Underwater target detection based on Faster R-CNN and adversarial occlusion network
基于Faster R-CNN和对抗性遮挡网络的水下目标检测
ABSTRACT
Underwater target detection is an important part of ocean exploration, which has important applications in military and civil fields. Since the underwater environment is complex and changeable and the sample images that can be obtained are limited, this paper proposes a method to add the adversarial occlusion network (AON) to the standard Faster R-CNN detection algorithm which called Faster R-CNN-AON network. The AON network has a competitive relationship with the Faster R-CNN detection network, which learns how to block a given target and make it difficult for the detecting network to classify the blocked target correctly. Faster R-CNN detection network and the AON network compete and learn together, and ultimately enable the detection network to obtain better robustness for underwater seafood. The joint training of Faster R-CNN and the adversarial network can effectively prevent the detection network from overfitting the generated fixed features. The experimental results in this paper show that compared with the standard Faster R-CNN network, the increase of mAP on VOC07 data set is 2.6%, and the increase of mAP on the underwater data set is 4.2%.水下目标检测是海洋探测的重要组成部分,在军事和民用领域都有重要的应用。针对水下环境复杂多变,可获取的样本图像有限的特点,提出在标准Faster R-CNN检测算法中加入对抗性遮挡网络(AON)的Faster R-CNN-AON网络。AON网络与Faster R-CNN检测网络存在竞争关系,Faster R-CNN检测网络学习如何阻止给定目标,使检测网络难以正确分类被阻止的目标。更快的R-CNN检测网络和AON网络一起竞争和学习,最终使检测网络对水下海鲜获得更好的鲁棒性。Faster R-CNN和对抗网络的联合训练可以有效防止检测网络过度拟合生成的固定特征。本文的实验结果表明,与标准Faster R-CNN网络相比,VOC 07数据集上的mAP提高了2.6%,水下数据集上的mAP提高了4.2%。
1.Introduction
Oceans make up most of the earth’s total area, and about 71% of the earth’s surface is covered by sea water. In recent years, with the development of science and technology and the continuous increase of human survival needs, the resources on land is overexploited. Many developed countries in the world have turned their attention to marine resources. Nowadays, countries are increasingly competing for maritime territory, which makes the exploration, development and utilization of the ocean more and more important. At present, there are two main ways to obtain underwater information: underwater sonar technology and underwater optical imaging technology. Compared with underwater sonar technology, underwater optical imaging technology has the advantages of intuitive target detection, high imaging resolution and high information content, which is more suitable for target detection in a short distance. In recent years, most of the underwater detection depends on the divers. The long-term diving operation and the complex underwater environment bring a great burden to their health. Therefore, the research on underwater object detection is particularly important.海洋占地球总面积的大部分,大约71%的地球表面被海水覆盖。近年来,随着科学技术的发展和人类生存需求的不断增加,陆地上的资源被过度开发。世界上许多发达国家都把目光投向了海洋资源。如今,各国对海洋领土的争夺日益激烈,这使得对海洋的勘探、开发和利用变得越来越重要。目前,水下信息的获取主要有两种方式:水下声纳技术和水下光学成像技术。与水下声纳技术相比,水下光学成像技术具有目标探测直观、成像分辨率高、信息量大等优点,更适合于近距离目标探测。近年来,水下探测大多依靠潜水员进行。长期的潜水作业和复杂的水下环境给他们的健康带来了很大的负担。因此,对水下目标检测的研究就显得尤为重要。
At present, there have been some different classifications for underwater target detection. In the paper, in order to simplify the analysis, the current underwater target detection methods are classified into two major categories. One is based on traditional target detection method, and the other is based on deep learning target detection method.目前,水下目标检测技术已经有了不同的分类。为了简化分析,本文将现有的水下目标检测方法分为两大类。一种是基于传统的目标检测方法,另一种是基于深度学习的目标检测方法。
For optical image, the traditional method is based on pixel and feature. For sonar image, echo based method is a proper way to deal with target detection problem. The principle of pixel-based detection method is to detect the target by comparing whether the gray level of each pixel exceeds a certain threshold value. It includes two aspects. One is constant false alarm rate (CFAR) algorithm (Kalyan and Balasuriya, 2004) which includes cell averaging-constant false alarm rate (CA-CFAR) algorithm (Aalo et al., 2015), order statisticsconstant false alarm rate (OS-CFAR) algorithm (Villar et al., 2015), accumulated cell averaging-constant false alarm rate (ACA-CFAR) algorithm (Tanuja, 2016) and accumulated cell averaging-constant false alarm rate 2-D(ACA-CFAR 2-D) algorithm (Acosta and Villar, 2015). Another is change detection algorithm which includes image difference algorithm (Radke et al., 2005) and bitemporal change detection algorithm (Wei and Leung, 2012). The limitation of pixel-based detection method is that it needs a priori hypothesis because of its slow operation speed, and the detection ability