04数据操作+数据预处理
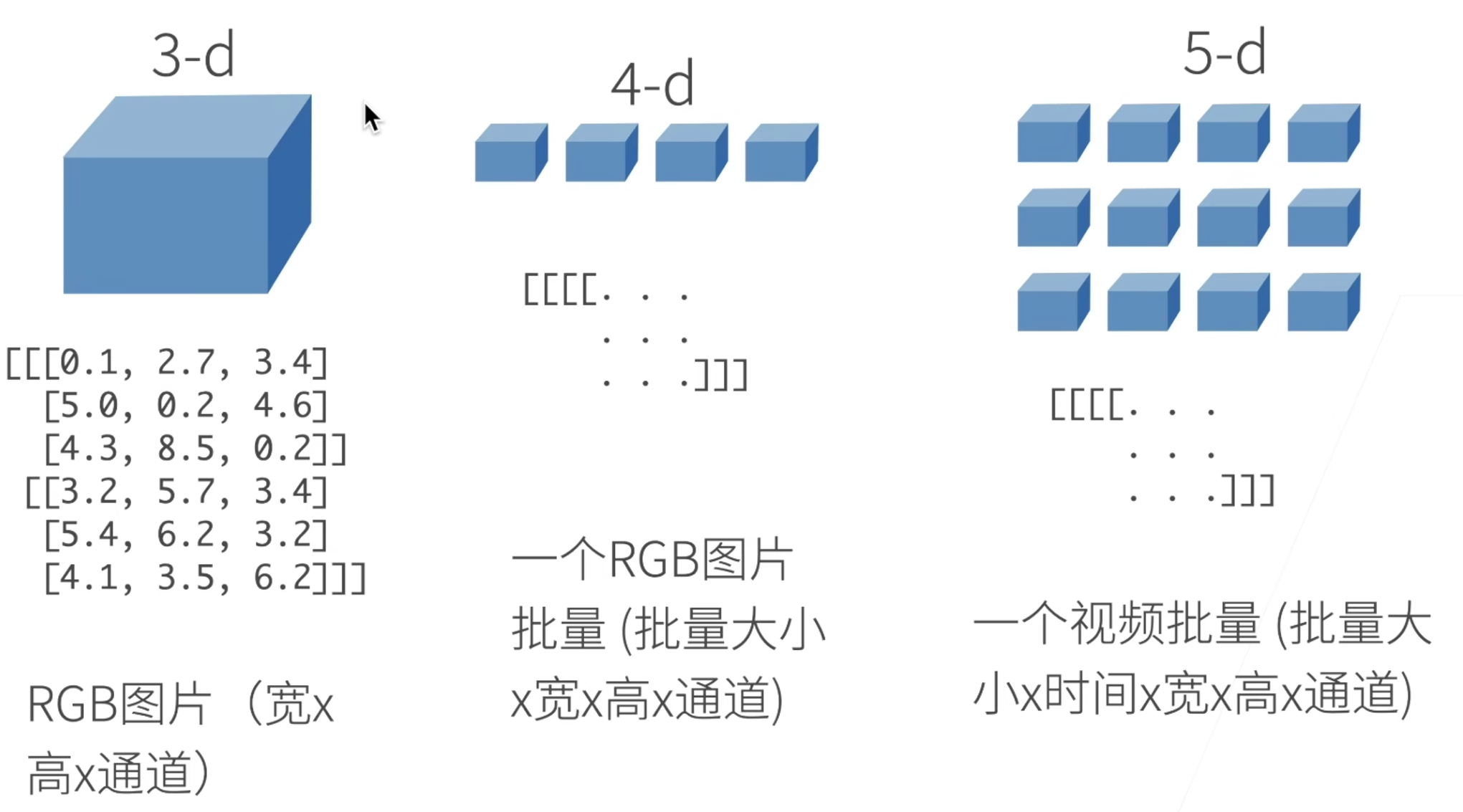
N维数组样例
- N维数据是机器学习和神经网络的主要数据结构。

