Underwater object detection algorithm based on feature enhancement and progressive dynamic aggregation strategy
基于特征增强和渐进动态聚合策略的水下目标检测算法
Abstract
To solve the problems that the conventional object detector is hard to extract features and miss detection of small objects when detecting underwater objects due to the noise of underwater environment and the scale change of objects, this paper designs a novel feature enhancement & progressive dynamic aggregation strategy, and proposes a new underwater object detector based on YOLOv5s. Firstly, a feature enhancement gating module is designed to selectively suppress or enhance multi-level features and reduce the interference of underwater complex environment noise on feature fusion. Then, the adjacent feature fusion mechanism and dynamic fusion module are designed to dynamically learn fusion weights and perform multi-level feature fusion progressively, so as to suppress the conflict information in multiscale feature fusion and prevent small objects from being submerged by the conflict information. At last, a spatial pyramid pool structure (FMSPP) based on the same size quickly mixed pool layer is proposed, which can make the network obtain stronger description ability of texture and contour features, reduce the parameters, and further improve the generalization ability and classification accuracy. The ablation experiments and multi-method comparison experiments on URPC and DUT-USEG data sets prove the effectiveness of the proposed strategy. Compared with the current mainstream detectors, our detector achieves obvious advantages in detection performance and efficiency.针对传统目标检测器在检测水下目标时,由于水下环境噪声和目标尺度变化等原因,存在特征提取困难和小目标漏检的问题,设计了一种新的特征增强渐进动态聚合策略,提出了一种基于YOLOv 5s的水下目标检测器。首先设计了特征增强选通模块,有选择地抑制或增强多层次特征,降低水下复杂环境噪声对特征融合的干扰。然后,设计了相邻特征融合机制和动态融合模块,动态学习融合权值,逐步进行多尺度特征融合,以抑制多尺度特征融合中的冲突信息,防止小目标被冲突信息淹没。最后,提出了一种基于相同尺寸快速混合池层的空间金字塔池结构(FMSPP),使网络获得更强的纹理和轮廓特征描述能力,减少参数,进一步提高泛化能力和分类精度。在URPC和DUT-USEG数据集上的烧蚀实验和多方法对比实验证明了该策略的有效性。与目前主流的检测器相比,该检测器在检测性能和效率上都有明显的优势。
1. Introduction
In recent years, marine information processing technology has developed vigorously, and the application of underwater object detection technology has become more and more extensive, involving naval coastal defense, fishery and aquaculture, salvage of sunken ships on the seabed, research of marine ecosystem and other fields. Underwater optical image has high resolution and abundant information, which is very suitable for close range underwater object detection. The special underwater imaging environment leads to the problems of color distortion, too much interference noise, blurred texture features and low contrast in underwater images [1] . So, how to accurately, quickly and stably detect objects with poor image visibility is a huge challenge [2] .近年来,海洋信息处理技术蓬勃发展,水下目标探测技术的应用越来越广泛,涉及到海军海防、渔业养殖、海底沉船打捞、海洋生态系统研究等多个领域。水下光学图像分辨率高、信息量丰富,非常适合近距离水下目标探测。特殊的水下成像环境导致水下图像存在颜色失真、干扰噪声多、纹理特征模糊、对比度低等问题[1]。因此,如何准确、快速、稳定地检测图像可见性差的物体是一个巨大的挑战[2]。
With the continuous iteration of convolutional neural network, researchers have proposed many underwater object detection methods based on deep learning, which are fast, high-precision and have good generalization performance. Xu et al. [3] proposed an improved ocean object detector based on attention-based spatial pyramid pool network and bidirectional feature fusion strategy to alleviate the problem of feature weakening. Lin et al [4] proposed an underwater image enhancement method to improve the detection accuracy of occluded and blurred objects. Liu et al. [5] constructed a universal underwater object detector using many underwater data sets, which has good environmental adaptability. Zhou et al. [6] proposed a new algorithm by combining important environmental features, and the average recognition rate of this model is 80.07%. Zhangyan et al. [7] proposed an algorithm based on channel attention and feature fusion, which effectively improved the detection accuracy. Li et al. [8] proposed an algorithm by combining channel attention, which improved the robustness of the detector. Wang et al [9] proposed an underwater object edge detection method based on ant colony optimization and reinforcement learning.随着卷积神经网络的不断迭代,研究人员提出了许多基于深度学习的水下目标检测方法,这些方法速度快,精度高,泛化性能好。Xu等人[3]提出了一种基于注意力的空间金字塔池网络和双向特征融合策略的改进海洋目标检测器,以缓解特征弱化问题。Lin等人[4]提出了一种水下图像增强方法,以提高遮挡和模糊目标的检测精度。Liu等人[5]利用多个水下数据集构建了一个通用的水下目标探测器,具有良好的环境适应性。Zhou等人[6]提出了一种结合重要环境特征的新算法,该模型的平均识别率为80.07%。Zhangyan等人[7]提出了一种基于通道注意和特征融合的算法,有效提高了检测精度。Li等人[8]提出了一种结合信道注意力的算法,提高了检测器的鲁棒性。Wang等[9]提出了一种基于蚁群优化和强化学习的水下目标边缘检测方法。
Now, the underwater image object detector still faces two challenges: 1) small objects are fuzzy and tiny 2) The distinction between object and background is low. The underwater object scale is quite different, and there are many small objects in the underwater scene. Due to the existence of suspended matter and uneven illumination in the underwater environment, it is more difficult to detect small objects, as (a) and (b) in Fig. 1 . At present, in the mainstream public data set, the number of small objects is far less than that of large objects, so that the small object has less influence on the loss function, and the direction of network con vergence is constantly tilting towards the larger objects. There are still prominent problems of missed detection and false detection of small objects. The underwater environment is complex, and due to image degradation and natural camouflage, the appearance and physical structure of some underwater objects in images are highly similar to the surrounding environment, as (c) and (d) in Fig. 1 , which is an important challenge for underwater image object detection.目前,水下图像目标检测还面临两个挑战:1)小目标的模糊性和微小性; 2)目标与背景的区分度低。水下物体尺度差异较大,水下场景中有许多小物体。由于水下环境中悬浮物的存在和光照不均匀,检测小物体更加困难,如图1中的(a)和(b)。目前,在主流的公共数据集中,小对象的数量远远少于大对象,从而小对象对损失函数的影响较小,网络汇聚的方向不断向大对象倾斜。小目标的漏检、误检问题仍然比较突出。水下环境复杂,由于图像退化和自然伪装,图像中某些水下目标的外观和物理结构与周围环境高度相似,如图1中的(c)和(d),这是水下图像目标检测的重要挑战。
Fig. 1. Two Challenges of Underwater Image Object Detection.
图1 水下图像目标检测的两个挑战。
In summary, this paper proposes a novel underwater object detection method, which specifically improves the detection accuracy by designing the following strategies:综上所述,本文提出了一种新颖的水下目标检测方法,具体通过设计以下策略来提高检测精度:
1)Firstly, a new feature enhancement gating module is designed, which is used to capture the important information of channel, space and global dimensions of features. And, it expands the receptive field of features, selectively enhances or suppresses multi-scale features extracted by feature pyramid network (FPN), reduces the interference of background information on subsequent fusion results, and improves the ability to express features.1)首先,设计了一种新的特征增强门控模块,用于捕获特征的通道、空间和全局维度的重要信息;扩大特征感受野,选择性地增强或抑制特征金字塔网络(feature pyramid network, FPN)提取的多尺度特征,减少背景信息对后续融合结果的干扰,提高特征表达能力。
2)Then, a feature dynamic fusion module is designed to aggregate the features of adjacent layers to obtain semantic context information, which can establish the relationship between the object scale of the input image and feature fusion, and dynamically learn the fusion weight according to the object scale. Moreover, a simple and effective progressive aggregation strategy is proposed to avoid the loss of small object features caused by hopping feature fusion and realize the progressive aggregation of multi-level features.2)然后,设计了特征动态融合模块,对相邻层的特征进行聚合,获得语义上下文信息,可以建立输入图像的对象尺度与特征融合之间的关系,并根据对象尺度动态学习融合权值。此外,提出了一种简单有效的渐进式聚合策略,避免了跳变特征融合造成的小目标特征丢失,实现了多层次特征的渐进式聚合。
3)Finally, aiming at the problem that the texture of underwater objects is not clear and the discrimination between underwater objects and the surrounding environment is low, this paper proposes a fast spatial pyramid mixed pooling module (FMSPP) composed of mixed pooling layers of the same size to replace the spatial pyramid pooling (SPP) module composed of maximum pooling layers of different sizes in the original yolov5s model, so that the network can obtain stronger texture and contour feature description ability.3)最后,针对水下目标纹理不清晰、水下目标与周围环境区分度低的问题,本文提出了一种由大小相同的混合池化层组成的快速空间金字塔混合池化模块(FMSPP),以取代原yolov5s模型中由大小不同的最大池化层组成的空间金字塔池化模块(SPP),从而使网络获得更强的纹理和轮廓特征描述能力。
2. Related works
Underwater object detection technology .水下目标探测技术。
Object detection algorithms based on deep learning are mainly divided into two cate gories: One-stage detection algorithm based on regression thought; Two-stage detection algorithm based on generating candidate regions, first extracts candidate regions from the input image, and then realize object classification and position correction by these candidate regions. Li et al. [10] applied high-precision Fast-R-CNN to detect fish in complex underwater environment. One-stage detection algorithm directly uses convolutional neural network to classify and correct the position of the object from the input image. Compared with double-step detection algorithm, one-stage detection algorithm greatly reduces the calculation cost of the model because it doesn’t need to generate candidate areas before classifying and correcting the position of the object, which meet the needs of rapid underwater object detection. Therefore, many researchers study underwater object detection algorithm based on one-stage detection. Sung et al. [11] proposed a model based on YOLO, the classification accuracy rate reached 93%. Liu Ping et al. [12] based on YOLOv3 algorithm and using GAN (Generative Adversarial Networks) model realized the identification of marine organisms. Chen et al. [2] proposed a method of underwater biological objects in low light based on improved YOLOV5s to solve the problem of low biometric identification accuracy caused by serious light attenuation in underwater, complex image environment and moving shooting equipment.基于深度学习的目标检测算法主要分为两类:基于回归思想的一级检测算法;基于候选区域生成的两级检测算法,首先从输入图像中提取候选区域,然后利用这些候选区域实现目标分类和位置校正。Li等人[10]应用高精度Fast-R-CNN在复杂的水下环境中检测鱼类。一级检测算法直接使用卷积神经网络从输入图像中分类并校正目标的位置。与双步检测算法相比,一步检测算法在对目标进行分类和位置校正之前不需要生成候选区域,大大降低了模型的计算开销,满足了快速水下目标检测的需要。因此,许多研究人员研究了基于单阶段检测的水下目标检测算法。Sung等人[11]提出了一种基于YOLO的模型,分类准确率达到93%。刘平等[12]基于YOLOv 3算法,利用GAN(Generative Adversarial Networks)模型实现了海洋生物的识别。Chen等[2]提出了一种基于改进YOLOV 5s的弱光下水下生物目标识别方法,以解决水下光照衰减严重、图像环境复杂、拍摄设备移动等导致的生物特征识别精度低的问题。
Multi-scale feature fusion technology .多尺度特征融合技术。
Generating discriminative multi-scale features is an effective method to solve the problem of large scale differences and high similarity between classes of objects, which can greatly improve the performance of object detection. However, at present, most fusion methods fuse features of different scales with fixed weights. Feature pyramid (FPN) [13] enhances the semantic information of top-level features through lateral connection and top-down paths. Then, many feature fusion networks are derived from FPN. Liu et al. [14] proposed PANet, which adds bottom-up paths to feature pyramid FPN to fuse features of adjacent scales. Vishnu Chalavadi et al. [15] proposed a novel network for multi-scale object detection in aerial images using hierarchical dilated convolutions, called as mSODANet. Zhao et al. [16] designed a pyramid network of multi-level and multiscale feature fusion, which cascaded and fused the multi-scale features at different stages of the backbone network. It greatly enriches the semantic information of features. Ghiasi et al. [17] used the neural architecture search method to search the optimal feature pyramid structure, which greatly improved the discrimina tion of features, but the neural architecture search required huge GPU resources, which restricted the universality of pyramid network. Xie et al. [18] proposed a dynamic feature fusion network for remote sensing object detection. This network consists of feature gating module and dynamic fusion module, which can realize dynamic fusion of multi-scale features.产生具有区分性的多尺度特征是解决目标类间尺度差异大、相似度高的问题的有效方法,可以大大提高目标检测的性能。然而,目前,大多数融合方法融合不同尺度的特征与固定的权重。特征金字塔(FPN)[13]通过横向连接和自顶向下路径增强顶层特征的语义信息。然后,从FPN中衍生出多种特征融合网络。Liu等人。[14]提出了PANet,它将自下而上的路径添加到特征金字塔FPN中,以融合相邻尺度的特征。Vishnu Chalavadi等人[15]提出了一种新的网络,用于使用分层扩张卷积进行航空图像中的多尺度对象检测,称为mSODANet。Zhao等人[16]设计了一种多级多尺度特征融合的金字塔网络,将骨干网络不同阶段的多尺度特征进行级联融合。它极大地丰富了特征的语义信息。Ghiasi等人[17]使用神经架构搜索方法搜索最优特征金字塔结构,大大提高了特征的区分度,但神经架构搜索需要巨大的GPU资源,限制了金字塔网络的通用性。Xie等人[18]提出了一种用于遥感目标检测的动态特征融合网络。该网络由特征选通模块和动态融合模块组成,可实现多尺度特征的动态融合。
Data enhancement technology .数据增强技术。
Deep learning is a data-based method, so the preprocessing of training data is very important. Common data preprocessing methods include rotation, distortion, random erasure, random occlusion and illumination distortion. Xiao et al. [19] put forward a copy-reduce-paste small object enhancement method to improve the contribution of small objects to the loss function and make the training more balanced.深度学习是一种基于数据的方法,因此训练数据的预处理非常重要。常用的数据预处理方法有旋转、畸变、随机擦除、随机遮挡和光照畸变等。Xiao et al. [19]提出了复制-减少-粘贴小对象增强方法,以提高小对象对损失函数的贡献,使训练更加均衡。
Deep learning is a data-based method, so the preprocessing of training data is very important. Common data preprocessing methods include rotation, distortion, random erasure, random occlusion and illumination distortion. Xiao et al. [19] put forward a copy-reduce-paste small object enhancement method to improve the contribution of small objects to the loss function and make the training more balanced.深度学习是一种基于数据的方法,因此训练数据的预处理非常重要。常用的数据预处理方法有旋转、畸变、随机擦除、随机遮挡和光照畸变等。Xiao et al. [19]提出了复制-减少-粘贴小对象增强方法,以提高小对象对损失函数的贡献,使训练更加均衡。
YOLOv5s model .YOLOv5s模型。
YOLO series algorithms are based on PyTorch framework, which is easy to extend to mobile devices and belongs to lightweight network. YOLOv5 is a model with strong performance and versatility in YOLO series at present, and YOLOv5s is the first choice for lightweight networks, which is easy to deploy to embedded devices [20] . YOLOv5s network adopts OneStage structure, which consists of four parts: Input terminal, Backbone network, Neck network layer and Head output terminal. Input has Mosaic data enhancement, adaptive anchor box computing and adaptive picture scaling functions. Backbone network includes Focus structure, CSP structure and SPP structure of spatial pyramid pool, and features of different levels in the image are extracted by deep convolution operation. Neck network layer consists of FPN and path aggregation network structure (PAN). As the final detection of head, different size objects are predicted on different size feature maps [2] .YOLO系列算法基于PyTorch框架,易于扩展到移动的设备,属于轻量级网络。YOLOv5是目前YOLO系列中性能和通用性较强的机型,YOLOv5s是轻量级网络的首选,易于部署到嵌入式设备[20]。YOLOv5s网络采用OneStage结构,由四部分组成:输入端、骨干网、Neck网络层和Head输出端。输入具有马赛克数据增强、自适应锚盒计算和自适应图片缩放功能。骨干网络包括空间金字塔池的Focus结构、CSP结构和SPP结构,通过深度卷积运算提取图像中不同层次的特征。颈部网络层由FPN和路径汇聚网络结构(PAN)组成。作为头部的最终检测,在不同大小的特征图上预测不同大小的对象[2]。
3. Proposed method
3.1. Overall framework
3.1.总体框架
As shown in Fig. 2 , the proposed model takes the lightweight object detection model YOLOv5s as the basic model, and consists of six parts: Input terminal, Backbone network, Neck network layer, feature gating module, feature dynamic fusion and purification module and Prediction output terminal.如图2所示,该模型以轻量级目标检测模型YOLOv5s为基础模型,由输入端、骨干网络、颈网络层、特征门控模块、特征动态融合与净化模块、预测输出端六部分组成。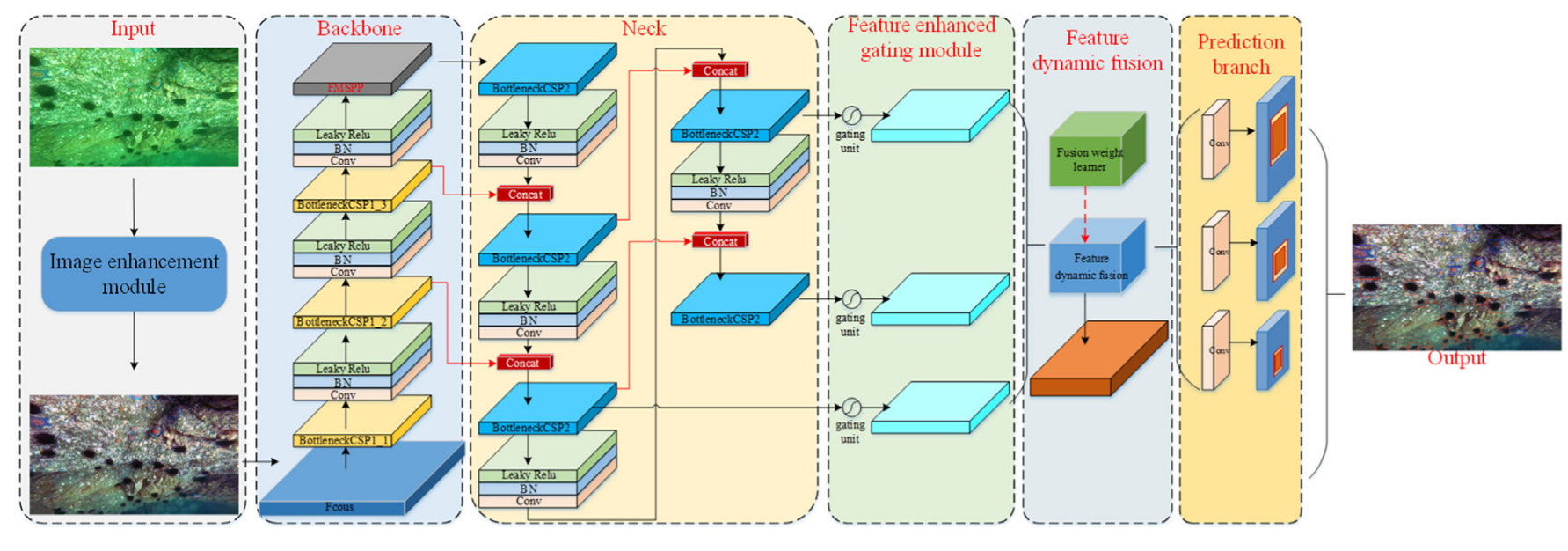
Fig. 2. The framework of our model.