declines when there is multi-target interference. The principle of feature-based detection method is to determine the region of interest by detecting an obvious feature of underwater target. It includes two aspects: one is symbol analysis algorithm, another is change detection algorithm. The limitation of feature-based detection method lies in the large amount of calculation, the difficulty of geometric modeling, and the need to match different features one by one through the model. The principle of echo-based detection method is that the echo signal is different for the material, shape, size, and the like of the underwater target, and a useful echo signal is extracted from the interference signal for detection. Beijbom et al. (2012) proposed a coral coverage method through a number of different scales by color descriptors and texture features. Chuang et al. (2016) estimated the significance of extracted underwater fish texture feature images through phase Fourier transform (Chuang et al., 2016). Zhu et al. (2016) proposed an underwater detection method for feature area fusion. The limitation of the echo detection method is that there is no accurate physical model, the false alarm rate is high and the threshold selection is difficult. And for the severe quality degradation due to light absorption and scattering in water, image enhancement and image restoration is also a useful tool to improve the underwater target detection, and a system review about image enhancement and image restoration is presented by Wang et al. (2019).对于光学图像,传统的方法是基于像素和特征的。对于声纳图像,基于回波的目标检测方法是一种较好的目标检测方法。基于像素的检测方法的原理是通过比较每个像素的灰度值是否超过一定的阈值来检测目标。它包括两个方面。一种是恒定虚警率(CFAR)算法(Kalyan和Balasuriya,2004),其包括小区平均恒定虚警率(CA-CFAR)算法(Aalo等人,2015)、阶矩恒虚警率(OS-CFAR)算法(Villar等人,2015)、累积单元平均恒定虚警率(ACA-CFAR)算法(Tanuja,2016)和累积单元平均恒定虚警率2-D(ACA-CFAR 2-D)算法(Acosta和Villar,2015)。另一种是变化检测算法,其包括图像差分算法(Radke等人,2005)和双时变化检测算法(Wei和Leung,2012)。基于像素的检测方法的局限性在于运算速度慢,需要先验假设,且存在多目标干扰时检测能力下降。基于特征的检测方法的原理是通过检测水下目标的一个明显特征来确定感兴趣区域。它包括两个方面:一是符号分析算法,二是变化检测算法。基于特征的检测方法的局限性在于计算量大,几何建模困难,需要通过模型逐个匹配不同的特征。基于回波的探测方法的原理是,对于水下目标的材质、形状、大小等,回波信号是不同的,从干扰信号中提取有用的回波信号进行探测。Beijbom等人(2012年)提出了一种珊瑚覆盖方法,通过颜色描述符和纹理特征通过许多不同的尺度。Chuang等人(2016)通过相位傅里叶变换估计了提取的水下鱼类纹理特征图像的重要性(Chuang等人,2016年)。Zhu et al.(2016)提出了一种特征区域融合的水下检测方法。回波检测方法的局限性在于没有精确的物理模型,虚警率高,阈值选取困难。由于水中光的吸收和散射会导致图像质量严重下降,图像增强和图像恢复也是改善水下目标检测的有用工具,Wang等人(2019)对图像增强和图像恢复进行了系统综述。
Compared with traditional target detection methods, the target detection method based on deep learning significantly improves the accuracy of target detection. For sonar data set with small valid sample and low Signal-to-Noise Ratios (SNR), Kong et al. (2020) proposed an improved YOLOv3 algorithm for real-time detection called as YOLOv3DPFIN to accomplish the accurate detection of noise-intensive multicategory sonar targets with minimum time consumption. Moniruzzaman et al. (2017) presented a survey for underwater marine object detection based on deep learning while the analysis approaches are categorized according to the object of detection. Lee et al. (2019) reported the empirical evaluation using deep learning based object detection method via style-transferred underwater sonar images. Sung et al. (2019) proposed a detection and removal of crosstalk noise method using a convolutional neural network in the images of forward scan sonar. According to whether candidate regions need to extracts, target detection algorithms based on convolution neural network can divide into two categories: target detection algorithm based on candidate regions and target detection algorithm based on regression (Shen et al., 2017).与传统的目标检测方法相比,基于深度学习的目标检测方法显著提高了目标检测的准确性。针对小有效样本和低信噪比的声纳数据集,Kong等(2020)提出了一种改进的YOLOv3实时检测算法YOLOv3DPFIN,以最小的时间消耗实现对噪声密集型多类别声纳目标的准确检测。Moniruzzaman等人(2017)提出了一项基于深度学习的水下海洋物体检测调查,而分析方法根据检测对象进行分类。Lee et al.(2019)报告了使用基于深度学习的对象检测方法通过风格转换的水下声纳图像进行的经验评估。Sung等人(2019)提出了一种在前向扫描声纳图像中使用卷积神经网络检测和去除串扰噪声的方法。根据是否需要提取候选区域,基于卷积神经网络的目标检测算法可以分为两类:基于候选区域的目标检测算法和基于回归的目标检测算法(Shen et al.,2017年)。
The target detection algorithm based on candidate regions first extracts candidate regions from the whole image, then classifies and regresses the candidate regions to obtain the detection results. Girshick et al. (2014) proposes a method combining candidate regions with convolution neural network: R-CNN. R-CNN has obvious improvement in detection effect, but there is a large number of repeated calculations. Therefore, Girshick (2015) improve a more efficient deep convolutional network: Fast R-CNN, which improves the efficiency of detection. Ren et al. (2017) further proposes Region Proposal Network(RPN), which can realize the sharing of convolution features and reduce the resource consumption of Network training. On the basis of the above algorithm, the improved network, such as Mask R-CNN (He et al., 2017), R-FCN (Dai et al., 2016), has also achieve good detection results.基于候选区域的目标检测算法首先从整幅图像中提取候选区域,然后对候选区域进行分类和回归,得到检测结果。Girshick等人(2014)提出了一种将候选区域与卷积神经网络相结合的方法:R-CNN。R-CNN在检测效果上有明显的提升,但存在大量的重复计算。因此,Girshick(2015)改进了一种更有效的深度卷积网络:Fast R-CNN,提高了检测效率。Ren等人(2017)进一步提出了区域建议网络(RPN),可以实现卷积特征的共享,减少网络训练的资源消耗。在上述算法的基础上,改进的网络,如Mask R-CNN(He et al.,2017)、R-FCN(Dai等人,2016年),也取得了良好的检测效果。