创建数组
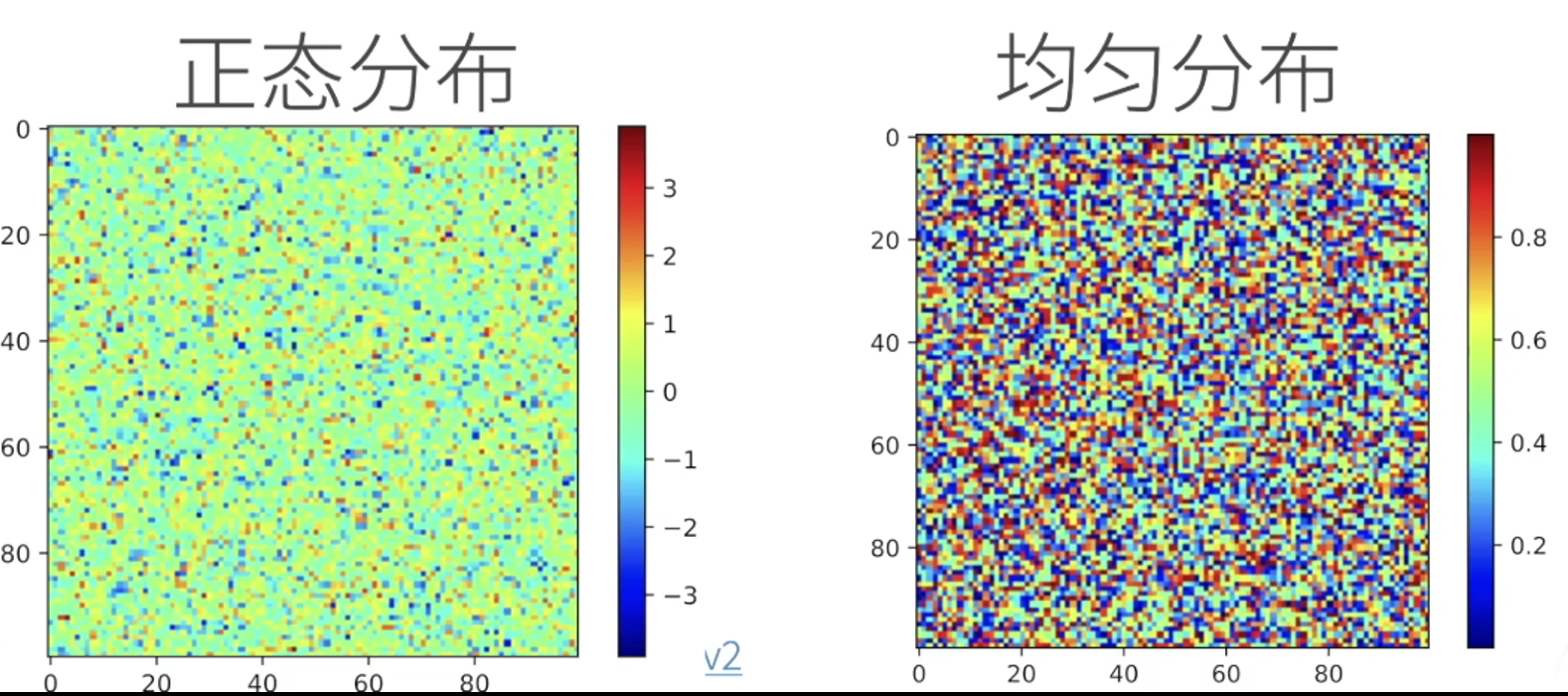
- 创建数组需要
- 形状:例如3x4矩阵
- 每个元素的数据类型:例如32位浮点数
- 每个元素的值,例如全是0,或者随机数
访问元素
一个元素:[1, 2]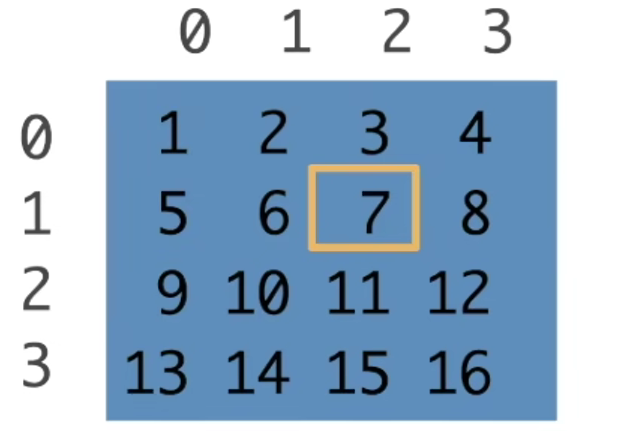
一行:[1, :]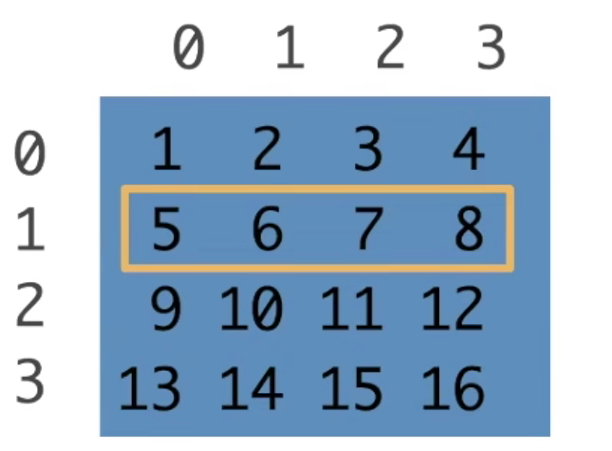