图二 我们的模型框架。
Firstly, the underwater image is corrected by using the image adaptive enhancement module [28] to suppress the environmental noise. Backbone network includes Focus structure, CSP structure and FMSPP structure, and features of different levels in the image are extracted by deep convolution operation. Neck network layer is composed of FPN and path aggregation network (PAN), which extracts multi-scale features from images. The feature enhancement gating module is used to adjust the size of multi-scale features, and then selectively enhance or suppress the adjusted features with the same size. The dynamic feature fusion module establishes the relationship between the input object scale and feature fusion, learns the fusion weight according to the input object scale, and assigns different fusion weights to multi-scale features to realize the dynamic fusion of multi-scale features, and suppress the conflict information after multi-scale feature fusion and prevent small objects from drowning in the conflict information. Prediction, as the final detection output.首先,利用图像自适应增强模块[28]对水下图像进行校正,抑制环境噪声。骨干网络包括Focus结构、CSP结构和FMSPP结构,通过深度卷积运算提取图像中不同层次的特征。颈部网络层由FPN和路径聚合网络(PAN)组成,从图像中提取多尺度特征。特征增强选通模块用于调整多尺度特征的大小,然后选择性地增强或抑制具有相同大小的调整后的特征。动态特征融合模块建立输入对象尺度与特征融合之间的关系,根据输入对象尺度学习融合权值,为多尺度特征分配不同的融合权值,实现多尺度特征的动态融合,并抑制多尺度特征融合后的冲突信息,防止小对象淹没在冲突信息中。预测,作为最终检测输出。
3.2. Fast spatial mixed pooling pyramid
3.2.快速空间混合池金字塔
Due to the complicated underwater environment and low visibility, the image texture features are lost, which makes the distinction between underwater objects and the surrounding environment low and the texture unclear. So, as shown in Fig. 3 , this paper proposes a fast spatial mixed pooling pyramid (FMSSP) based on the same size fast mixed pooling layer to replace the spatial pyramid pooling (SPP) module in the original YOLOv5s model, which consists of different sizes of maximum pooling layers.由于水下环境复杂,能见度低,图像纹理特征丢失,使得水下目标与周围环境的区分度低,纹理不清晰。因此,如图3所示,本文提出了一种基于相同大小的快速混合池化层的快速空间混合池化金字塔(FMSSP),以取代原始YOLOv5s模型中由不同大小的最大池化层组成的空间金字塔池化(SPP)模块。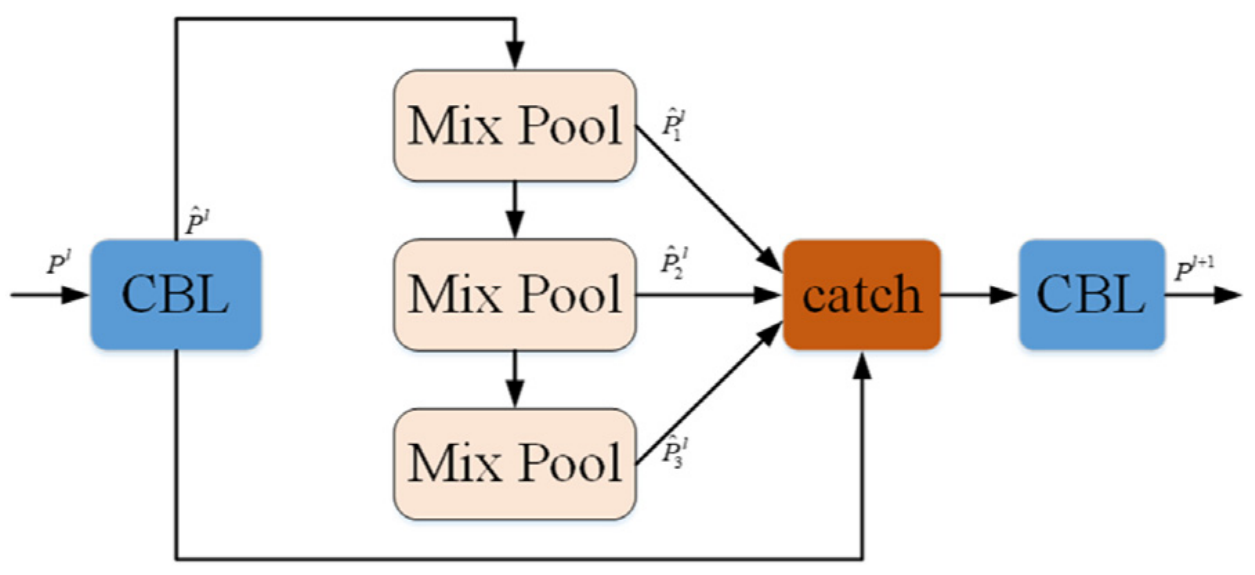
Fig. 3. The schematic diagram of Copy-reduce-rotate-paste data enhancement strategy.
图三 Copy-reduce-rotate-paste数据增强策略示意图。
The FMSSP module performs mixed pooling with the scale of 5 × 5 [32] on the input feature map as shown in formula (1).FMSSP模块在输入特征图上执行比例为5 × 5 [32]的混合池化,如公式(1)所示。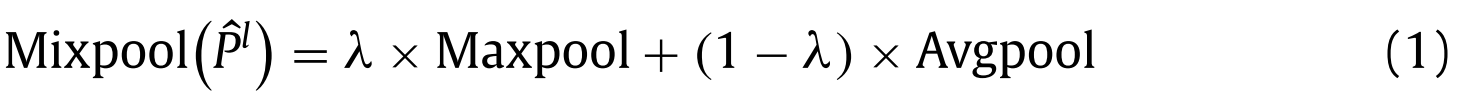
where λ is a random value of 0 or 1, which means that the max pooling or average pooling is selected. The mixed pooling changes the rules of pool adjustment in a random way, which will solve the problems encountered in maximum pooling and average pooling to some extent [25] .其中λ是0或1的随机值,这意味着选择最大池化或平均池化。混合池以随机的方式改变了池的调整规则,这将在一定程度上解决最大池和平均池所遇到的问题[25]。
Then, channel connection is made to the output of the pool layer in each stage, and the process is shown in formula (2) , the catch used in this paper is the concatenate operation.然后,在每一级中对池层的输出进行通道连接,过程如公式(2)所示,本文中使用的catch是concatenate操作。
While avoiding the loss of local features, FMSPP can reduce redundant information and retain prominent texture features, so that the network can obtain stronger description ability of texture and contour features, thus reducing the influence caused by the inconspicuous contour and texture features of underwater images. Compared with SPP module, FMSPP module has a faster forward propagation speed, thus alleviating the detection speed loss caused by incorporating feature enhancement gating module [2] . Furthermore, FMSPP can solve the over-fitting problem and improve the classification accuracy through mixed pooling without setting any hyper-parameters for adjustment.FMSPP在避免局部特征丢失的同时,减少冗余信息,保留突出的纹理特征,使网络获得更强的纹理和轮廓特征描述能力,从而减少水下图像不明显的轮廓和纹理特征带来的影响。与SPP模块相比,FMSPP模块具有更快的前向传播速度,从而减轻了由于结合特征增强门控模块而导致的检测速度损失[2]。此外,FMSPP可以解决过拟合问题,并通过混合池提高分类精度,而无需设置任何超参数进行调整。
3.3. Feature enhancement gating module
3.3.特征增强选通模块
Due to the complex background of underwater images, direct fusion of multi-scale features will introduce irrelevant background features, reduce the discrimination between foreground and background, and affect the accuracy of detection results. So it is essential to selectively enhance or suppress multi-scale features before fusion. In this paper, a feature gating module [21] is designed to adjust the size of multi-scale features, and then selectively enhance or suppress the adjusted features of the same size. The size adjustment is mainly realized by interpolation and convolution, and the selective enhancement or suppression of features is realized by gating unit.由于水下图像背景复杂,直接融合多尺度特征会引入无关的背景特征,降低前景与背景的区分度,影响检测结果的准确性。因此在融合前有选择地增强或抑制多尺度特征是非常必要的。在本文中,设计了一个特征门控模块[21]来调整多尺度特征的大小,然后选择性地增强或抑制调整后的相同大小的特征。尺寸调整主要通过插值和卷积实现,特征的选择性增强或抑制通过选通单元实现。
The feature enhancement gating module is shown in Fig. 4 , which combines channel attention, spatial attention, global attention, residual connection and receptive field (RF) operation. Channel attention is to establish the correlation between channel features without introducing learning parameters, and adaptively enhance or suppress channel features according to the correlation. Spatial attention pays more attention to the position information, focusing on the area with more effective features in the feature map, which is a supplement to channel attention. Global attention is to learn a global attention coefficient by full connection layer to achieve the overall enhancement or suppression of input features [22] . RF operation integrates more discriminative feature representation by expanding the receptive field range to achieve effective enhancement of features. The gating unit designed in this paper does not need to set any threshold. It is an input feature driven gating mechanism.特征增强选通模块如图4所示,其组合了通道注意力、空间注意力、全局注意力、残余连接和感受野(RF)操作。信道关注是在不引入学习参数的情况下建立信道特征之间的相关性,并根据相关性自适应地增强或抑制信道特征。空间注意力更关注位置信息,关注特征图中有效特征更多的区域,是对通道注意力的补充。全局注意力是通过全连接层学习一个全局注意力系数,实现对输入特征的整体增强或抑制[22]。RF操作通过扩大感受野范围来集成更多的鉴别特征表示,以实现特征的有效增强。本文设计的门控单元不需要设置任何阈值。它是一种输入特征驱动的选通机制。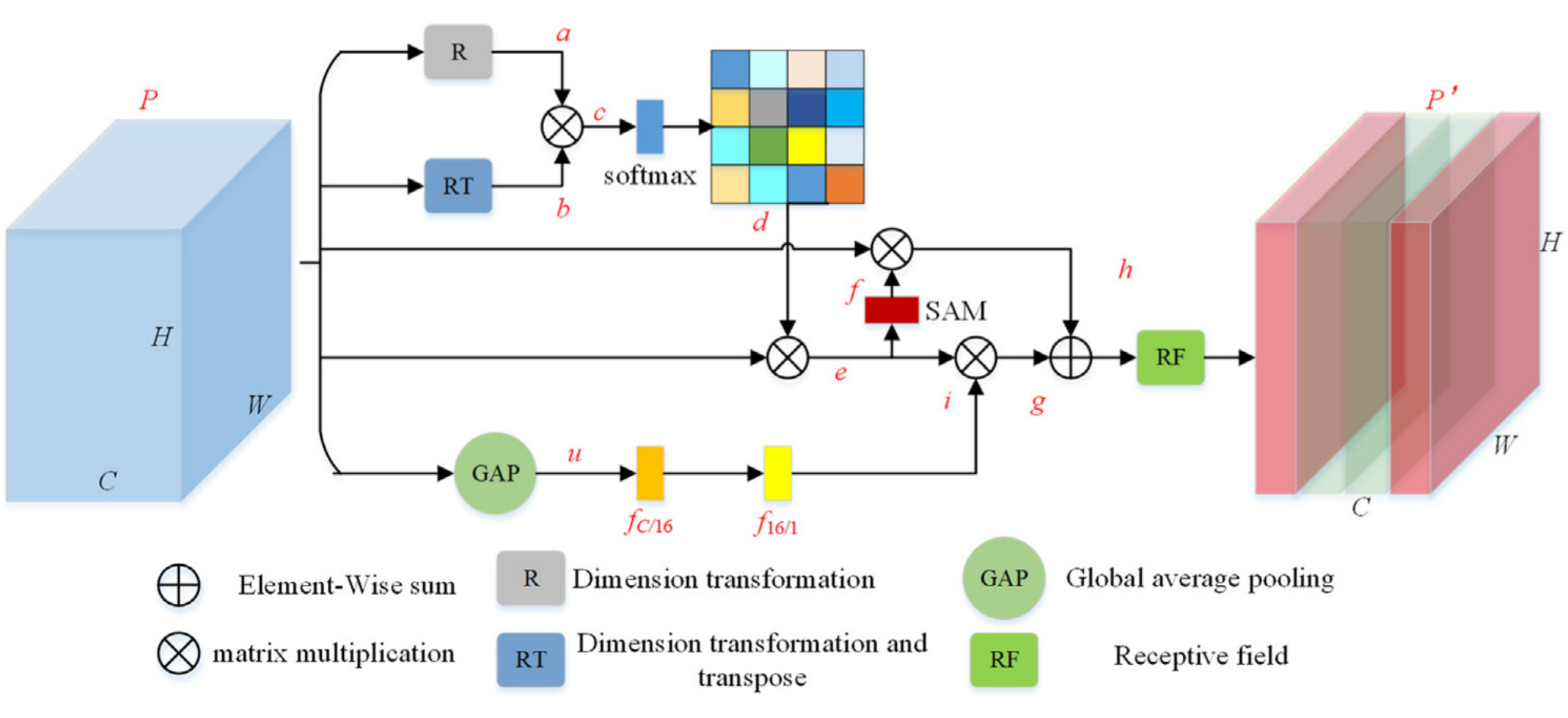
Fig. 4. The feature enhancement gating module.