The target detection method based on regression eliminates the operation of candidate region extraction and is an end-to-end target detection algorithm, such as YOLO (Redmon et al., 2016), SSD (Liu et al., 2016), DSSD (Fu et al., 2017) etc. These methods treat target detection as a regression problem and directly use neural network to detect and locate targets from the whole image. This kind of detection method is faster, but the detection effect is slightly inferior.基于回归的目标检测方法省去了候选区域提取的操作,是一种端到端的目标检测算法,如YOLO(雷德蒙et al.,2016)、SSD(Liu等人,2016)、DSSD(Fu等人,这些方法将目标检测视为回归问题,直接使用神经网络从整个图像中检测和定位目标。这种检测方法速度较快,但检测效果稍差。
The current mainstream deep learning target detection algorithm mainly focuses on solving the problem of land scene (Sun et al., 2018). In this paper, the target detection algorithm based on convolutional neural network is introduced into the underwater scene for underwater target detection. Considering the detection speed and accuracy of the algorithm, this paper chooses Faster R-CNN as the basic detection network.目前主流的深度学习目标检测算法主要集中在解决陆地场景的问题(Sun et al.2018年)。本文将基于卷积神经网络的目标检测算法引入到水下场景中进行水下目标检测。考虑到算法的检测速度和准确性,本文选择Faster R-CNN作为基本检测网络。
However, the underwater environment is complex and changeable, the number of underwater target images can be obtained is limited and cannot cover all scenes. In order to solve this problem, this paper proposes to add the adversarial network to the Faster R-CNN detector for training. The goal of the adversarial network is to generate samples that make it difficult for the target detector to classify. On the one hand, the generated samples contain more scenes and increase training samples. On the other hand, they compete with the detection network to learn from each other to improve the detection ability of the detection network.然而,水下环境复杂多变,所能获得的水下目标图像数量有限,无法覆盖所有场景。为了解决这个问题,本文提出将对抗网络添加到Faster R-CNN检测器中进行训练。对抗网络的目标是生成样本,使目标检测器难以进行分类。一方面,生成的样本包含更多的场景,增加了训练样本。另一方面,它们与检测网络竞争,相互学习,以提高检测网络的检测能力。
2.The proposed Faster-RCNN-AON network
This paper considers a feature called occlusion generated by adversarial networks competing with Faster R-CNN detector. This paper proposes an Adversarial Occlusion Network (AON), which learns how to occlude a given target, making it difficult for Faster R-CNN detectors to classify it correctly. Faster R-CNN can acquire better robustness of target detection by competing and learning together with adversarial networks. This paper combine the Faster R-CNN and adversarial network for training, which can effectively prevent the detector from over-fitting the fixed generated features.本文考虑了一种称为遮挡的特征,它是由对抗网络与Faster R-CNN检测器竞争生成的。本文提出了一种对抗性遮挡网络(AON),它学习如何遮挡给定的目标,使得更快的R-CNN检测器很难正确地对其进行分类。更快的R-CNN可以通过与对抗网络的竞争和学习来获得更好的目标检测鲁棒性。本文将Faster R-CNN和对抗网络相结合进行训练,可以有效地防止检测器过度拟合固定生成的特征。
2.1. Overview of Faster R-CNN
2.1.更快的R-CNN概述
In this section, the basic idea of Faster R-CNN is introduced since it is the basis of our proposed new algorithm for underwater target detection.在本节中,介绍了Faster R-CNN的基本思想,因为它是我们提出的水下目标检测新算法的基础。
Faster R-CNN algorithm is a classic work in the field of target detection. Compared with another target detection algorithm Fast RCNN , Faster R-CNN has slightly improved the accuracy of PASCA VOC 2007 (Everingham et al., 2010) data set and greatly improved the speed of image processing. In the test, Faster R-CNN is 10 times faster than Fast R-CNN, and the image processing speed can basically reach 17 FPS (17 frames per second), which can achieve the capability of quasi-real-time processing.更快的R-CNN算法是目标检测领域的经典工作。与另一种目标检测算法Fast RCNN相比,Faster R-CNN略微提高了PASCA VOC 2007的准确性(Everingham等人,2010)数据集,大大提高了图像处理的速度。在测试中,Faster R-CNN比Fast R-CNN快10倍,图像处理速度基本可以达到17 FPS(每秒17帧),可以达到准实时处理的能力。
The overall structure of Faster R-CNN algorithm is shown in Fig. 1, which can be divided into four parts: VOC data set, feature extractor, RPN (Region Proposal Network) and Fast R-CNN network.Faster R-CNN算法的整体结构如图1所示,可以分为四个部分:VOC数据集、特征提取器、RPN(区域建议网络)和Fast R-CNN网络。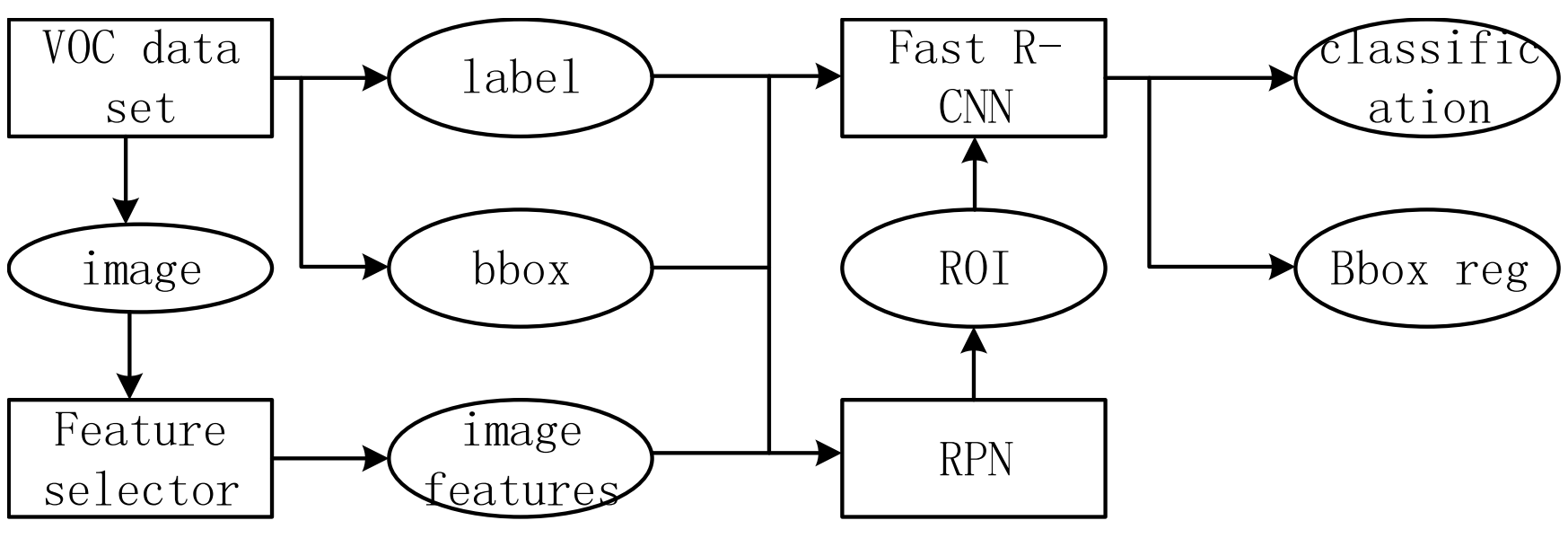
Fig. 1. Structure of Faster R-CNN. The feature selector used in this paper is a convolution neural network VGG16 used for large-scale image recognition.