一列:[:, 1]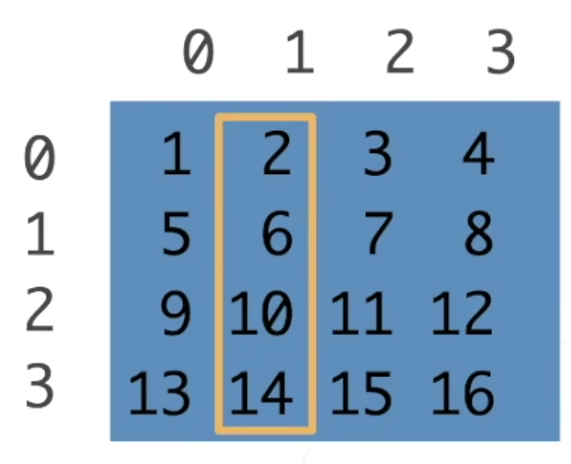
子区域:[1:3, 1:]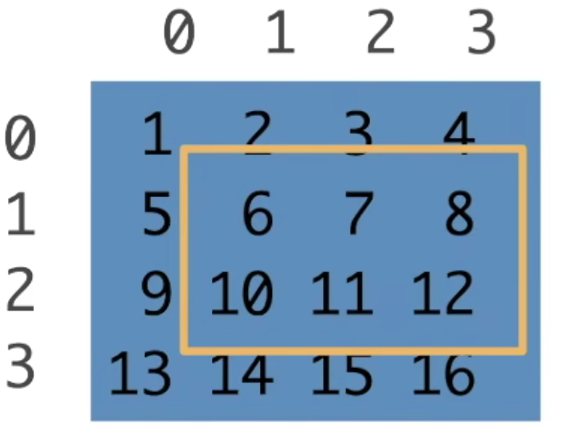
子区域:[::3, ::2]跳着访问,每三行一跳,每两列一跳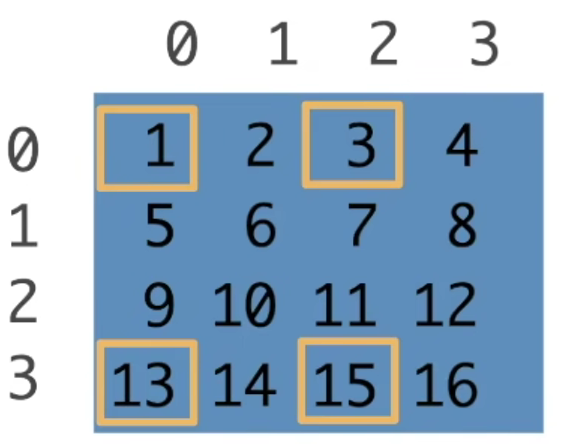
数据操作
首先,我们导入torch
1 | import torch |