图4 特征增强门控模块。
For the input feature P ∈ C×H×W , the feature a ∈ C×HW is obtained by dimensional transformation (R). Feature b ∈ HW ×C is obtained by dimensional transformation plus transposition (RT). The relationship matrix c ∈ C×C between the feature channels is obtained by matrix multiplication of the features a and b, and the normalized relationship matrix d ∈ C×C is obtained by softmax operation on the relationship matrix c. Softmax operation is shown in formula (3) .对于输入特征P ∈ C×H×W,通过维数变换(R)得到特征a ∈ C×HW。特征B ∈ HW ×C通过维数变换加转置(RT)得到。通过特征a和b的矩阵相乘得到特征通道之间的关系矩阵c ∈ C×C,通过对关系矩阵c进行softmax运算得到归一化关系矩阵d ∈ C×C。Softmax运算如公式(3)所示。
where $d_{i j}$ and $c_{i j}$ represent the values in row i and column j of the relationship matrices d and c, respectively. Then the relationship matrix d is multiplied with P to obtain feature e ∈ C×H×W . The feature e is input to the spatial attention module (SAM), and the feature map e is compressed in the channel dimension by using average pooling and maximum pooling to obtain two two-dimensional feature maps, then concat 2 feature maps based on the channel to get a feature map with 2 channel. To ensure that the final features are consistent with the input e in spatial dimension, a hidden layer with a single convolution kernel is used to convolve the spliced feature maps, and finally a spatial attention weight f ∈ C×H is generated by the sigmoid operation, as shown in formula (4) .其中$d_{i j}$和$c_{i j}$分别表示关系矩阵d和c的行i和列j中的值。然后将关系矩阵d与P相乘,得到特征e ∈ C×H×W。将特征e输入到空间注意力模块(SAM)中,利用平均池化和最大池化对特征图e进行通道维压缩,得到两个二维特征图,然后基于通道对两个特征图进行拼接,得到一个双通道特征图。为了保证最终特征在空间维度上与输入e一致,使用具有单个卷积核的隐藏层对拼接的特征图进行卷积,最后通过sigmoid运算生成空间注意力权重f ∈ C×H,如公式(4)所示。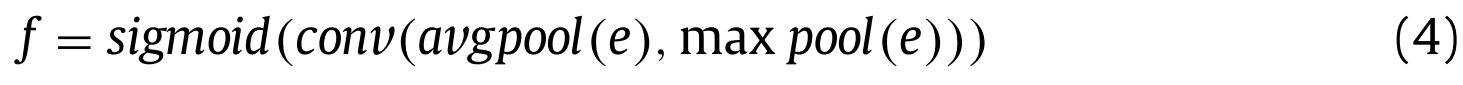
In addition, to adaptively suppress or enhance the input features, we use a global attention mechanism. The global attention mechanism is implemented by learning the global feature conditioning coefficients with the fully connected layer. The first step is to perform global average pooling (GAP) on features P to get feature vector u ∈ C . The GAP is implemented as shown in formula (5) .此外,为了自适应地抑制或增强输入特征,我们使用了全局注意力机制。全局注意机制通过学习全连接层的全局特征条件系数来实现。第一步是对特征P执行全局平均池化(GAP)以得到特征向量u ∈ C。差距的实现如公式(5)所示。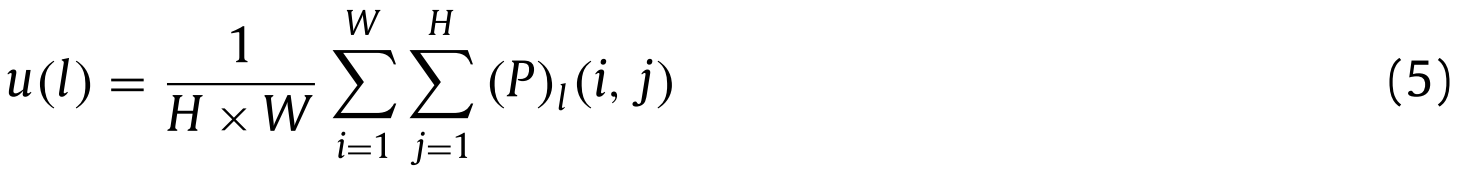
where $(P)l$ represents the l ∈ [1 , C] th channel of P,and u( l ) represents the value of the l th channel of P after global averaging pooling . The second step takes u as the input and uses the fully connected layers $f{c/ 16}$ and $f_{16 / 1}$ to learn the global feature conditioning factor i , as shown in formula (6) .其中$(P)l$表示P的第l ∈ [1,C]个通道,并且u(l)表示全局平均池化之后P的第l个通道的值。第二步以u为输入,使用全连接层$f{c/ 16}$和$f_{16 / 1}$学习全局特征条件因子i,如公式(6)所示。
Where $f_{c/ 16}$ represents the first fully connected layer (the input dimension is C and the output dimension is 16).$ f_{16 / 1}$ represents the second fully connected layer (the input dimension is 16 and the output dimension is 1). Finally, the global feature adjustment coefficient i is applied to the feature e to output the feature g ∈ C×H×W , and the residual connection is made with the output feature h ∈ C×H×W through SAM.其中$f_{c/ 16}$表示第一个全连通层(输入维度为C,输出维度为16)。$ f_{16 / 1}$ 表示第二个全连接层(输入维度为16,输出维度为1)。最后,将全局特征调整系数i应用于特征e以输出特征g ∈ C×H×W,并通过SAM与输出特征h ∈ C×H×W进行残差连接。
In the human visual system, a set of differently sized population receptive fields (PRFs) help to highlight regions close to the fovea, which are sensitive to small spatial displacements. This inspires us to use the RF module [30] to expand the feature receptive field and obtain global context information to further enhance the expression of features and obtain the output feature P . The RF module can be expressed in detail as Formula (7) and Formula (8) .在人类视觉系统中,一组不同大小的群体感受野(PRFs)有助于突出靠近中央凹的区域,这些区域对小的空间位移敏感。这启发我们使用RF模块[30]来扩展特征感受野并获得全局上下文信息,以进一步增强特征的表达并获得输出特征P。RF模块可以详细地表示为公式(7)和公式(8)。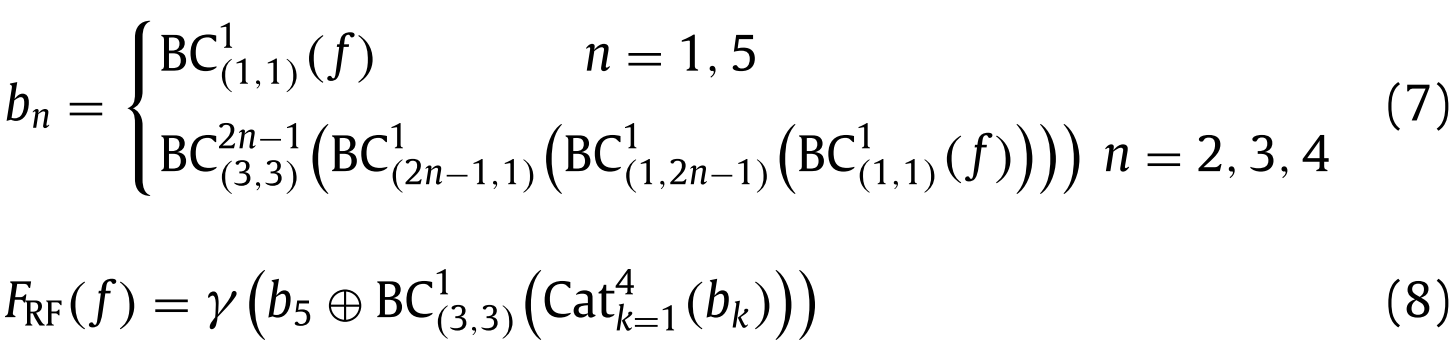
Where $b_n$ in the formula (7) represents the characteristic diagram of the branch n of the RF module; $\mathrm{BC}{3,3}^{2 n-1}$ represents the sequential operation of 3 × 3 convolution operation with expansion rate 2 n − 1 and batch normalization; $\mathrm{Cat}{k =1}^{4}$ means splicing the first four branches to integrate the acquired context information; γ represents the ReLU (Rectified Linear Unit) activation function. In reference [23] . The output dimension of all convolution operations in RF module is set to 32 in order to maintain the balance between computation and performance.其中,式(7)中的$b_n$表示RF模块的分支n的特征图; $\mathrm{BC}{3,3}^{2 n-1}$表示扩展率为2n-1的3 × 3卷积运算和批量归一化的顺序运算; $\mathrm{Cat}{k =1}^{4}$表示将前四个分支拼接,整合获取的上下文信息; γ表示ReLU(Rectified Linear Unit)激活函数。在参考文献[23]中。RF模块中所有卷积运算的输出维数都设置为32,以保持计算和性能之间的平衡。
3.4. Progressive feature dynamic aggregation strategy
3.4.渐进式特征动态聚合策略
In order to fully and effectively aggregate the multi-level feature information, this paper adopts a progressive dynamic aggregation strategy [24] to achieve the aggregation of multi-level features. This strategy dynamically aggregates adjacent features step by step to avoid the noise problem caused by cross-level fusion, and effectively im proves the adaptability of feature fusion. Progressive aggregation strategy has a lateral contraction structure, in which adjacent features are contracted by adjacent aggregation modules, and the contracted new features are used as the input of the next adjacent aggregation module. In the process of aggregation, in order to effectively integrate the information of adjacent features, this paper designs a Dynamic Aggregation Module (DAM) to keep the important information of adjacent features and suppress noise. As shown in Fig. 5 , the Adjacency Dynamic Aggregation Network (ADAN) adopts three dynamic aggregation modules to progressively aggregate pairs of adjacent features, so as to realize the accurate detection of underwater difficult-to-detect objects.为了充分有效地聚合多层次特征信息,本文采用渐进式动态聚合策略[24]来实现多层次特征的聚合。该策略通过逐步动态聚合相邻特征,避免了跨层融合带来的噪声问题,有效地提高了特征融合的适应性。渐进式聚合策略具有横向收缩结构,相邻聚合模块对相邻特征进行收缩,收缩后的新特征作为下一个相邻聚合模块的输入。在聚合过程中,为了有效地融合相邻特征的信息,本文设计了动态聚合模块(DAM)来保持相邻特征的重要信息并抑制噪声。如图5所示,邻接动态聚合网络(ADAN)采用三个动态聚合模块,对相邻特征对进行渐进聚合,实现水下难探测目标的精确检测。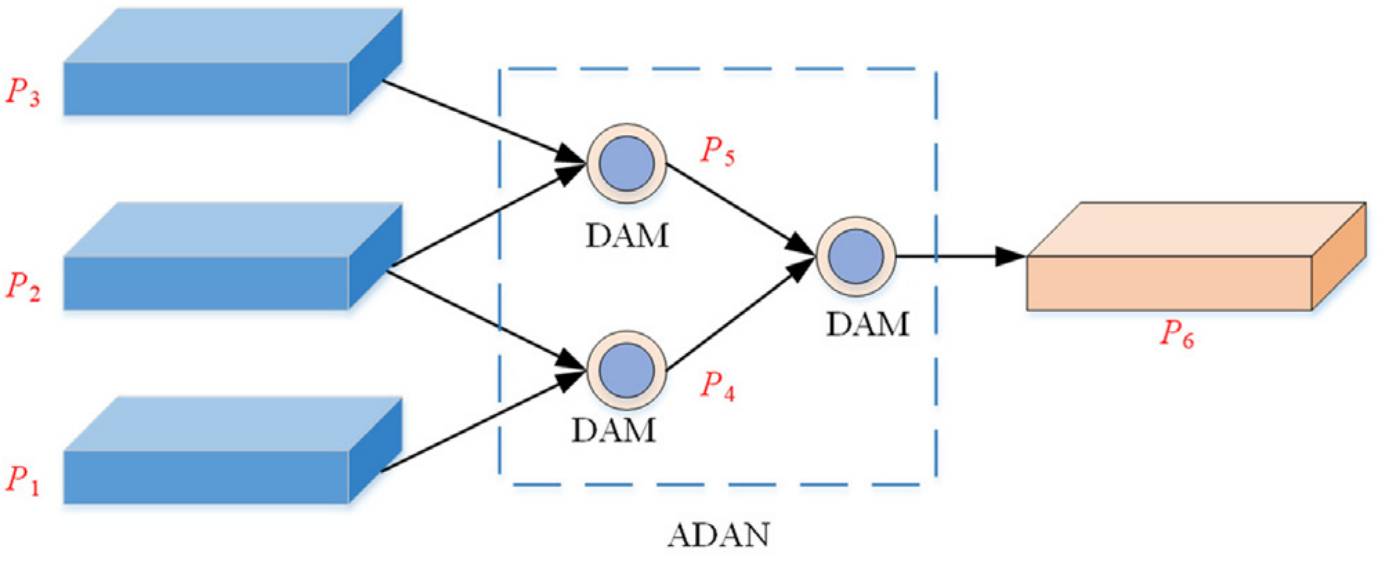
Fig. 5. The schematic diagram of progressive feature dynamic aggregation strategy.
图五 渐进式特征动态聚合策略示意图。
In object detection, fusing multi-scale features with fixed weights will make all the input images share the fusion mode, ignoring the influence of the object size on feature fusion, which restricts the detection performance. Therefore, it is necessary to dynamically adjust the fusion weight according to the input object scale to improve the adaptability of feature fusion [18] . Based on the above ideas, we designed a dynamic fusion module. This module establishes the relationship between the input object scale and feature fusion, learns the fusion weights according to the input object scale, and assigns different fusion weights to multi-scale features. The dynamic fusion module is mainly realized by the fusion weight learner, and the learner is shown in Fig. 6 . It takes feature with the same size as input, and outputs a set of fusion weights, and the learning of weights is realized through full connection layer.在目标检测中,固定权值的多尺度特征融合会使所有输入图像共享融合模式,忽略了目标大小对特征融合的影响,从而限制了检测性能。因此,有必要根据输入对象尺度动态调整融合权重,以提高特征融合的适应性[18]。基于上述思想,设计了动态融合模块。该模块建立了输入目标尺度与特征融合之间的关系,根据输入目标尺度学习融合权值,为多尺度特征分配不同的融合权值。动态融合模块主要由融合权重学习器实现,学习器如图6所示。该方法以相同大小的特征作为输入,输出一组融合权值,权值的学习通过全连接层实现。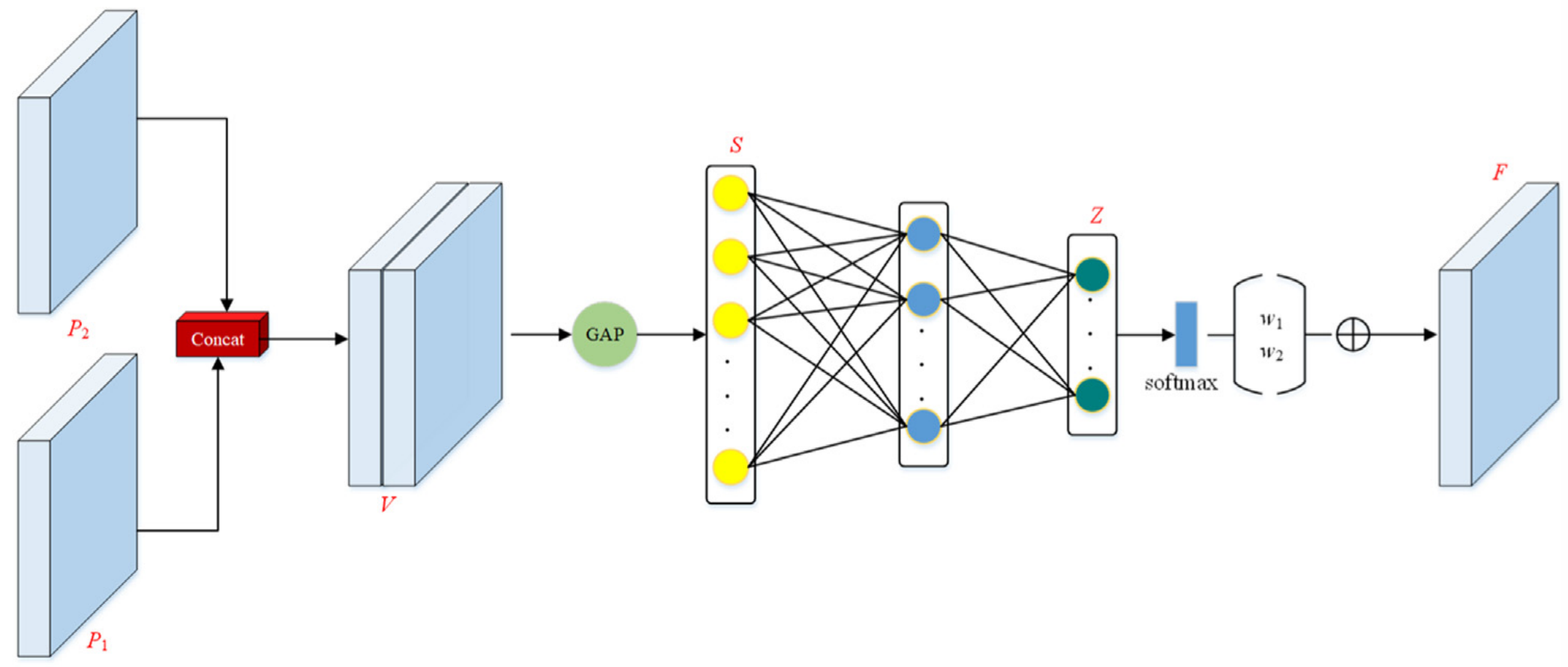
Fig. 6. The schematic diagram of dynamic fusion weight learner.