图1 更快的R-CNN结构。本文采用的特征选择器是一个用于大规模图像识别的卷积神经网络VGG 16。
PASCAL VOC data set.PASCAL VOC数据集。
Data set refers to the image data used to train and test the model, which is processed into the required data format. Currently, the data set commonly used by the Faster R-CNN algorithm is VOC, and store the collected image data in the format of the PASCAL VOC 2007 data set.数据集是指用于训练和测试模型的图像数据,这些数据被处理成所需的数据格式。目前,Faster R-CNN算法常用的数据集是VOC,并以PASCAL VOC 2007数据集的格式存储采集的图像数据。
The VOC data set is used as the input data of Faster R-CNN algorithm, and three values are return as the input of model training after the corresponding input layer processing. These three values are img, bbox and label.VOC数据集作为Faster R-CNN算法的输入数据,经过相应的输入层处理后返回三个值作为模型训练的输入。这三个值分别是img、bbox和label。
Feature Proposal Network. The feature extractor used in this paper is a convolutional neural network VGG16 (Simonyan and Zisserman, 2014) for large-scale image recognition. The whole structure consists of 13 convolutional layers, which are divided into 5 segments according to the pattern of ‘‘2+2+3+3+3”. Each convolutional layer is followed by a maximum pooling layer. In practical application, the more convolutional layers used, the more image features extract, and the better the recognition effect of the network on unknown images.特色提案网络。本文中使用的特征提取器是用于大规模图像识别的卷积神经网络VGG16(Simonyan和Zisserman,2014)。整个结构由13个卷积层组成,按照“2 +2+3+3+3”的模式分为5段。每个卷积层后面是最大池化层。在实际应用中,使用的卷积层越多,提取的图像特征就越多,网络对未知图像的识别效果就越好。
The 13 convolutional layers of VGG16 network can well extract the useful features of the target in the image and obtain the corresponding feature graph, which can be used for the subsequent model training. Here, the maximum pooling layer mainly controls the dimension of feature graph extracted by the convolution layer on the basis of maintaining most features, making the network insensitive to the change of the input image, so as to maintain the scale invariance of the image to the greatest extent.VGG16网络的13个卷积层可以很好地提取图像中目标的有用特征,得到相应的特征图,可以用于后续的模型训练。这里,最大池化层主要是在保持大部分特征的基础上,控制卷积层提取的特征图的维数,使网络对输入图像的变化不敏感,从而最大程度地保持图像的尺度不变性。
Region Proposal Networks.区域提案网络。
RPN is the convolution of network structure, and it can also predict the input images produced by the location of the target candidate box and the probability of the target as part of the real goal. At the same time, in the process of training the network, through the RPN network and Fast R-CNN interval training, network can share the characteristics of convolution, which greatly reduces the amount of parameters need in training and improves the training efficiency. The core contribution of Faster R-CNN is to propose an RPN network instead of the traditional Selective Search method, which reduces the time overhead of candidate region extraction to almost zero (from 2 s to 0.01 s).RPN是网络结构的卷积,它还可以预测输入图像产生的目标候选框的位置和目标作为真实的目标的概率部分。同时,在训练网络的过程中,通过RPN网络和Fast R-CNN区间训练,网络可以共享卷积的特性,大大减少了训练时需要的参数量,提高了训练效率。Faster R-CNN的核心贡献是提出了一种RPN网络,而不是传统的选择性搜索方法,将候选区域提取的时间开销降低到几乎为零(从2 s到0.01 s)。
Fast R-CNN.
Fast R-CNN is responsible for classifying the region of interest and fine-tuning the location border, judging whether the region of interest identified by RPN contains the target and the category of the target, and modifying the location coordinates of the border. RPN only gives 2000 candidate boxes. The Fast R-CNN network needs to continue the classification and position parameter regression on the given 2000 candidate boxes.Fast R-CNN负责对感兴趣区域进行分类并微调位置边界,判断RPN识别的感兴趣区域是否包含目标以及目标的类别,并修改边界的位置坐标。RPN仅提供2000个候选框。Fast R-CNN网络需要继续对给定的2000个候选框进行分类和位置参数回归。
2.2. Adversarial occlusion network2.2.对抗性遮挡网络