张量表示一个数值组成的数组,这个数组可以有多个维度
1 | x = torch.arange(12) |

我们可以通过张量的shape属性来访问张量的形状和张量中元素的总数
1 | x.shape |

1 | x.numel() |

要改变一个张量的形状而不改变元素数量和元素值,我们可以调用reshape函数
1 | x = x.reshape(3, 4) #三行四列 |

使用全0、全1、其他常量或者从特定分布中随机采样的数字
1 | torch.zeros((2, 3, 4)) #全0 |

1 | torch.ones((2, 3, 4)) #全1 |

通过提供包含数值的Python列表(或嵌套列表)来为所需张量中的每一个元素赋予确定值
1 | torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) |

1 | torch.tensor([[[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]]) |
1 | torch.tensor([[[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]]).shape |
深度为1,3行4列
常见的标准算术运算符(+、-、*、/ 和 **)都可以升级为按元素运算
1 | x = torch.tensor([1.0, 2, 4, 8]) |

按元素方式应用更多的计算
1 | torch.exp(x) |

我们也可以把多个张量连结在一起
1 | x = torch.arange(12, dtype=torch.float32).reshape((3, 4)) |

通过逻辑运算符构建二元张量
1 | x == y |

对张量中的所有元素进行求和会产生一个只有一个元素 的张量
1 | x.sum() |

即使形状不同,我们仍然可以通过调用广播机制来执行按元素操作
1 | a = torch.arange(3).reshape((3, 1)) |