图6 动态融合权值学习器原理图。
Firstly, the feature { P 1 , P 2 } with the same size is cascaded to get the feature V ∈ 2 C×H×W , and then the feature V is globally averaged and pooled to get the feature vector S ∈ 2 C . To reduce the operation cost, we use two fully connected layers $f_{2 C / ( C / 2 )}$ and $f_{2 C / ( C / 2 )}$ to learn the feature fusion weight Z ∈ 2 [21] . To improve the stability of the training of the fusion weight learner, we perform softmax operation on Z to obtain the normalized fusion weight { w 1 , w 2 } . The learned fusion weight here represents the importance of multiscale features in fusion. Finally, according to the learned fusion weight, the input feature { P 1 , P 2 } is fused linearly to obtain the feature F ∈ C×H×W . The linear fusion is calculated as shown in formula (9) .首先将相同大小的特征{P1,P2}级联得到特征V ∈ 2 C×H×W,然后对特征V进行全局平均和池化得到特征向量S ∈ 2 C。为了降低操作成本,我们使用两个全连接层$f_{2 C / ( C / 2 )}$和$f_{2 C / ( C / 2 )}$来学习特征融合权重Z ∈ 2 [21]。为了提高融合权值学习器训练的稳定性,对Z进行softmax运算,得到归一化的融合权值{w1,w2}。这里学习的融合权重表示融合中多尺度特征的重要性。最后,根据学习得到的融合权值,对输入特征{P1,P2}进行线性融合,得到特征F ∈ C×H×W。如公式(9)所示计算线性融合。
3.5. Data enhancement strategy
3.5.数据增强策略
In the current mainstream public data sets, the number of small objects or the number of pictures containing small objects is far less than that of large objects. At the same time, the number of positive samples generated by small objects is far less than that of large objects, resulting in the contribution rate of small objects to the loss function being far less than that of large objects, which makes the direction of network convergence continue to tilt toward large objects. Inspired by literature [19] , this paper uses a new Copy-reduce-rotate-paste data enhancement strategy in the training process to increase the number of positive samples generated by small objects and the contribution value to the loss function, so that the training is more balanced. As shown in Fig. 6 , the solid line frame in Fig. 7 is the original object, and the dotted line frame is the pasted object. First, copy the large object image block, then the image block is reduced and randomly rotated, and finally pasted to different positions of the original image.在目前主流的公开数据集中,小物体的数量或包含小物体的图片数量远远少于大物体。同时,小对象产生的正样本数量远少于大对象,导致小对象对损失函数的贡献率远小于大对象,使得网络收敛的方向不断向大对象倾斜。受文献[19]的启发,本文在训练过程中采用了一种新的Copy-reduce-rotate-paste数据增强策略,增加了小对象产生的正样本数和对损失函数的贡献值,使训练更加均衡。如图6所示,图7中的实线框为原始对象,虚线框为粘贴对象。首先复制大对象图像块,然后对图像块进行缩小和随机旋转,最后粘贴到原始图像的不同位置。
Fig. 7. The schematic diagram of Copy-reduce-rotate-paste data enhancement strategy.
图7 Copy-reduce-rotate-paste数据增强策略示意图。
3.6. Loss function of our model
3.6.模型的损失函数
The loss function of YOLOv5s includes objective loss function, classification loss function and bounding box regression loss function. YOLOv5s uses BCE With Logits as the object loss function and classification loss function L BCE , as shown in formula (10) . P l represents the probability of output through Sigmoid activation function, and y is the real sample label, with a value of 0 or 1.YOLOv5s的损失函数包括目标损失函数、分类损失函数和边界框回归损失函数。YOLOv5s使用BCE With Logits作为对象损失函数和分类损失函数L BCE,如公式(10)所示。P l表示通过Sigmoid激活函数输出的概率,y是真实的样本标签,值为0或1。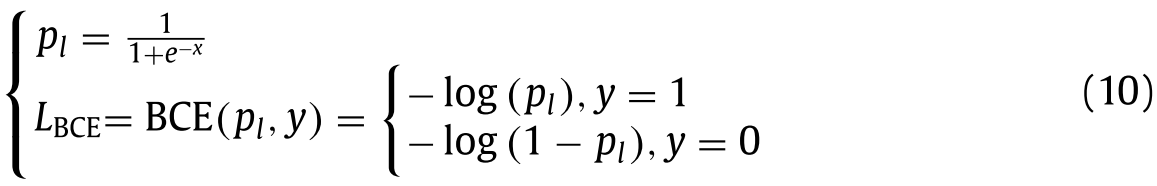
The part of the image containing the object is a positive sample, and the rest is a negative sample. For positive samples, the greater the output probability, the smaller the loss function; for negative samples, the smaller the output probability, the smaller the loss function. In underwater images, the proportion of background is obviously larger than that of object. For the One-Stage object detection algorithm, the unbalance between positive and negative samples is more prominent. Most of the loss values obtained by the loss function are negative sample background losses, and most of the negative sample backgrounds are simple and easily separable, which has little effect on the model’s convergence. So we introduces the focus loss function L Focal [26] to balance the influence of positive and negative samples on the loss function, and divides the samples into difficult samples and easy samples to reduce the weight of easy samples on the total loss function, as shown in formula (11) .图像中包含对象的部分是正样本,其余部分是负样本。对于正样本,输出概率越大,损失函数越小;对于负样本,输出概率越小,损失函数越小。在水下图像中,背景所占的比例明显大于目标。对于单阶段目标检测算法,正样本和负样本之间的不平衡更加突出。由损失函数得到的损失值大多为负样本背景损失,且大多数负样本背景简单易分离,对模型的收敛性影响不大。所以我们引入焦点损失函数L Focal [26]来平衡正负样本对损失函数的影响,并将样本分为困难样本和容易样本,以减少容易样本对总损失函数的权重,如公式(11)所示。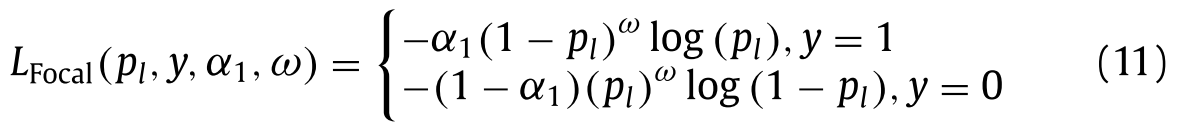
Among them, the balance factor $a_1$ is to control the contribution of positive and negative samples to the loss, but it can’t affect the loss of easy-to-distinguish and difficult-to-distinguish samples. Therefore, ω ∈ [ 0 , 5 ] is used to control the size of modulation factor, and the weights of difficult-to-distinguish samples and easy-to-distinguish samples are controlled by modulation factors $\left(1-p_l\right)^\omega$ and $\left(p_l\right)^\omega$. To sum up, the total loss function L total is in formula (12) .其中,平衡因子$a_1$是为了控制正负样本对损失的贡献,但不能影响易区分样本和难区分样本的损失。因此,使用ω ∈ [0,5]来控制调制因子的大小,并且通过调制因子$\left(1-p_l\right)^\omega$和$\left(p_l\right)^\omega$来控制难区分样本和易区分样本的权重。综上所述,总损失函数L total在公式(12)中。
4. Results
4.1. Datasets and evaluation metrics
4.1.数据集和评价指标
In this paper, underwater optical image data set URPC2021 [27] and underwater semantic segmentation data set of real scene (DUT-USEG) [28] are used as experimental data sets. URPC2021 data set provides a total of 8,200 training images, and there is no inter-frame continuity between these images. Including underwater images of holothurian, echinus, starfish and scallops, and the annotation of the corresponding images. DUT-USEG data set includes 6,617 underwater images, including four categories: holothurian, echinus, scallop and starfish, of which 1,487 images have manually added semantic segmentation labels and instance segmentation labels, and the remaining 5,130 images have object detection box labels. To test the optimization effect of our strategy on underwater small object detection, 200 images containing low-resolution small objects (pixel size less than 10 × 10) were selected from URPC and DUT-USEG, and the underwater lowresolution small object test set USO was constructed.本文使用水下光学图像数据集URPC 2021 [27]和真实的场景水下语义分割数据集(DUT-USEG)[28]作为实验数据集。URPC 2021数据集提供了总共8,200张训练图像,这些图像之间没有帧间连续性。包括海参、海胆、海星和扇贝的水下图像,以及相应图像的注释。DUT-USEG数据集包含6,617张水下图像,包括海参、海胆、扇贝和海星四个类别,其中1,487张图像手动添加了语义分割标签和实例分割标签,其余5,130张图像有对象检测框标签。为了验证该策略在水下小目标检测中的优化效果,从URPC和DUT-USEG中选取了200幅包含低分辨率小目标(像素尺寸小于10 × 10)的图像,构建了水下低分辨率小目标测试集USO。
In this paper, Precision P, Recall R, Average Precision AP, mean Average Precision mAP and single image reasoning time t are used to evaluate the effectiveness and real-time performance of the detector. The calculation methods of all evaluation metrics are adopt PASCAL VOC2007 standard, which can represent the performance of the detector [2] .本文采用查准率P、查全率R、平均查准率AP、平均平均查准率mAP和单幅图像推理时间t等指标来评价检测器的有效性和实时性。所有评价指标的计算方法均采用PASCAL VOC 2007标准,能够代表探测器的性能[2]。
4.2. Experimental environment and application details
4.2.实验环境和应用细节
The hardware platform used in model training is Intel Xeon e52680 V4 CPU, 32 GB memory and NVIDIA geforce RTX 3060 Ti GPU. The software platform is Windows operating system and the deep learning framework is pytoch. During model training, the object categories is 4, the image size is 640 × 640, the optimizer is SGD [29] , the batch size is 8, the learning rate is 0.0 0 01, and the decay rate of the weight is 5 × 10 −4 , the momentum is set to 0.9, and the learning rate adjustment strategy is fixed step attenuation.模型训练中使用的硬件平台是Intel Xeon e52680 V4 CPU,32 GB内存和NVIDIA geforce RTX 3060 Ti GPU。软件平台是Windows操作系统,深度学习框架是pytoch。在模型训练期间,对象类别为4,图像大小为640 × 640,优化器为SGD [29],批量大小为8,学习率为0.0 0 01,权重的衰减率为5 × 10 −4,动量设置为0.9,学习率调整策略为固定步长衰减。
In this paper, Focal loss mainly depends on two hyperparameters $a_1$ and ω. in order to better integrate focal loss function and yolov5s to meet the needs of underwater object detection tasks, determining a set of optimal values of a$a_1$ and ω becomes the content of further research. According to the experimental results of reference [29] , $a_1$ takes 0.5 or 0.75, and ω takes an integer in the range of [ 1 , 5 ]. Following the principle of the control variable method, only a 1 and ω have different values in each reference group. The test results on URPC and DUT-USEG data sets show that when $a_1$ = 0.5and ω= 3, the network achieves the best detection results, and the three evaluation indexes are higher than other combinations.在本文中,焦点损失主要取决于两个超参数ω 1和ω。为了更好地将焦损函数和yolov 5s结合起来,以满足水下目标探测任务的需要,确定一组a$a_1$和ω的最优值成为进一步研究的内容。根据文献[29]的实验结果,$a_1$取0.5或0.75,ω取[ 1,5 ]范围内的整数。遵循控制变量法的原理,在每个参考组中只有$a_1$和ω具有不同的值。在URPC和DUT-USEG数据集上的测试结果表明,当$a_1$ = 0.5,ω= 3时,网络达到了最佳的检测效果,且3个评价指标均高于其他组合。
4.3. Ablation experiments
4.3.消融实验
4.3.1. Gating unit ablation experiment
4.3.1.选通单元烧蚀实验
In this paper, based on YOLOv5s, a gating unit module is added after the Neck network layer, and many ablation experiments are carried out on URPC and DUT-USEG data sets. The effects of channel attention (CA), spatial attention (SA), global attention (GA), RF module and residual connection (RC) in the gating unit are verified respectively, the results are shown in Table 1 .本文在YOLOv 5s的基础上,在Neck网络层后增加了选通单元模块,并在URPC和DUT-USEG数据集上进行了多次烧蚀实验。分别验证了门控单元中通道注意力(CA)、空间注意力(SA)、全局注意力(GA)、RF模块和剩余连接(RC)的效果,结果如表1所示。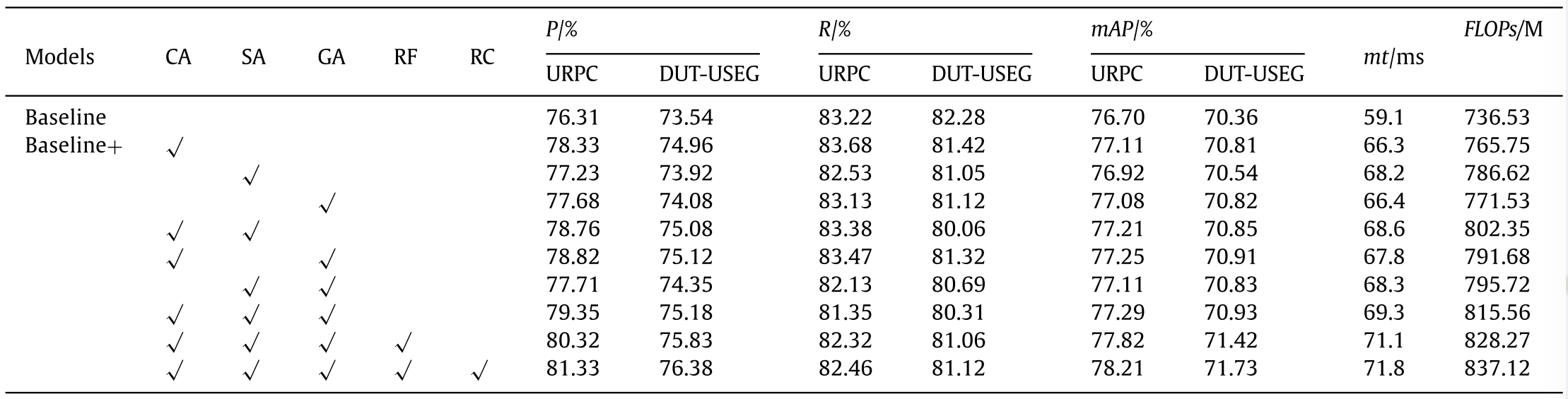
Table 1 The ablation experiment results of gate control unit on URPC and DUT-USEG data sets.