Compared with the direct occlusion on the input image to generate the adversarial sample images (or pixel), this paper finds that the operation on the feature map is more efficient. Because the direct generation of counter sample images (or pixels) not only generates a large amount of additional data storage, but also increases the time of network training and reduces efficiency. Therefore, this paper designs an adversarial network to modify features, making the target more difficult to detect.与直接在输入图像上进行遮挡以生成对抗样本图像(或像素)相比,本文发现在特征图上的操作效率更高。因为直接生成反样本图像(或像素)不仅会产生大量的额外数据存储,而且会增加网络训练的时间,降低效率。因此,本文设计了一个对抗网络来修改特征,使得目标更难被检测。
This paper proposes an adversarial occlusion network(AON) to generate occlusion based on the foreground target feature map. In the standard Faster R-CNN network, this paper takes the convolution features of each target candidate region from the output of ROI-pooling layer as the input of the adversarial network. For each feature of the target, AON can attempt to generate an occlusion mask indicating which parts of the feature map is obscured (that is the feature can clear to zero) so that the detector cannot correctly identify the target.本文提出了一种对抗性遮挡网络(AON)的基础上产生的前景目标特征图的遮挡。在标准Faster R-CNN网络中,本文将ROI池层输出的每个目标候选区域的卷积特征作为对抗网络的输入。对于目标的每个特征,AON可以尝试生成遮挡掩模,该遮挡掩模指示特征图的哪些部分被遮挡(即特征可以被清除到零),使得检测器不能正确地识别目标。
This paper use the standard Faster R-CNN as the backbone network structure. This paper also use the ImageNet (Deng et al., 2009) pretrained model to initialize our network. Adversarial network and Faster R-CNN detector share convolution layer and ROI-pooling layer, and then use their own independent full connection layer. Moreover, this paper does not share the parameters of Faster R-CNN in adversarial networks.本文采用标准的Faster R-CNN作为骨干网络结构。本文还使用了ImageNet(Deng et al.,2009)预训练模型来初始化我们的网络。对抗网络和Faster R-CNN检测器共享卷积层和ROI池化层,然后使用自己独立的全连接层。此外,本文没有在对抗网络中共享Faster R-CNN的参数。
In the experiment, this paper first trained the Faster R-CNN detector alone and iterated it for 20k times without joining the adversarial network. On the premise of the model which can identify the target preliminarily, all the parameters of fixed layers are used to train the adversarial network model.在实验中,本文首先单独训练了Faster R-CNN检测器,并在不加入对抗网络的情况下迭代了20 k次。在模型能够初步识别目标的前提下,利用固定层的所有参数训练对抗网络模型。
In Fig. 2, the dotted line part is the adversarial occlusion network proposed in this paper. The overall network framework is combination of the standard Faster R-CNN network and the adversarial occlusion network, which eventually forms the Faster-RCNN-AON network. The training steps of the algorithm in this paper mainly consist of three stages. The first stage is to train the Faster R-CNN network separately for some iterations (10K for example) to obtain a model that can preliminarily identify seafood. In the second stage, the model obtained in the first stage is used to train the adversarial occlusion network and obtain the pre-training model of the anti-occlusion network. The third stage is to make a parameter copy of the model obtained in the first two stages to initialize and train the joint training model. Fig. 3 is the training flow chart of the algorithm in this paper.图2中虚线部分是本文提出的对抗性遮挡网络。整个网络框架是标准Faster R-CNN网络和对抗性遮挡网络的组合,最终形成Faster-RCNN-AON网络。本文算法的训练步骤主要包括三个阶段。第一阶段是单独训练Faster R-CNN网络进行一些迭代(例如10 K),以获得可以初步识别海鲜的模型。在第二阶段中,使用第一阶段中获得的模型来训练对抗性遮挡网络,并获得抗遮挡网络的预训练模型。第三阶段是对前两个阶段得到的模型进行参数复制,以初始化和训练联合训练模型。图3是本文算法的训练流程图。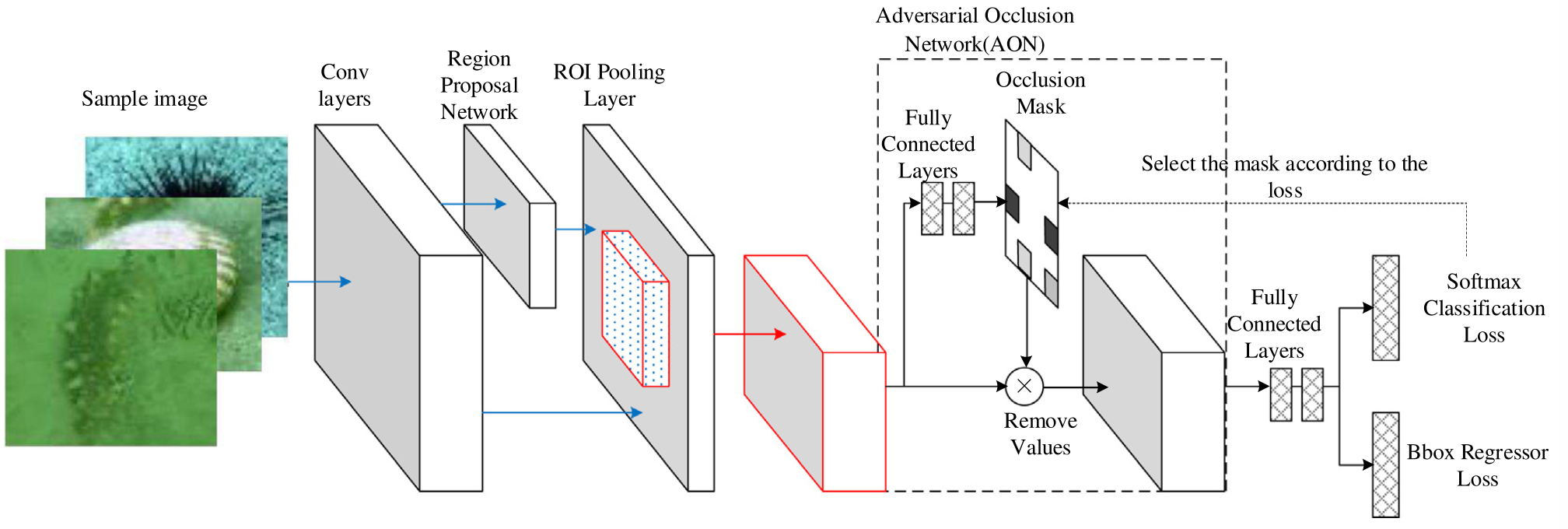
Fig. 2. The structure of Faster-RCNN-AON network. The Adversarial Occlusion Network (AON) uses the output of the ROI pooling layer as its input. AON network predicts the occlusion mask, and then uses it to mask the eigenvalue of the corresponding part on the feature map and passes it to Faster R-CNN for classification.
