果,也是提升了很多,因为我们可以看到之前的这些方法,其实都在44、45左右徘徊,我们也是直接涨了两个多点。
但是紧接着Vision Transformer 就来了,那首先就是这个 SERT 这篇论文,他们用了 ViT Large,所以就取得了50.3的这个结果,然后Swin Transformer Large也取得了这个53.5的结果,就刷的更高了,但这里我想指出的,其实作者这里也有标注,就是有两个符号的这个,他的意思是说,这些模型是在ImageNet-22K这个数据集上去做预训练,所以他们的结果才这么好。
那最后我们就是来讲一下这个消融实验。
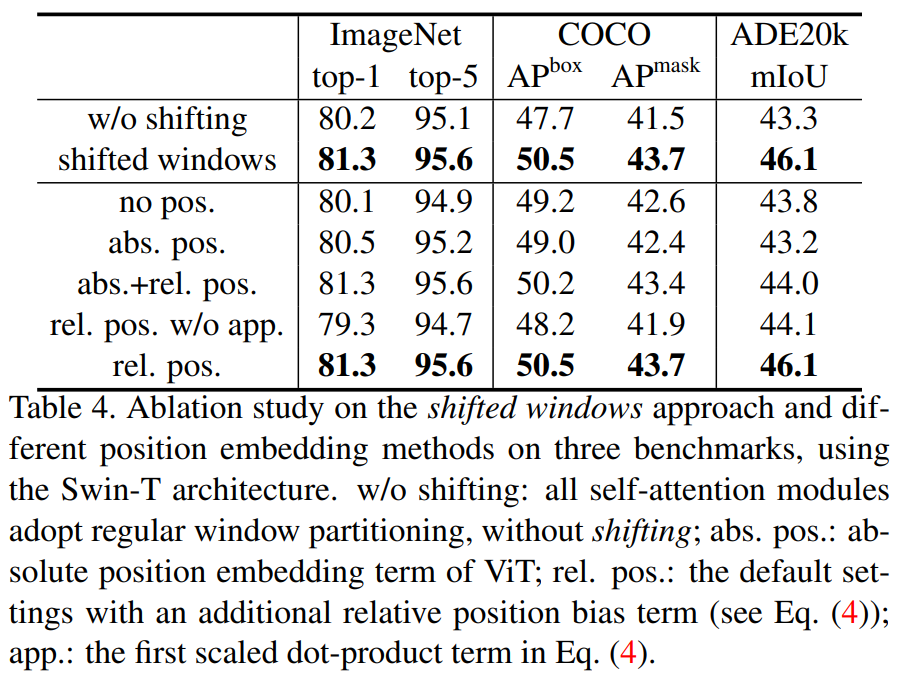
作者把消融实验都放到这个表4里了,主要就是想说一下这个移动窗口以及这个相对位置编码到底对 Swin Transformer 有多有用,那这里我们可以看到,如果光说分类任务的话,其实不论是移动窗口还是这个相对位置编码,它的提升相对于基线来说也没有特别明显,比如说这里呢从80.2到81.3提了1.1点,然后这里呢从80.几提升到81.3,也提了一个点,当然在ImageNet的这个数据集上,提升一个点也算是很显著了,但是他们更大的帮助主要是出现在这个下游任务里,就是 COCO和ADE20k这两个数据集上也就是目标检测和语义分割这两个任务上,我们可以看到,用了这个移动窗口和用了这个相对位置编码以后都会比之前大概高了3个点左右,那这个提升是非常显著的,这个想起来当然也是合理的,因为如果你现在去做这种密集型预测任务的话,你就需要你的特征对这个位置信息更敏感,而且更需要这个周围的这个上下文关系,所以说通过移动窗口提供的这种窗口和窗口之间的互相通信,以及在每个Transformer block都去做这种更准确的相对位置编码,肯定是会对这种下游任务大有帮助的。
总结
最后我们一起来快速的点评一下这篇论文,并且讲一些我个人的看法。
我们继续回到他的这个官方代码库,我们会发现除了作者团队他们自己在过去半年中刷了那么多的任务,比如说我们最开始讲的这个自监督的Swin Transformer,还有 Video Swin Transformer 以及Swin MLP,同时 Swin Transformer 还被别的研究者用到了不同的领域。那在这里作者就简单罗列了一下,比如说Swin Transformer 和 StyleGAN 的结合就变成了 StyleSwing,然后还有拿它去做人脸识别的,还有拿它去做这种 low level的视觉任务的,比如说图片超分、图片恢复,就有了 SwinIR 这篇论文,然后还要拿 Swin Transformer去做这个 person reID 这个任务的。
所以说 Swin Transformer 真的是太火,真的是在视觉领域大杀四方,感觉以后每个任务都逃不了跟 Swin 要比一比,而且因为 Swin 这么火,所以说其实很多这个开源包里都有 Swin 的这个实现,比如说作者这里也列出来,这百度的PaddlePaddle其实里面是有的,而且视觉里现在比较火的这个pytorch-image-models,就是 Timm 这个代码库,里面也是有 Swin 的实现的,同时Hugging Face 我估计也是有的。
虽然我前面已经说了很多 Swin Transformer的影响力已经这么巨大了,但其实他的影响力远远不止于此,他论文里这种对卷积神经网络、 对Transformer还有对 MLP这几种架构深入的理解和分析是可以给更多的研究者带来思考的,从而不仅可以在视觉领域里激发出更好的工作,而且在多模态领域里也能激发出更多更好的工作。