表1 门控单元在URPC和DUT-USEG数据集上的烧蚀实验结果。
The mAp of the baseline method on URPC and DUT-USEG datasets was 76.70% and 70.36% respectively, which increased by 1.51% and 1.37% respectively after adding the designed gating unit, and the average processing time of an image increased by 12ms. On the URPC dataset, when the gating unit only fuses the channel attention features, the mAp increases by 0.41% compared with the baseline model; when the gating unit only fuses the spatial attention features, the mAp increases by 0.22% compared with the baseline; when the gating unit only fuses the global attention features, the mAp increases by 0.38% compared with the baseline. At the same time, three attention features were introduced, which improved the mAp by 0.59% compared with the baseline model. On this basis, the RF module was introduced, which improved the mAp by 0.53%. Continue to add residual connections, increasing by 0.39%. On the DUT-USEG dataset, when the gating unit only fuses channel attention features, the mAp increases by 0.45% compared with the baseline model; when the gating unit only fuses spatial attention features, the mAp increases by 0.18% compared with the baseline model; when the gating unit only fuses global attention features, the mAp increases by 0.46% compared with the baseline model. Three attention features were introduced at the same time, and compared with the baseline model, the mAp increased by 0.57%. On this basis, the RF module was introduced, and the mAp increased by 0.49%. Continue to add residual connections, increasing by 0.31%.基线方法在URPC和DUT-USEG数据集上的mAp分别为76.70%和70.36%,加入设计的门控单元后分别提高了1.51%和1.37%,图像的平均处理时间增加了12 ms。在URPC数据集上,当门控单元仅融合通道注意力特征时,mAp较基线模型增加0.41%;当门控单元仅融合空间注意力特征时,mAp较基线增加0.22%;当门控单元仅融合全局注意力特征时,mAp较基线增加0.38%。同时,引入了三个注意力特征,与基线模型相比,mAp提高了0.59%。在此基础上,引入了射频模块,使mAp提高了0.53%。继续增加剩余连接,增加0.39%。在DUT-USEG数据集上,当门控单元仅融合通道注意特征时,mAp较基线模型增加0.45%;当门控单元仅融合空间注意特征时,mAp较基线模型增加0.18%;当门控单元仅融合全局注意特征时,mAp较基线模型增加0.46%。同时引入三个注意特征,与基线模型相比,mAp提高了0.57%。在此基础上,引入了射频模块,mAp提高了0.49%。继续增加剩余连接,增加0.31%。
In Table 1 , the accuracy of the baseline on the URPC and DUTUSEG is 76.31% and 73.54%, respectively. After the introduction of the gating unit, it has increased by 5.02% and 2.84%, respectively. The accuracy has been greatly improved, but the recall rate has indeed decreased by 0.8% and 1.1% respectively. Due to the addition of multiple attention mechanisms and the increase of the number of network layers, when similar objects are learned to the bottom of the neural network, the feature differentiation is not big, resulting in the object can be detected, but the category has been detected incorrectly, so the recall rate is reduced. But the introduction of RF module and residual connection effectively im proves the value of R .在表1中,URPC和DUTUSEG的基线准确度分别为76.31%和73.54%。引入门控单元后,分别提高了5.02%和2.84%。准确率有了很大的提高,但召回率确实分别下降了0.8%和1.1%。由于加入了多重注意机制和网络层数的增加,当相似的对象学习到神经网络底层时,特征区分度不大,导致对象可以检测到,但类别已经被错误检测到,因此召回率降低。但射频模块和剩余连接的引入有效地提高了R值。
Table 1 The ablation experiment results of gate control unit on URPC and DUT-USEG data sets.
表1 门控单元在URPC和DUT-USEG数据集上的烧蚀实验结果。
In summary, in the gating unit, the gain brought by RF module, channel attention and global attention is the most obvious, and the gain of residual connection is higher than that of spatial attention. Moreover, the feature enhanced gating module can effectively improve the accuracy, but will not reduce the operation efficiency too much.综上所述,在门控单元中,射频模块、通道注意力和全局注意力带来的增益最为明显,剩余连接的增益高于空间注意力。此外,特征增强选通模块可以有效地提高准确性,但不会降低操作效率太多。
4.3.2. Feature enhancement gating & Progressive feature dynamic aggregation strategy
4.3.2.特征增强门控&渐进式特征动态聚集策略
To verify the effectiveness of the Feature enhancement gating & Progressive feature dynamic aggregation strategy, ablation experiments were conducted on URPC, and the baseline mode is YOLOv5s, the results are shown in Table 2 . The mAP, P and R of the baseline model on URPC data set are 76.7%, 76.31% and 83.22%, respectively. After adding feature gating unit after different scale features in Neck network layer, the mAP of 78.02% increased by 1.32%, the P of 78.65% increased by 2.34%, and the R of 84.65% increased by 1.43%. In order to verify the gain brought by dynamic fusion, without feature gating, adding dynamic fusion to the baseline model increases the mAP by 1.82%, P by 3.55% and R by 3.1%. There is no feature gating here, which mainly unifies the three different scale features output by Neck network layer, then dynamically fuses them to obtain features, and finally obtains multi-scale features by resampling. To sum up, the gain of dynamic feature fusion is greater than that of feature gating. By adding feature gating and dynamic feature fusion to the benchmark method, the mAP is increased by 3.17%, P by 5.32% and R by 4.71%.为了验证特征增强门控&渐进式特征动态聚合策略的有效性,在URPC上进行了消融实验,基线模式为YOLOv5s,结果如表2所示。基线模型在URPC数据集上的mAP、P和R分别为76.7%、76.31%和83.22%。在Neck网络层的不同尺度特征后添加特征选通单元后,78.02%的mAP增加了1.32%,78.65%的P增加了2.34%,84.65%的R增加了1.43%。为了验证动态融合带来的增益,在没有特征门控的情况下,将动态融合添加到基线模型中,mAP增加了1.82%,P增加了3.55%,R增加了3.1%。这里没有特征选通,主要是将Neck网络层输出的三个不同尺度的特征统一起来,然后动态融合得到特征,最后通过重排序得到多尺度特征。综上所述,动态特征融合的增益大于特征选通。通过在基准方法的基础上增加特征门和动态特征融合,mAP提高了3.17%,P提高了5.32%,R提高了4.71%。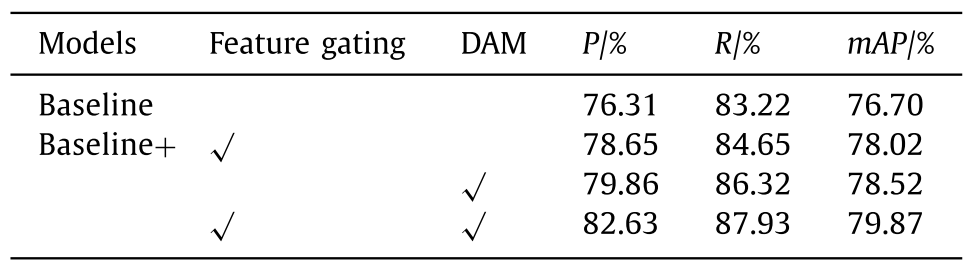
Table 2 The ablation experiment results on URPC data set.
表2 URPC数据集上的烧蚀实验结果。
The results on USO are shown in Table 3 . Both dynamic fusion and feature enhancement strategies can effectively improve the detection accuracy of small objects, among which dynamic fusion can improve the detection performance more obviously, increasing mAP by 6.17%, P by 6.15% and R by 5.89%.USO的结果见表3。动态融合和特征增强策略都能有效提高小目标的检测精度,其中动态融合对检测性能的提升更为明显,mAP提高了6.17%,P提高了6.15%,R提高了5.89%。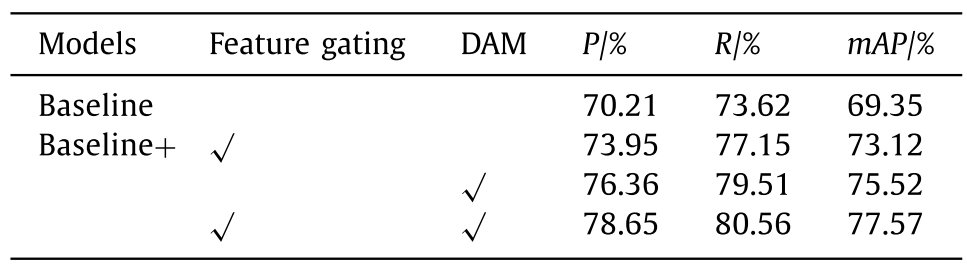
Table 3 The ablation experiment results on USO data set.
表3 USO数据集上的烧蚀实验结果。
Fig. 8 shows the feature fusion weights learned by dynamic feature fusion network with different scale objects as input, where red represents the maximum fusion weight and blue represents the minimum fusion weight. When the object scale of the input image is small, the bottom features $P_1$ and $P_2$ contain the detailed information of the object, which is beneficial to the detection of small objects. In feature fusion, the bottom features P 1 and $P_2$ will adopt larger weights, as shown in the first row of Fig. 8 . When the object scale of the input image is large, the semantic information extracted by the top feature $P_3$ is beneficial to the detection of large objects, and the top features will adopt larger weights, as shown in the second row of Fig. 8 .图8示出了以不同尺度对象作为输入的动态特征融合网络学习的特征融合权重,其中红色表示最大融合权重,蓝色表示最小融合权重。当输入图像的目标尺度较小时,底部特征$P_1$和$P_2$包含了目标的详细信息,有利于小目标的检测。在特征融合中,底部特征$P_1$和$P_2$将采用较大的权重,如图8的第一行所示。当输入图像的对象尺度较大时,顶部特征$P_3$提取的语义信息有利于大对象的检测,顶部特征将采用较大的权重,如图8的第二行所示。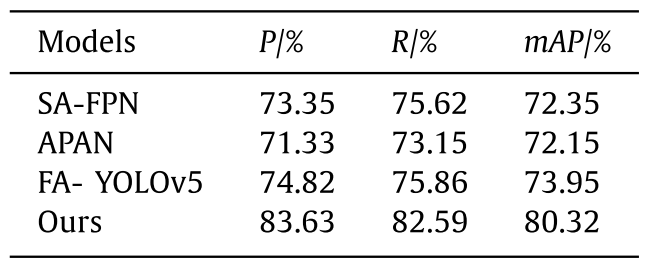
Table 8 Experimental results of performance comparison of various detectors on USO data set.
表8 各种探测器在USO数据集上的性能比较实验结果。
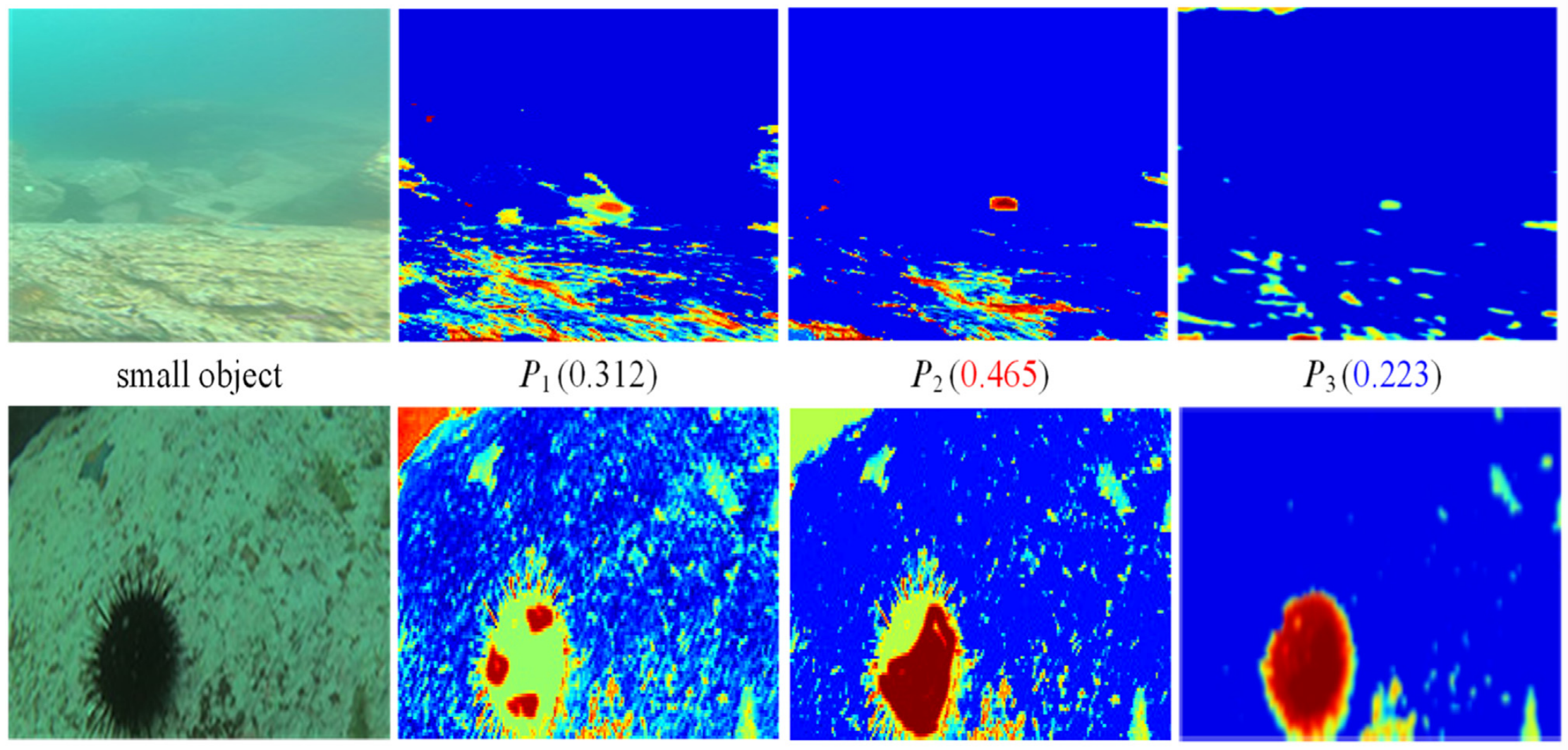
Fig. 8. The schematic diagram of Copy-reduce-rotate-paste data enhancement strategy.
图8 Copy-reduce-rotate-paste数据增强策略示意图。
To verify the effectiveness of the adjacent aggregation structure, three groups of ablation experiments are designed on URPC, and the results are shown in Table 4 . Fig. 9 shows the specific structure of each experimental scheme, in which (a) is a 3-2-adjacent structure, (b) is a 2-3-adjacent structure, and (c) is a 2-adjacent structure.为了验证相邻聚集结构的有效性,在URPC上设计了三组烧蚀实验,结果如表4所示。图9示出了每个实验方案的具体结构,其中(a)是3-2-相邻结构,(B)是2-3-相邻结构,以及(c)是2-相邻结构。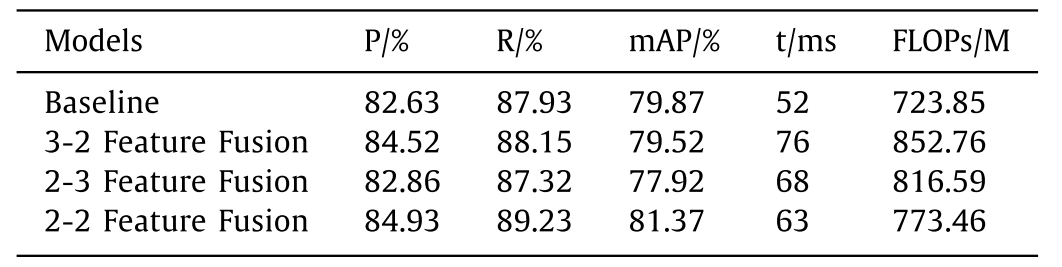
Table 4 The ablation experiment results on USO data set.
表4 USO数据集上的烧蚀实验结果。
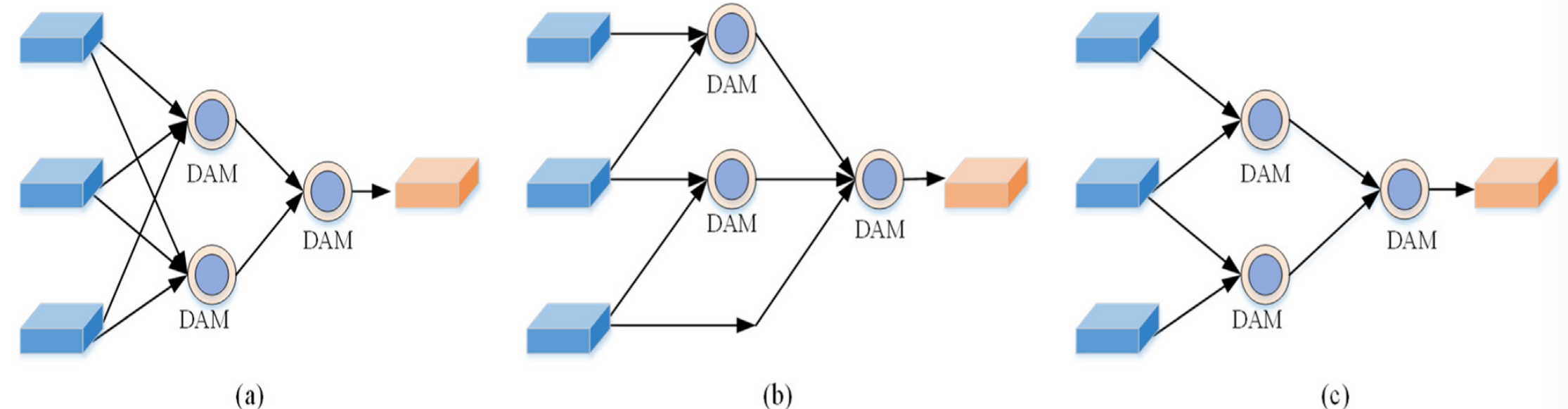
Fig. 9. Three different Combination structure.