图二 Faster-RCNN-AON网络的结构。对抗性遮挡网络(AON)使用ROI池化层的输出作为其输入。AON网络预测遮挡掩模,然后用它来掩盖特征图上对应部分的特征值,并将其传递给Faster R-CNN进行分类。
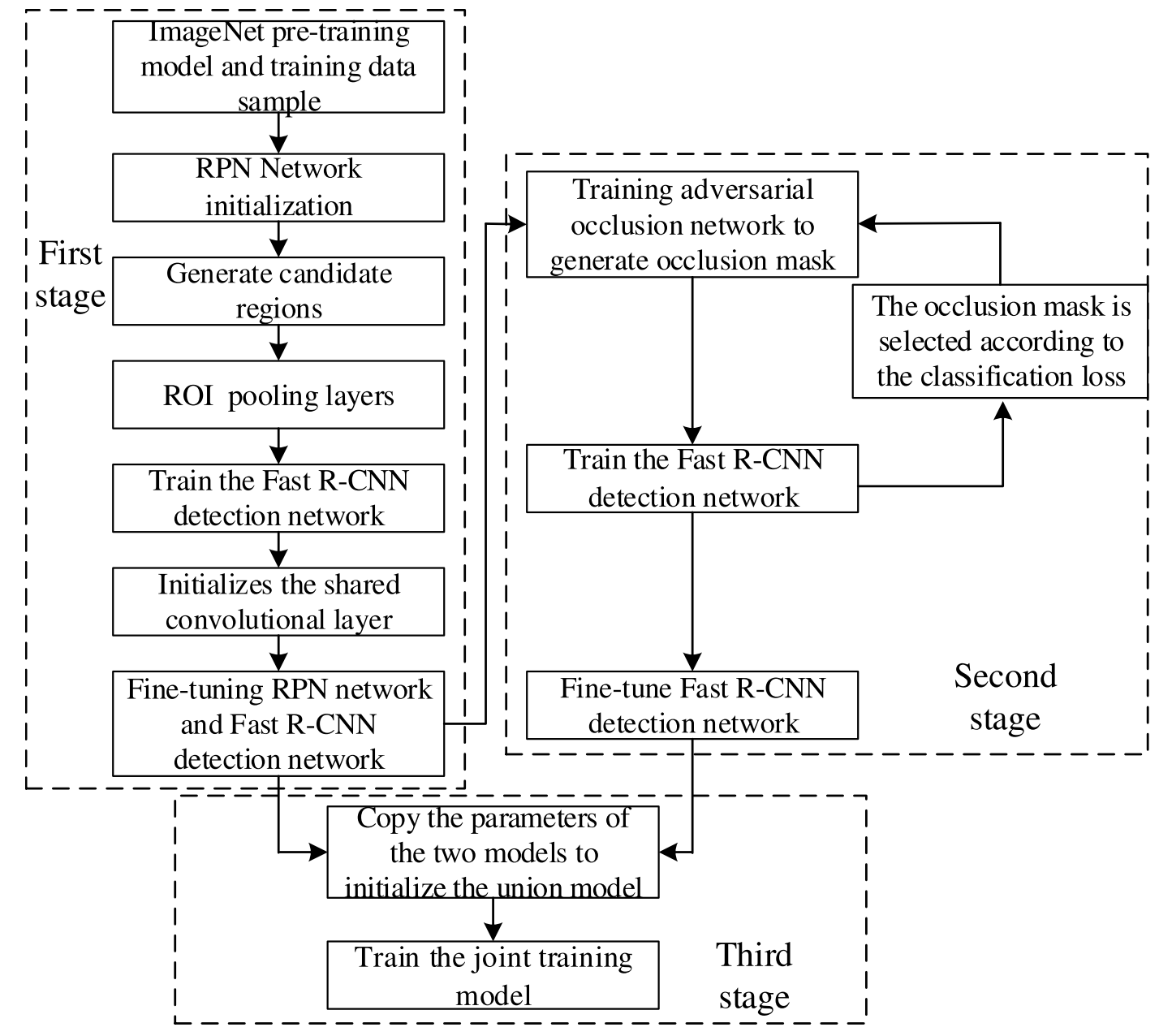
Fig. 3. Training flow chart of the proposed algorithm.
图三.给出了该算法的训练流程图。
2.3. Loss function
2.3.损失函数
The loss function of the standard Faster R-CNN network can be expressed as:标准Faster R-CNN网络的损失函数可以表示为: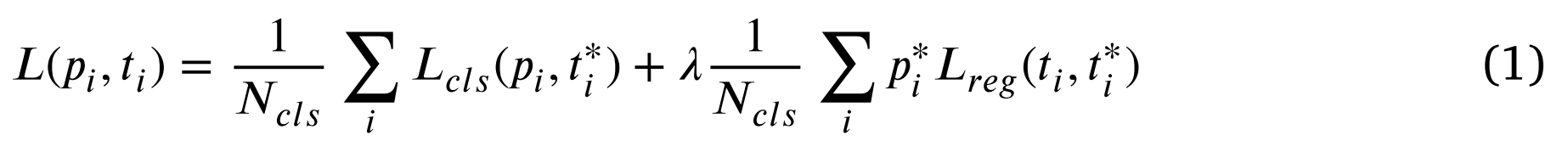
Here, 𝑖 is the index of an anchor in a mini-batch $𝑃𝑖$ is the prediction probability of anchor 𝑖 as the target这里,是小批量中的锚的索引,是作为目标的锚的预测概率$𝑃_𝑖$
The classification loss function is expressed as分类损失函数表示为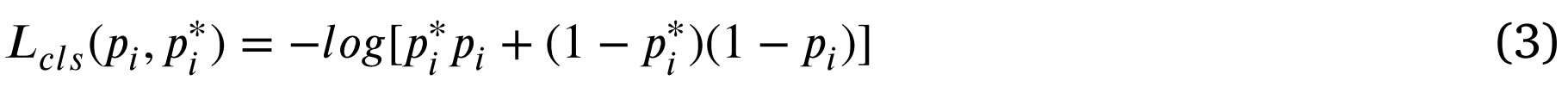
$𝑡_𝑖$ = {$𝑡_𝑥$, $𝑡_𝑦$, $𝑡_𝑤$, $𝑡_ℎ$} is a vector, represents the offset predicted by this anchor. 𝑡∗ 𝑖 is a vector with the same dimension as 𝑡𝑖, represents the actual offset of anchor relative to the ground-truth box.