可以用[-1]选择最后一个元素,可以用[1: 3]选择第二个和第三个元素
1 | x[-1], x[1: 3] |

除读取之外,我们还可以通过指定索引来将元素写入矩阵
1 | x[1, 2] = 9 |

为多个元素赋值相同的值,我们只需要索引所有元素,然后为它们赋值
1 | x[0:2, :] = 12 |

运行一些操作可能会导致为新的结果分配内存
1 | before = id(y) |

执行原地操作
1 | z = torch.zeros_like(y) |

如果在后续计算中没有重复使用x,我们也可以使用x[:] = x + y或x += y来减少操作的内存开销
1 | before = id(x) |

转换为NumPy张量
1 | A = x.numpy() |

将大小为1的张量转换为Python标量
1 | a = torch.tensor([3.5]) |

数据预处理
创建一个人工数据集,并存储在csv(逗号分隔值)文件
1 | import os |

从创建的csv文件中加载原始数据集
1 | import pandas as pd |
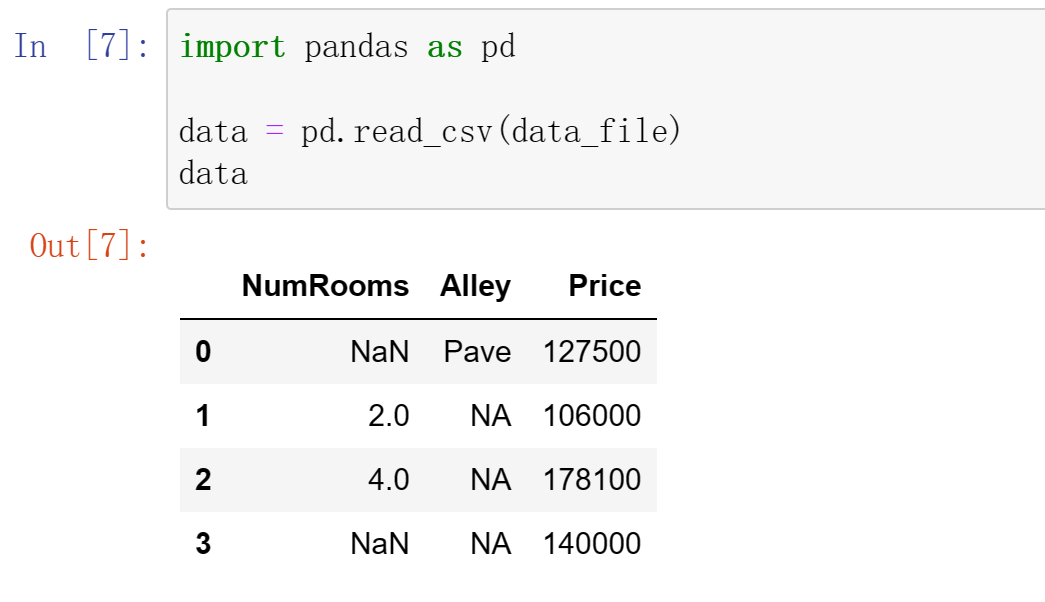
为了处理缺失的数据,典型的方法包括插值和删除,这里,我们将考虑插值
1 | inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] |
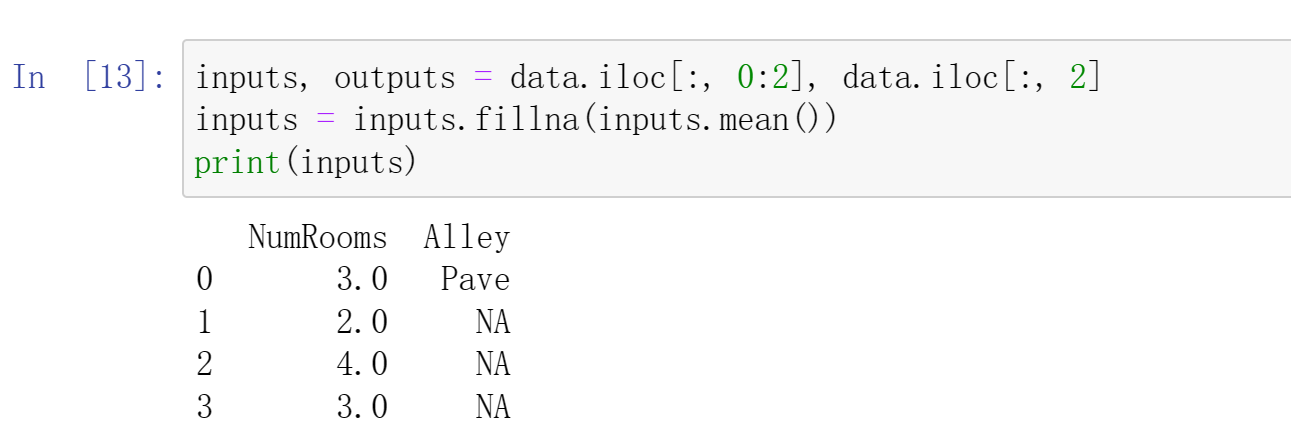
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别
1 | inputs = pd.get_dummies(inputs, dummy_na=True) |
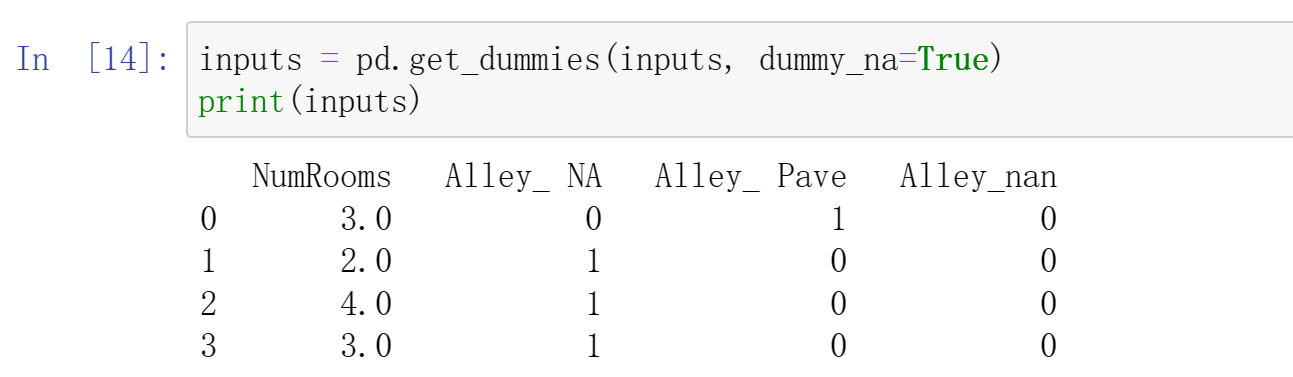
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式
1 | import torch |