图9 三种不同的组合结构。
In Table 4 , compared with 3-2-adjacent structure and 2-3-adjacent structure, the 2-adjacent structure achieves the best detection performance and detection efficiency, which verifies the superiority of two-proximity aggregation.在表4中,与3-2-邻接结构和2-3-邻接结构相比,2-邻接结构实现了最佳的检测性能和检测效率,验证了两邻近聚合的优越性。
Table 4 The ablation experiment results on USO data set.
表4 USO数据集上的烧蚀实验结果。
The activation heat map of the intermediate feature is obtained as shown in Fig. 10 , the lower-level features contain more texture details, which is beneficial to the detection of small objects, while the higher-level features contain obvious position information. Each progressive operation fuses two adjacent features with small differences. In Fig. 10 , the irrelevant noise is suppressed in the process of feature aggregation, and the features of objects are enhanced, achieving the desired effect.中间特征的激活热图如图10所示,低层特征包含更多的纹理细节,有利于小物体的检测,而高层特征包含明显的位置信息。每个渐进操作融合两个具有微小差异的相邻特征。在图10中,在特征聚合的过程中抑制了无关噪声,增强了对象的特征,达到了预期的效果。
The activation heat map of the intermediate feature is obtained as shown in Fig. 10 , the lower-level features contain more texture details, which is beneficial to the detection of small objects, while the higher-level features contain obvious position information. Each progressive operation fuses two adjacent features with small differences. In Fig. 10 , the irrelevant noise is suppressed in the process of feature aggregation, and the features of objects are enhanced, achieving the desired effect.中间特征的激活热图如图10所示,低层特征包含更多的纹理细节,有利于小物体的检测,而高层特征包含明显的位置信息。每个渐进操作融合两个具有微小差异的相邻特征。在图10中,在特征聚合的过程中抑制了无关噪声,增强了对象的特征,达到了预期的效果。
Fig. 10. The activation heat map of intermediate features.
图10 中间特征的激活热图。
4.3.3. FMSPP & data enhancement strategy
4.3.3.FMSPP和数据增强策略
To investigate the impact of FMSPP module and data enhancement strategy on the overall performance of the network, ablation experiments were conducted on the URPC, the results are shown in Table 5 . The object detection algorithm of YOLOv5s is used as the baseline method, and then FMSPP and data enhancement strategies are added, which are noted as baseline + FMSPP and baseline + Crrp, respectively.The addition of data enhancement strategy improves the algorithm’s P, R and mAP by 0.9%, 1.2% and 0.5%, respectively. the replacement of FMSPP improves the algorithm’s P and mAP improved by 2.2% and 0.6%, respectively, and the singleframe image processing time was reduced by 4 ms and R decreased by 2.1%. The introduction of both FMSPP and data enhancement strategies in the prediction network improves P, R and mAP by 3.1%, 1.9% and 1.3%, respectively, demonstrating that the two strategies can effectively enhance the algorithm’s understanding of the object and realize the improvement of detection accuracy.为了研究FMSPP模块和数据增强策略对网络整体性能的影响,在URPC上进行了消融实验,结果如表5所示。以YOLOv 5s的目标检测算法为基线方法,加入FMSPP和数据增强策略,分别记为baseline + FMSPP和baseline + Crrp,数据增强策略的加入使算法的P、R和mAP分别提高了0.9%、1.2%和0.5%。替换FMSPP后,算法的P和mAP分别提高了2.2%和0.6%,单帧图像处理时间减少了4 ms,R降低了2.1%。在预测网络中同时引入FMSPP和数据增强策略,使P、R和mAP分别提高了3.1%、1.9%和1.3%,证明两种策略能够有效增强算法对对象的理解,实现检测精度的提升。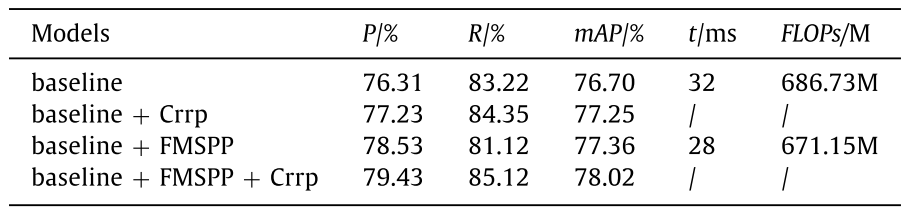
Table 5 Results of FMSPP& data enhancement strategy ablation on URPC data set.
表5 FMSPP和数据增强策略在URPC数据集上消融的结果。
To verify the effectiveness of small object data enhancement strategy and the influence of pasting times on the performance of small object detection, an ablation experiment was conducted on USO data set, the results are shown in Table 6 . The results show that pasting one object is the best setting. With the increase of pasting times, the detection rate of small objects gradually decreases, even lower than the baseline model. This may be due to the gradual destruction of the distribution of original data with the increase of pasting times, resulting in poor performance in the test set.为了验证小目标数据增强策略的有效性以及粘贴次数对小目标检测性能的影响,在USO数据集上进行了消融实验,结果如表6所示。结果表明,粘贴一个对象是最佳设置。随着粘贴次数的增加,小物体的检测率逐渐降低,甚至低于基线模型。这可能是由于原始数据的分布随着粘贴次数的增加而逐渐被破坏,导致在测试集中表现不佳。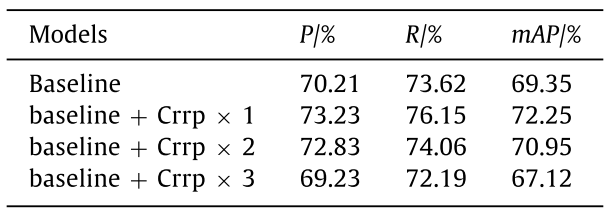
Table 6 Results of small object data enhancement strategy on USO.
表6 USO小目标数据增强策略的结果。
4.4. Qualitative analysis
4.4.定性分析
The partial image test results of our model on the URPC and DUT-USEG datasets are shown in Fig. 11 . In Fig. 11 , in A) there are easily leaking objects that are highly similar to the background, B) and D) have problems such as occlusion, blur, color shift and uneven light, and C) has many objects and a complex environment background. The results show that our model achieves better detection results, good environmental adaptability and stable performance. Blue bounding box represents starfish, red bounding box represents echinus, purple bounding box represents holothurian, and yellow bounding box represents scallop.我们的模型在URPC和DUT-USEG数据集上的部分图像测试结果见图11。在图11中,在A)中,存在与背景高度相似的容易泄漏的对象,B)和D)具有诸如遮挡、模糊、颜色偏移和不均匀光的问题,以及C)具有许多对象和复杂的环境背景。实验结果表明,该模型具有较好的检测效果、良好的环境适应性和稳定的性能。蓝色边框代表海星,红色边框代表海胆,紫色边框代表海参,黄色边框代表扇贝。
Fig. 11. The results of our model on the URPC and DUT-USEG datasets
图11 我们的模型在URPC和DUT-USEG数据集上的结果
For the detection effect of small and fuzzy objects, the comparison between the detection results of our model and YOLOv5s on USO data set is shown in Fig. 12 , (a) is the result of YOLOv5s, and (b) is the result of our model.对于小目标和模糊目标的检测效果,我们的模型和YOLOv5s在USO数据集上的检测结果对比如图12所示,(a)是YOLOv5s的结果,(b)是我们的模型的结果。
Fig. 12. The comparison between the detection results of our model and the YOLOv5s on USO data set.
图12 我们的模型和YOLOv5s在USO数据集上的检测结果的比较。
Both scene images contain a large number of small objects and fuzzy objects. By comparing 1) and 2), it can be seen that 2) the sea cucumber in the purple box that 1) failed to detect and some fuzzy tiny sea urchin objects are detected. It can be seen from the comparison between 3) and 4) that in 4) the starfish in the blue box and the faint tiny sea urchin object in the distance that 3) failed to detect are detected. The above results prove that our optimization strategy can effectively im prove the detection performance for underwater fuzzy objects and small objects.这两种场景图像都包含大量的小对象和模糊对象。通过比较1)和2),可以看出2)1)未能检测到的紫色盒子中的海参和一些模糊的微小海胆物体被检测到。从3)和4)的比较可以看出,在4)中检测到了蓝色盒子中的海星和3)未能检测到的远处微弱的微小海胆物体。实验结果表明,该优化策略能有效地提高水下模糊目标和小目标的检测性能。
Fig. 12. The comparison between the detection results of our model and the YOLOv5s on USO data set.
图12 我们的模型和YOLOv5s在USO数据集上的检测结果的比较。
Another major challenge for underwater object detection is the interference caused by complex background. Fig. 13 shows the detection results of our model on URPC and DUT-USEG data sets for objects which are easy to mix and leak in complex background. In a) and c), the background is very complex, the object sea urchin is small, and the object starfish features are weak; B) and d) are highly similar in the background characteristics of the object sea, and the characteristics of the object starfish are weak, which makes it difficult to detect. Our model has achieved good detection results in the above scenarios, which verifies the validity of our strategy in detecting small objects and confusing weak objects.水下目标检测的另一个主要挑战是复杂背景造成的干扰。图13显示了我们的模型在URPC和DUT-USEG数据集上对复杂背景中容易混合和泄漏的对象的检测结果。在a)和c)中,背景非常复杂,目标海胆较小,目标海星特征较弱; B)和d)中目标海的背景特征高度相似,目标海星特征较弱,难以检测。该模型在上述场景下均取得了较好的检测效果,验证了该策略在检测小目标和混淆弱目标方面的有效性。
Fig. 13. The detection results of our model on URPC and DUT-USEG.
图十三 我们的模型在URPC和DUT-USEG上的检测结果。
4.5. Quantitative analysis
4.5.定量分析
To further analyze the accuracy of object detection and positioning of our model, it is suggested to classify each extracted object in the positive training images into one of the following five situations: correct positioning (overlap ≥ 50%), recommendation (completely) inside the ground truth, recommendation (completely) inside the ground truth, and none of the above, but nonzero overlap, low overlap and no overlap. The detection results on URPC and DUT-USEG datasets are shown in (a) and (b) of FIG. 14 , respectively, showing the frequency of these five cases for each object category and the average error of all categories of our model. In Fig. 14 , the average positioning accuracy of our model can reach more than 70% for a variety of different types of objects on the two data sets, which basically avoids the error problem of no overlap.为了进一步分析我们的模型的对象检测和定位的准确性,建议将正训练图像中的每个提取的对象分类为以下五种情况之一:正确定位(重叠≥ 50%),推荐(完全)在地面真理内,推荐(完全)在地面真理内,以及以上都没有,但非零重叠,低重叠和无重叠。图14的(a)和(B)分别示出了URPC和DUT-USEG数据集上的检测结果,示出了针对每个对象类别的这五种情况的频率和我们的模型的所有类别的平均误差。在图14中,我们的模型对于两个数据集上的各种不同类型的物体,平均定位精度可以达到70%以上,基本上避免了没有重叠的误差问题。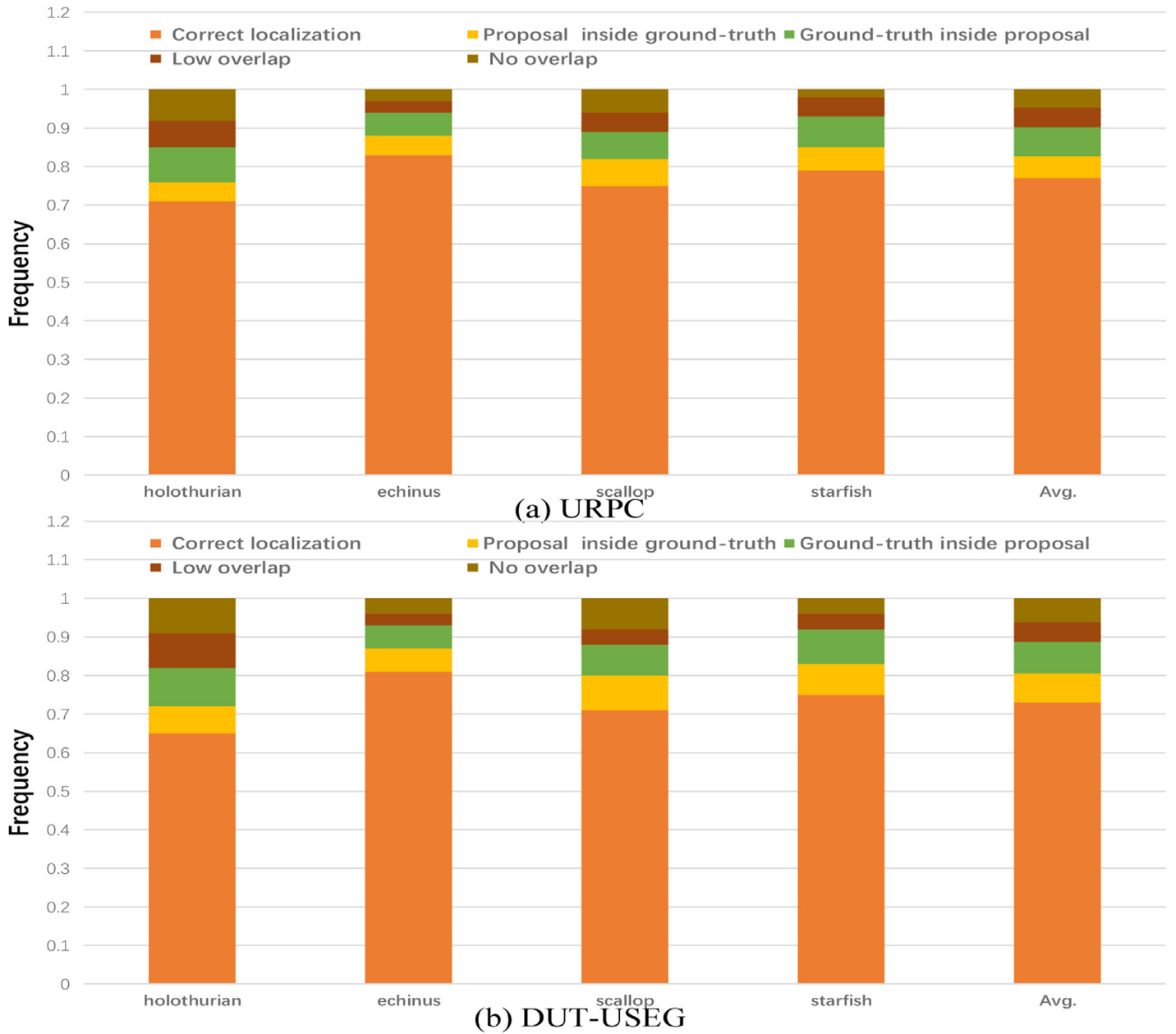
Fig. 14. The positioning results of our model on URPC and DUT-USEG.