$𝑡_𝑖$ = {$𝑡_𝑥$, $𝑡_𝑦$, $𝑡_𝑤$, $𝑡_ℎ$} 是一个向量,表示该锚预测的偏移量。𝑡𝑖 是一个维度与 𝑡𝑖 相同的向量,表示锚点相对于地面实况箱的实际偏移量。
The bbox regression loss function can be expressed asbbox回归损失函数可以表示为
where 𝑅 is the $𝑠𝑚𝑜𝑜𝑡ℎ{𝐿𝑖}$ function其中,R是函数$𝑠𝑚𝑜𝑜𝑡ℎ_{𝐿𝑖}$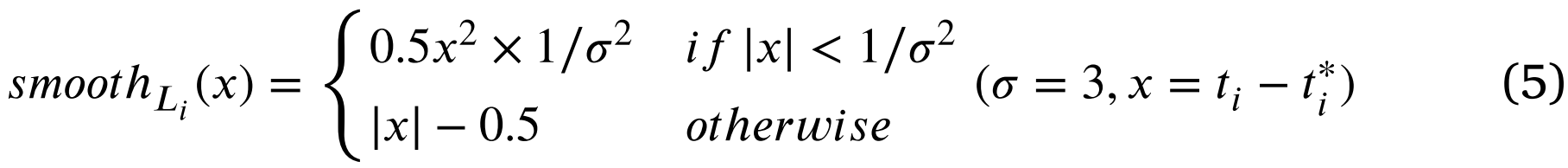
This paper assumes that the original target detector network is represented as 𝑌(𝑋) and the adversarial network is identified as 𝐴(𝑋), where 𝑋 represents 𝐴 candidate region. Assume 𝐶 is the true category of 𝑋. The loss function of the adversarial network can be expressed as:本文假设原始目标检测器网络表示为𝑌(𝑋),对抗网络表示为𝐴(𝑋),其中X表示A候选区域。假设C是的真范畴X。对抗网络的损失函数可以表示为:
The loss function of the target detector remains unchanged. Now the mini-batch contains not only fewer original samples but also some generated adversarial samples. On the one hand, if the adversarial samples generated by the adversarial network can be easily identified and classified by the target detector, the adversarial network can get a higher loss. On the other hand, if the adversarial samples generated by the adversarial network are difficult to identify and classify for the target detector, the adversarial network can get a lower loss, while the target detector can get a higher loss.目标检测器的损失函数保持不变。现在,小批量不仅包含更少的原始样本,还包含一些生成的对抗样本。一方面,如果由对抗网络生成的对抗样本能够被目标检测器容易地识别和分类,则对抗网络可以获得更高的损失。另一方面,如果对抗网络生成的对抗样本对于目标检测器来说是难以识别和分类的,那么对抗网络可以得到较低的损失,而目标检测器可以得到较高的损失。
2.4. Joint training
2.4.联合训练
In this paper, we train the adversarial occlusion network and the standard Faster R-CNN detector jointly, and optimize the parameters of the two networks in each training iteration. During the period of forward propagation, for training the Faster R-CNN detector, the adversarial network is first used to generate the blocking mask on the feature map obtained after ROI pooling layer. This paper can obtain binary masks through sampling and use them to delete the values in the corresponding positions on the feature graph after the ROI-pooling layer. Then the modified features are trained forward and calculate the corresponding loss value, and finally conduct end-to-end training on the detector.在本文中,我们联合训练对抗性遮挡网络和标准Faster R-CNN检测器,并在每次训练迭代中优化两个网络的参数。在前向传播期间,为了训练Faster R-CNN检测器,对抗网络首先用于在ROI池化层之后获得的特征图上生成块掩码。本文通过采样得到二值掩码,利用二值掩码删除ROI池层后特征图上相应位置的值。然后对修改后的特征进行前向训练并计算相应的损失值,最后对检测器进行端到端训练。
3. Experiments
3.实验
The purpose of this experiment is to verify the effectiveness and superiority of the algorithm based on the combination of Faster R-CNN and adversarial network in underwater target detection. By applying this algorithm to underwater target detection, the work burden is reduced and the efficiency of underwater target detection is improved.实验旨在验证Faster R-CNN与对抗性网络相结合的算法在水下目标检测中的有效性和优越性。将该算法应用于水下目标检测中,减少了工作负担,提高了水下目标检测的效率。
3.1. Data set
3.1.数据集