图14 模型在URPC和DUT-USEG上的定位结果。
To verify the advancement and superiority of our model, several current most advanced models are used to conduct comparative experiments on URPC dataset with the detector proposed in this paper. YOLOv5s, HCE [30] , UARO [6] , APAN [31] and FAYOLOV5 [32] are single-stage detectors, and YOLOv5s is lightweight detectors. ThunderNet3 [33] , SA-FPN [34] , and LUDet [35] are lightweight two-stage detectors. To make a fair comparison, this paper directly uses the test results provided by the literatures or the open source code to evaluate the models, and all models use the same image enhancement method.为了验证该模型的先进性和优越性,我们使用了几种当前最先进的模型,并在URPC数据集上与本文提出的检测器进行了对比实验。YOLOv 5s、HCE [30]、UARO [6]、APAN [31]和FAYOLOV 5 [32]是单级探测器,YOLOv 5s是轻量级探测器。ThunderNet 3 [33],SA-FPN [34]和LUDet [35]是轻量级的两级检测器。为了进行公平的比较,本文直接使用文献提供的测试结果或开源代码对模型进行评价,所有模型都使用相同的图像增强方法。
The comparative results are shown in Fig. 15 and Table 7 , our model achieves the optimal detection effect of 88.56% and 85.16% in the P and mAp respectively, and the R ranks the second with 86.82%. The detection efficiency can meet the requirement of realtime, and the inference time of a single frame is 63ms.对比结果如图15和表7所示,我们的模型在P和mAp中分别达到了88.56%和85.16%的最佳检测效果,R以86.82%排名第二。检测效率满足实时性要求,单帧推理时间为63 ms。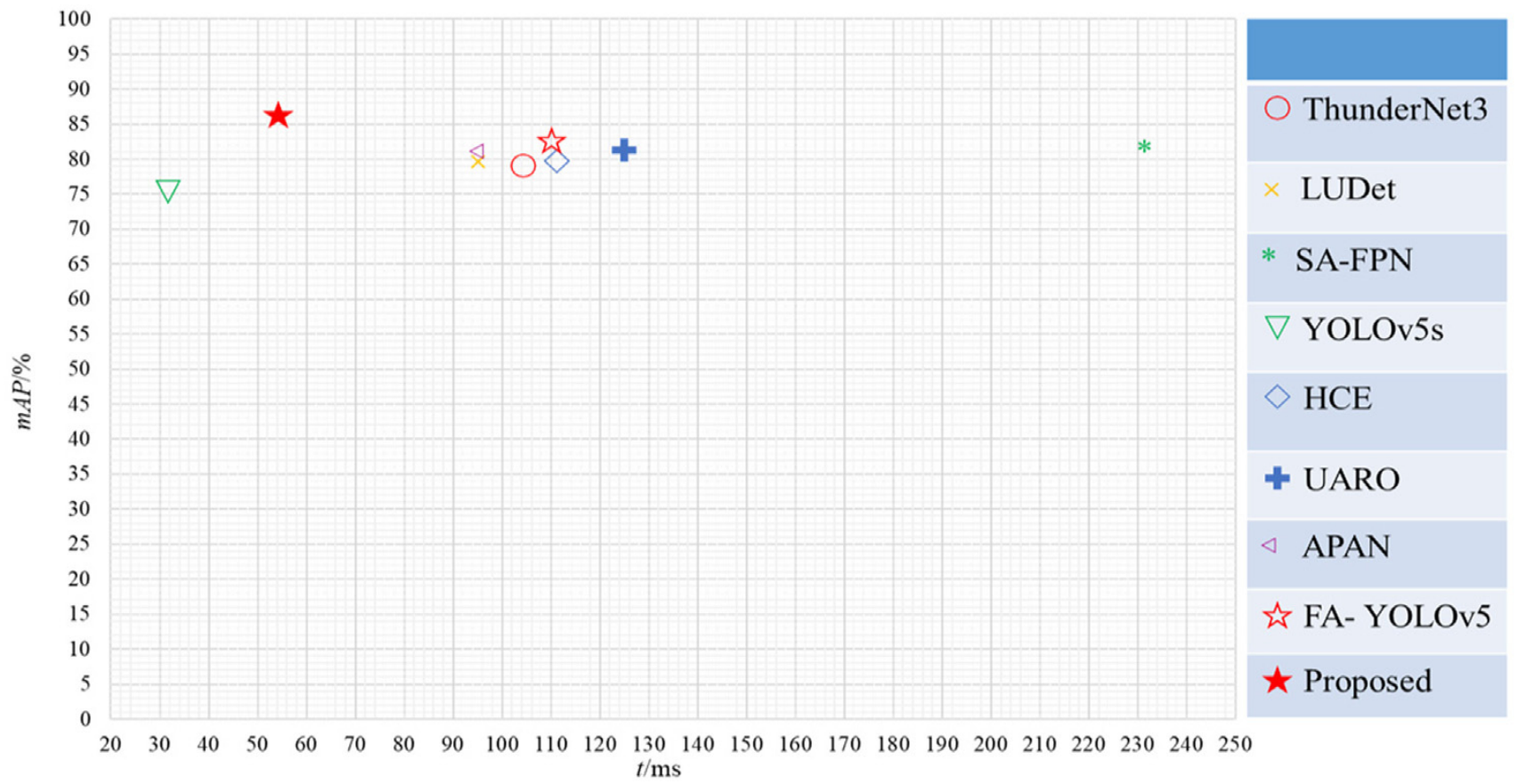
Fig. 15. Results of performance comparison of various detectors on URPC data set.
图15 各种检测器在URPC数据集上的性能比较结果。
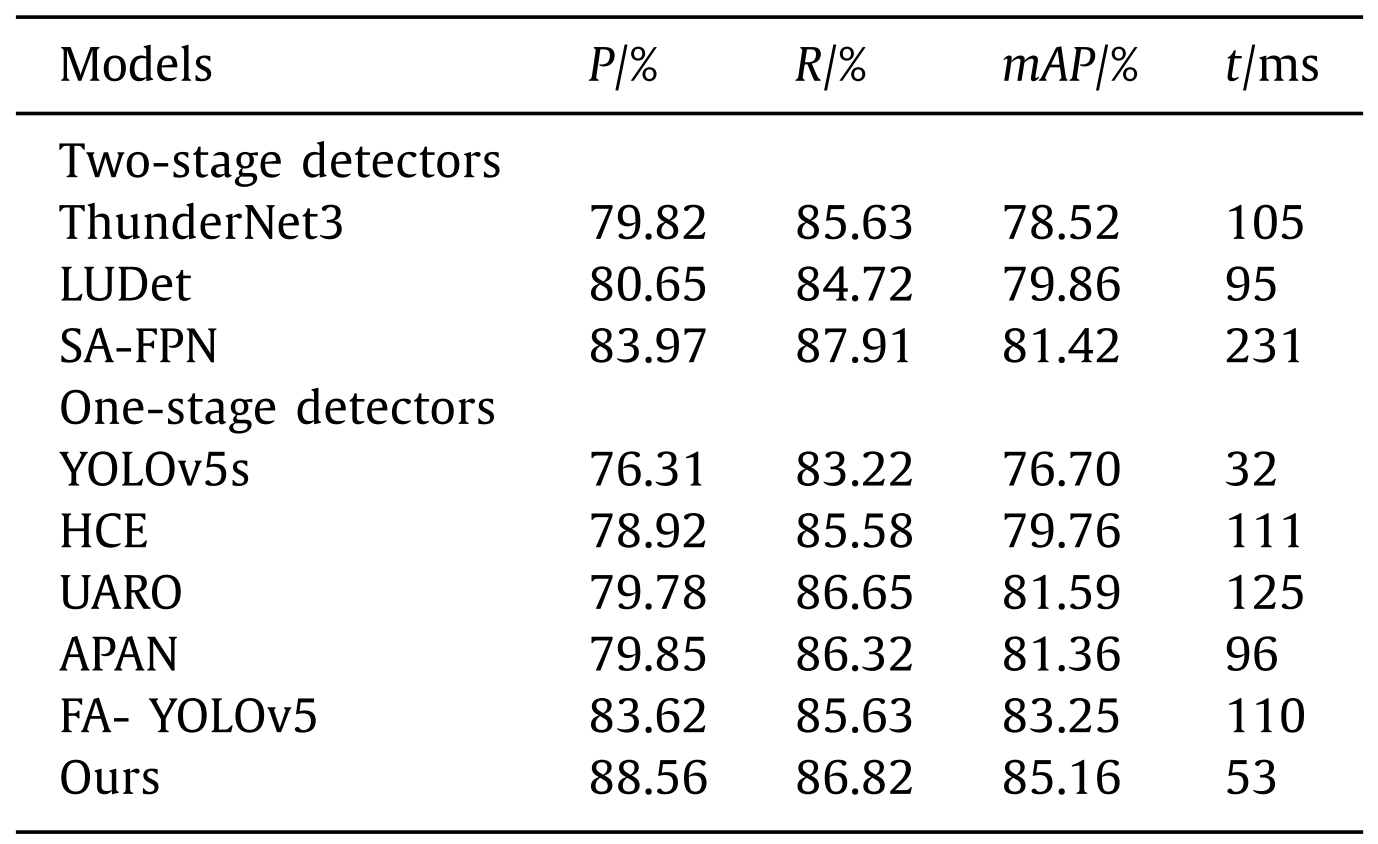
Table 7 Results of performance comparison of various detectors on URPC data set.
表7 各种检测器在URPC数据集上的性能比较结果。
We further compare our model with several other advanced one-stage detectors FA- YOLOv5, APAN and UARO on URPC and DUT-USEG data sets, and the corresponding precision-regression curves are shown in Fig. 16 . The accuracy and regression rate of our model are obviously better than those of other one-stage detectors.我们进一步在URPC和DUT-USEG数据集上将我们的模型与其他几个先进的一级检测器FA-YOLOv 5、APAN和UARO进行比较,相应的精度回归曲线如图16所示。该模型的准确率和回归速度明显优于其他一级检测器。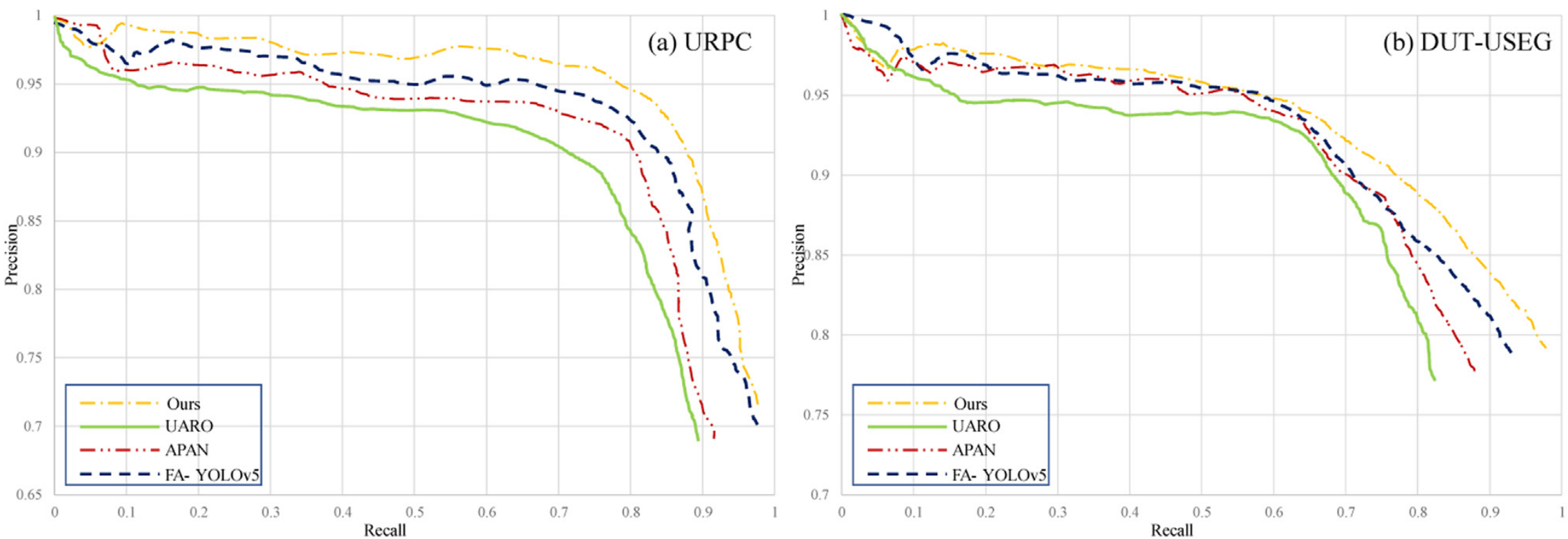
Fig. 16. The P-R curve of multi-class models on URPC and DUT-USEG.
图16 URPC和DUT-USEG上多类模型的P-R曲线。
We further compare our model with several other advanced detectors FA- YOLOv5, APAN, SA-FPN on USO, the results are shown in Table 8 . The performance of our model on underwater fuzzy small object is obviously better than other models, with P increasing by 9% ∼10%, R increasing by 7% ∼8% and mAP increasing by about 7%.我们进一步将我们的模型与USO上的其他几种先进探测器FA-YOLOv 5、APAN、SA-FPN进行了比较,结果如表8所示。该模型对水下模糊小目标的识别性能明显优于其他模型,P提高了9%~ 10%,R提高了7%~ 8%,mAP提高了约7%。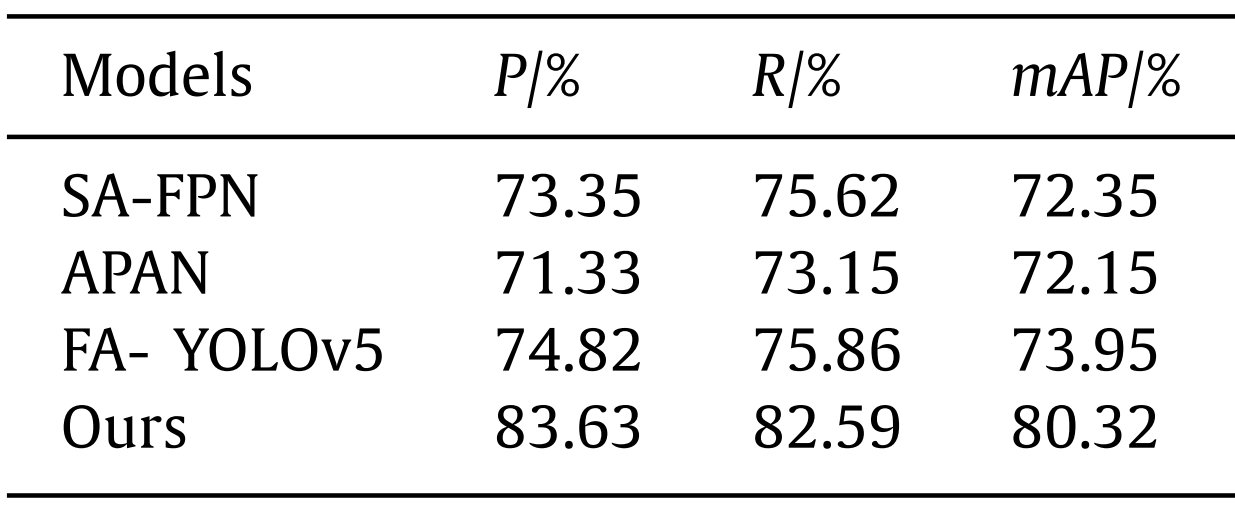
Table 8 Experimental results of performance comparison of various detectors on USO data set.
表8各种探测器在USO数据集上的性能比较实验结果。
Table 9 compares the complexity of our model with that of FA- YOLOv5, YOLOV5, SA-FPN on UPRC data set, and usually describes the complexity of the model by the amount of computation (FLOPs) and the number of Parameters [44]. Our network size is only 5.86M, which is 65.3% of SA-FPN model parameters, and FLOPs drops by about 60%. Our model parameters are similar to YOLOv5s, and FLOPs only increases about 22.5% compared with YOLOv5s.表9在UPRC数据集上比较了我们的模型与FA-YOLOV 5、YOLOV 5、SA-FPN的复杂度,通常通过计算量(FLOP)和参数数量来描述模型的复杂度[44]。我们的网络规模仅为5.86M,是SA-FPN模型参数的65.3%,FLOPs下降了约60%。我们的模型参数与YOLOv 5s相似,FLOP与YOLOv 5s相比仅增加约22.5%。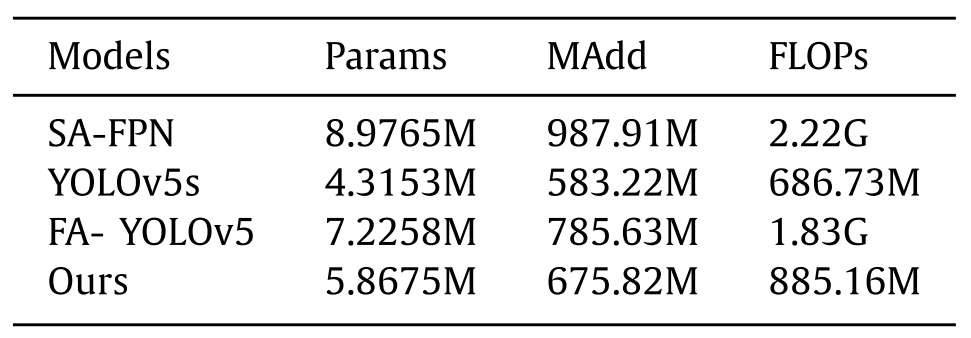
Table 9 Complexity comparison results of multiple models on UPRC data set.
表9 UPRC数据集上多个模型的复杂性比较结果。
5. Conclusions
This paper designs a novel feature enhancement and progressive dynamic aggregation strategy, and proposes a new underwater object detection model based on YOLOv5s model to solve two challenges the Underwater object detection faces: 1) small objects are fuzzy and tiny 2) The distinction between object and background is low. The adjacent aggregation mechanism and a dynamic aggregation module can suppress conflicting information in multi-scale feature fusion and prevent small objects from being submerged. The Copy-reduce-rotate-paste data augmentation strategy can improve the contribution of the small object to the loss function, making the training more balanced. The feature enhancement gating module and FMSPP module is proposed to obtain stronger texture and contour feature description capabilities and reduce the interference of underwater complex environmental noise. Our model performs well on the URPC and DUT-USEG data sets, and has significant advantages in detection accuracy and efficiency compared with the current mainstream object detectors. However, the complexity and computational efficiency of our model still have much room for improvement. In the next step, we will continue to study how to further improve the detection efficiency on the premise of ensuring the detection accuracy, and make lightweight improvements to the model to apply to the autonomous object detection of underwater robots.针对水下目标检测面临的两大挑战:1)小目标模糊、微小; 2)目标与背景的区分度低。设计了一种新的特征增强和渐进式动态聚合策略,提出了一种基于YOLOv 5s模型的水下目标检测模型。相邻聚合机制和动态聚合模块可以抑制多尺度特征融合中的冲突信息,防止小目标被淹没。复制-减少-旋转-粘贴数据增强策略可以提高小对象对损失函数的贡献,使训练更加平衡。为了获得更强的纹理和轮廓特征描述能力,降低水下复杂环境噪声的干扰,提出了特征增强选通模块和FMSPP模块。我们的模型在URPC和DUT-USEG数据集上表现良好,与当前主流的目标检测器相比,在检测精度和效率上具有显著优势。然而,我们的模型的复杂性和计算效率仍然有很大的改进空间。下一步,我们将继续研究如何在保证检测精度的前提下进一步提高检测效率,并对模型进行轻量化改进,以应用于水下机器人的自主目标检测。
GPT解读
这篇文章提出了一种基于YOLOv5s的新型水下目标检测算法,旨在解决水下环境中小目标检测的挑战,包括小目标的模糊性和目标与背景区分度低的问题。文章的核心内容和结构如下:
研究背景:
- 水下目标检测技术在海军沿海防御、渔业养殖、沉船打捞、海洋生态系统研究等领域有广泛应用。
- 水下成像环境的特殊性导致颜色失真、干扰噪声多、纹理特征模糊和对比度低,给目标检测带来挑战。
研究目的:
- 设计一种新的特征增强和渐进式动态聚合策略,提高水下小目标的检测准确性和效率。
方法介绍:
- 特征增强门控模块:用于选择性地增强或抑制多级特征,减少水下复杂环境噪声对特征融合的干扰。
- 特征动态融合模块:通过动态学习融合权重,实现多级特征的渐进式聚合,避免小目标被冲突信息淹没。
- 快速空间金字塔混合池化(FMSPP):基于相同大小的快速混合池化层,增强网络对纹理和轮廓特征的描述能力,减少参数数量,提高泛化能力和分类准确性。
实验结果:
- 在URPC和DUT-USEG数据集上的消融实验和多方法比较实验证明了所提策略的有效性。
- 与当前主流检测器相比,所提出的检测器在检测性能和效率上有明显优势。
实验方法:
- 使用URPC2021水下光学图像数据集和DUT-USEG水下语义分割数据集进行测试。
- 使用精确度(P)、召回率(R)、平均精度(AP)、平均平均精度(mAP)和单张图像推理时间(t)作为评估指标。
结论:
- 提出的模型在URPC和DUT-USEG数据集上表现良好,与当前主流目标检测器相比,在检测准确性和效率上有显著优势。
- 未来的工作将集中在进一步提高检测效率和模型轻量化,以适应水下机器人的自主目标检测需求。
文章还详细介绍了相关研究工作、提出的模型的整体框架、特征增强门控模块、渐进式特征动态聚合策略、数据增强策略、损失函数以及实验环境和应用细节。
1.前人研究的方法
这篇文章中提到了前人在水下目标检测方面的研究方法,并对其进行了讨论。以下是前人研究方法的详细说明:
传统的水下目标检测方法:传统的水下目标检测方法主要是基于图像处理和计算机视觉技术。这些方法通常依赖于手工设计的特征提取器和分类器,如滤波、边缘检测和模板匹配等。然而,由于水下环境的复杂性和噪声干扰等因素,这些方法的性能往往不够稳定和准确。
基于机器学习的水下目标检测方法:近年来,随着深度学习的兴起,基于机器学习的水下目标检测方法取得了显著进展。这些方法使用卷积神经网络(CNN)来学习特征表示,并通过后续的分类器来进行目标检测。其中,基于Faster R-CNN的方法被广泛应用于水下目标检测中。这些方法通过引入区域建议网络(RPN)来生成候选目标框,然后在这些框上进行目标分类和位置回归。
基于深度学习的单阶段检测器:除了基于两阶段检测器的方法,单阶段检测器也被应用于水下目标检测中。这些方法通常具有简单和高效的优势,如YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)。YOLO将目标检测任务视为回归问题,直接通过网络输出目标的边界框和类别概率。这种方法在水下目标检测中也取得了一定的效果。
数据增强方法:为了增强模型的泛化能力和对水下环境的适应性,一些研究者提出了各种数据增强技术。例如,通过改变图像的颜色、亮度、对比度、模糊度和形态学变换等方式,来模拟水下环境中的不同影响因素。此外,还有一些特定的增强方法,如复制-减少-旋转-粘贴(Copy-reduce-rotate-paste)策略,用于增加小目标样本的数量和贡献。
总之,前人研究水下目标检测方法主要包括传统方法和基于深度学习的方法。深度学习方法主要包括两阶段检测器和单阶段检测器。此外,数据增强方法也被广泛应用于提高水下目标检测模型的性能。然而,传统方法在复杂水下环境中往往表现不佳,深度学习方法虽然取得了一定的进展,但仍然存在一些挑战和问题。以上述方法为基础,本文提出了一种基于特征增强和动态融合策略的水下目标检测算法,并通过实验证明了其有效性。
2.作者要解决的问题
作者的研究旨在解决水下目标检测领域面临的几个问题。首先,由于水下环境的噪声和目标尺度的变化,传统的目标检测方法很难从水下图像中提取特征,并且容易错过检测小尺寸目标。其次,水下环境中存在色彩失真、干扰噪声、纹理特征模糊和低对比度等问题,进一步增加了水下目标检测的挑战。
为了解决这些问题,作者设计了一种新颖的特征增强和渐进动态聚合策略,并提出了一种基于YOLOv5s的水下目标检测算法。首先,他们设计了一个特征增强门控模块,通过插值和卷积调整特征的尺寸,并利用门控单元有选择地增强或抑制特征,以减少水下复杂环境噪声对特征融合的干扰。然后,他们设计了相邻特征融合机制和动态融合模块,动态学习融合权重并逐步进行多级特征融合,以抑制多尺度特征融合中的冲突信息,防止小目标被冲突信息淹没。最后,他们提出了一种基于快速混合池化的空间金字塔池结构(FMSPP),该结构可以使网络获得更强的纹理和轮廓特征描述能力,减少参数,并进一步提高泛化能力和分类精度。
通过在URPC和DUT-USEG数据集上进行剖析实验证明了所提策略的有效性。与当前主流的检测器相比,他们的检测器在检测性能和效率方面都取得了明显优势。
总的来说,作者的研究旨在解决水下目标检测领域中特征提取困难和小目标漏检等问题。通过特征增强和动态聚合策略,他们提出了一种新的水下目标检测算法,有效地处理了水下环境的挑战,并取得了显著的检测性能提升。
3.作者通过什么样的方法来解决所提出的研究问题
根据这篇文章,作者提出了一种新颖的特征增强和动态融合策略,以解决传统目标检测方法在水下环境中提取特征困难、小目标漏检等问题。下面是详细的方法说明:
特征增强门控模块:设计了一个特征增强门控模块,利用插值和卷积操作来调整特征的大小,并通过门控单元来有选择地增强或抑制特征。该模块采用通道注意力、空间注意力、全局注意力、残差连接和RF操作等技术,以增强特征描述能力和提高检测精度。
动态特征融合模块:设计了相邻特征融合机制和动态融合模块,以动态地学习融合权重并逐步地进行多层次特征融合。这样可以抑制多尺度特征融合中的冲突信息,防止小目标被冲突信息淹没。
快速混合池塘的FMSPP结构:提出了一种基于相同尺寸的快速混合池塘结构(FMSPP),它能够使网络获得更强的纹理和轮廓特征描述能力,减少参数,进一步提高泛化能力和分类精度。
此外,使用了Copy-reduce-rotate-paste的数据增强策略,通过增加小目标样本的数量和对损失函数的贡献,解决了训练数据中小目标和大目标之间的不平衡问题。
通过实验验证了所提出方法的有效性,对URPC和DUT-USEG数据集进行了割除实验和多种方法的比较实验,结果表明,与当前主流的目标检测器相比,该方法在检测性能和效率上具有明显的优势。
总之,作者通过设计特征增强和动态融合策略以及快速混合池塘结构,结合数据增强策略,解决了水下目标检测中特征提取和小目标漏检等问题。通过实验证明了该方法的有效性和性能优势
4.作者通过哪些实验得出来了这些结果
在这篇文章中,作者通过多个实验和试验分析来验证和评估提出的水下目标检测算法的性能。
首先,作者进行了一系列的消融实验来研究动态融合和特征增强策略对检测准确度的影响。实验结果显示,动态融合对检测性能的改进更为显著,相较于特征增强,提升了mAP、P和R等评价指标。此外,作者还验证了相邻特征融合结构的有效性,其中2个相邻结构实现了最佳的检测性能和效率。
其次,对模型在不同数据集上的检测结果进行了质量分析,展示了其在准确检测小而模糊的目标、适应复杂背景和处理具有挑战性的场景方面的能力。在定量分析方面,对目标检测和定位的准确性进行了评估,结果显示模型在各种类型目标上达到了超过70%的平均定位精度。
此外,作者还将模型的性能与其他先进检测器进行了比较,包括单阶段和两阶段的模型。结果显示,提出的模型在精确度、mAP和R等方面优于其他模型,尤其在检测水下模糊小目标方面表现出更高的优势。
总的来说,通过在多个实验中验证和分析,本文得出了提出的水下目标检测算法的有效性,并强调了其在水下环境中检测小、模糊和具有挑战性目标方面的改进性能。
5.实验部分的不足
根据文章中的描述,实验部分存在以下一些不足之处:
实验设计方面:文章没有明确提到采用的随机分割训练集和测试集的方法,也未详细说明采用的交叉验证策略。这些细节对于确保实验的可靠性和结果的泛化能力非常重要。
数据集选择:文章提到使用了URPC和DUT-USEG数据集进行实验评估,但在论文中没有提供这些数据集的详细信息,包括数据集的规模、数据集的特点以及用于评估的标准。这使得读者难以评估实验结果的全面性和可靠性。
对比实验设计不足:文章提到了与其他先进检测器的比较,但没有提供详细的对比实验设置和结果分析。比较的范围和依据也未明确说明,这些信息对于读者更好地理解该算法在检测性能方面的优势和特点很重要。
参数选择和敏感性分析:文章没有提及对于算法中的关键参数进行敏感性分析,即改变参数后检测结果的变化情况。这样的分析可以帮助读者更好地理解参数设置的影响,并确定算法的鲁棒性和稳定性。
综上所述,虽然文章在实验部分通过一系列的实验和分析来验证算法的性能,但是仍然存在一些不足之处,包括实验设计的缺失、缺乏对数据集的详细说明、对比实验设计的不足以及缺乏参数敏感性分析。完善这些方面将有助于提高实验的可信度和结果的解释性。
6.作者使用该方法的优点
根据这篇文章,作者使用的水下目标检测方法具有以下优点:
特征增强策略:作者设计了特征增强门控模块,用于有选择地增强或抑制多尺度特征,并降低水下复杂环境噪声对特征融合的干扰。这样可以提高前景和背景之间的区分度,从而改善水下目标检测的准确性。
动态融合策略:作者提出的动态融合模块可以根据目标的尺度动态调整特征融合的权重。这种策略可以逐步地聚合相邻层的特征信息,避免并解决了多尺度特征融合中的冲突问题。通过动态融合,可以更好地保留重要信息并抑制噪声干扰。
快速空间金字塔混合池化(FMSPP):文章提出了一种基于相同尺寸的快速空间金字塔混合池化结构,它能够提供更强的纹理和轮廓特征描述能力,同时减少参数数量,进一步提高模型的泛化能力和分类准确性。
数据增强策略:作者采用了Copy-reduce-rotate-paste的数据增强策略,增加了小目标生成的正样本数量,并通过增加它们在损失函数中的贡献来平衡训练过程。这有效地提高了模型对小目标的检测能力。
检测性能优势:通过与其他先进的水下目标检测器进行比较实验,作者的方法在检测性能和效率方面取得了明显的优势。相较于当前主流的目标检测器,本方法在精确度、mAP、召回率等评估指标上表现出明显的优势。
7.作者使用该方法的缺点
根据这篇文章,作者使用的水下目标检测方法在实验部分存在一些缺点:
实验设计方面:文章没有明确说明随机分割训练集和测试集的方法,也未详细说明采用的交叉验证策略,这些细节对实验的可靠性和结果的泛化能力非常重要。
数据集选择:文章提到使用了URPC和DUT-USEG数据集进行实验评估,但未提供这些数据集的详细信息,如数据集规模、数据集特点和评估标准。这使得读者难以评估实验结果的全面性和可靠性。
对比实验设计不足:文章提到与其他先进检测器的比较,但未提供详细的对比实验设置和结果分析。比较的范围和依据也未明确说明,这些信息有助于读者更好地理解该算法在检测性能方面的优势。
缺乏详细的计算和内存消耗分析:文章未提供关于该方法的计算和内存消耗的详细分析,这对于评估算法的实用性和可部署性非常重要。
综上所述,这些缺点可能限制了读者对于该水下目标检测方法在不同场景和数据集上推广应用的能力。
8.论文的创新点主要体现在以下几个方面
根据这篇文章,论文的创新点主要体现在以下几个方面:
特征增强和动态融合策略:作者设计了特征增强门控模块,能够有选择地增强或抑制多尺度特征,以减少水下复杂环境噪音对特征融合的干扰。动态融合模块可以根据目标尺度动态调整融合权重,逐步聚合相邻特征,并有效地抑制冲突信息。这两个策略的结合,提升了水下目标检测的准确性和鲁棒性。
快速空间金字塔混合池化(FMSPP):该方法引入了FMSPP模块,通过随机选择最大池化和平均池化来解决两种不同池化方法的问题,并利用通道连接将池化层的输出进行连接。这种池化方法综合了两种方法的优点,有效提取特征,并减少了特征维度。
邻近特征动态聚合结构:论文提出了一种邻近特征动态聚合结构,通过动态聚合不同尺度的邻近特征,有效地抑制冲突信息,提高目标检测的准确性和鲁棒性。该结构逐步聚合相邻特征,避免了噪声问题,并通过动态聚合模块保留重要信息。
实验评估和性能分析:作者通过实验对提出的水下目标检测算法进行了全面的评估和性能分析。实验结果表明,该方法在水下目标检测任务中表现出较高的准确性和鲁棒性,并超越了其他先进的检测器。这些实验结果对于验证算法的效果和可行性非常重要,可以为进一步改进和应用提供参考。