This experiment tests the superiority of our algorithm through two data sets. One is the commonly used open source data set PASAL VOC2007, and the other is the underwater image data set collected by our lab. We collected nearly 8,000 underwater target images from the deep-sea fishing ground using the underwater robot in the laboratory, and the ratio of training set to testing set was 3:2. Targets in each image of the whole data set are labeled manually as shown in Fig. 4, where (a) refers to the tagging of sea cucumber targets, (b) refers to the tagging of sea urchin targets, (c) refers to the tagging of starfish targets, and (d) refers to the tagging of scallop targets. All sample images are processed and stored in the format of PASAL VOC2007 sample set, and then the training set is randomly divided into training set and verification set by using random function (the number ratio is 1:1). Our data set includes four kind seafood: echinus, holothurian, starfish and scallops.实验通过两组数据验证了该算法的优越性。一个是常用的开源数据集PASAL VOC 2007,另一个是我们实验室收集的水下图像数据集。我们在实验室使用水下机器人从深海渔场采集了近8,000幅水下目标图像,训练集与测试集的比例为3:2。如图4所示,对整个数据集的每个图像中的目标进行手动标记,其中(a)是指海参目标的标记,(b)是指海胆目标的标记,(c)是指海星目标的标记,以及(d)是指扇贝目标的标记。所有样本图像均以PASAL VOC 2007样本集的格式进行处理和存储,然后利用随机函数将训练集随机分为训练集和验证集(数量比为1:1)。我们的数据集包括四种海产品:海胆,海参,海星和扇贝。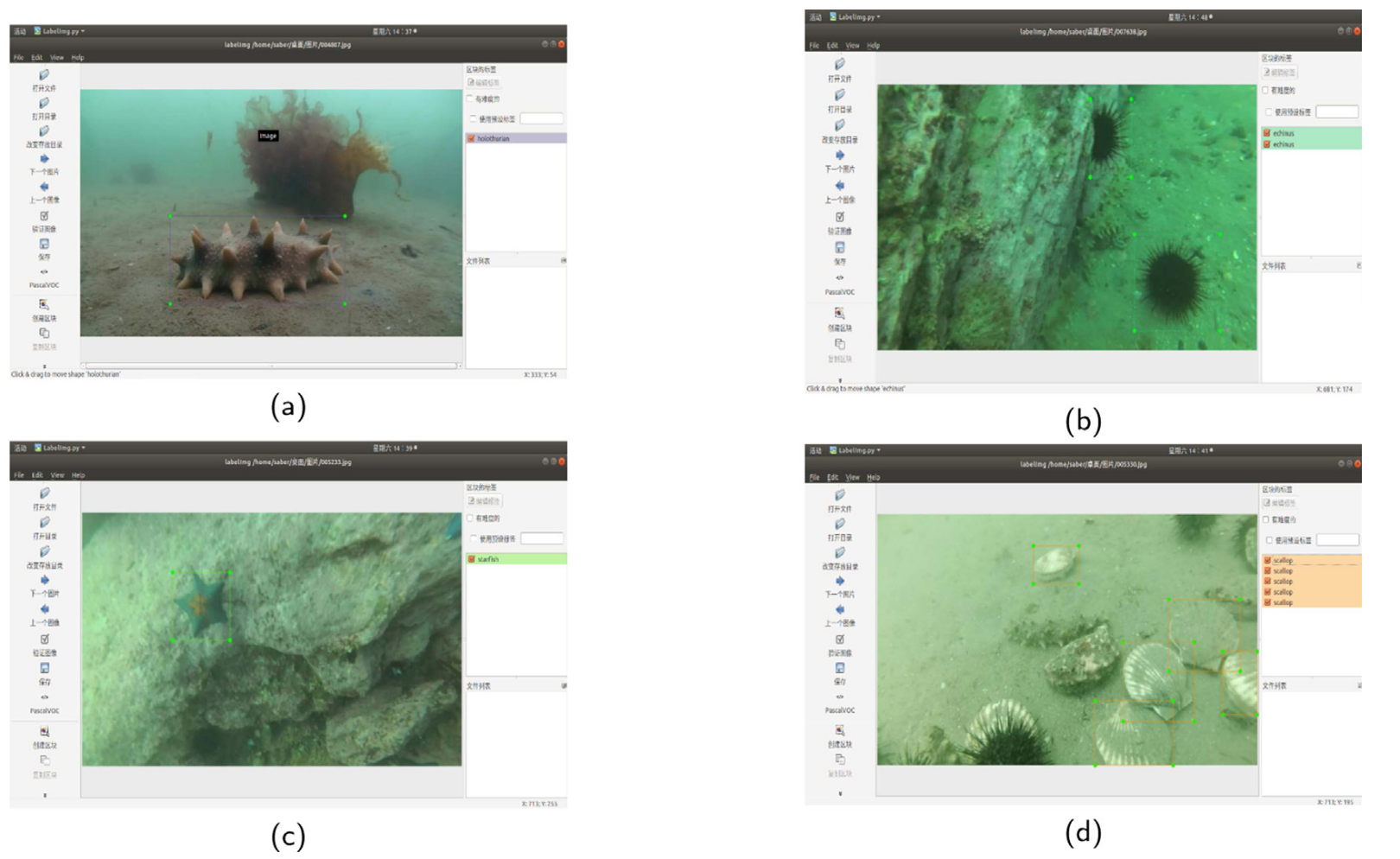
Fig. 4. Manual calibration of seafood.
见图4。手动校准海鲜。
3.2. Evaluation index
3.2.评价指标
In target detection, the mAP (mean Average Precision) is used to measure the detection accuracy, which refers to the average accuracy of multiple categories. AP refers to the average accuracy of a single category, which measures the recognition effect of the model on that category, while mAP measures the recognition effect of the model on all categories. In fact, mAP is the average value of all AP. The value of mAP is between 0–1, and the larger the value indicates the better the recognition accuracy of the model. In this experiment, mAP is used to judge the effect of model recognition.在目标检测中,mAP(mean Average Precision)用来衡量检测精度,它是指多个类别的平均精度。AP是指单个类别的平均准确率,衡量模型对该类别的识别效果,而mAP则衡量模型对所有类别的识别效果。mAP是所有AP的平均值。mAP的值在0-1之间,值越大表示模型的识别精度越好。在本实验中,使用mAP来判断模型识别的效果。
3.3. Experimental result
3.3.实验结果
The server operating system of this test is Ubuntu18.04, CUDA 10.0, CUDNN 7.0, OpenCV 2.4.0, while the hardware includes Intel Core I78700 CPU (3.2 GHz), the graphics card Nvidia GeForce RTX 2080 (8 GB memory), 32GB RAM. The deep learning framework Caffe (Jia et al., 2014) is built on the server, and the running environment of Faster R-CNN is configured. Then the calibrated sample data set is trained by Faster R-CNN and the adversarial network. The basic feature extraction network is based on VGG16 (Simonyan and Zisserman, 2014) network, and the model is trained by joint training. In the first 60k iterations, the learning rate was set to 0.001, in the 60k to 80k iterations, the learning rate was reduced to 0.0001, and stopped training after 80k iterations.本次测试的服务器操作系统为Ubuntu 18.04,CUDA 10.0,CUDNN 7.0,OpenCV 2.4.0,硬件包括Intel Core I78700 CPU(3.2 GHz),显卡Nvidia GeForce RTX 2080(8 GB内存),32 GB RAM。深度学习框架Caffe(Jia et al.,2014)构建在服务器上,配置Faster R-CNN的运行环境。然后用Faster R-CNN和对抗网络训练校准后的样本数据集。基本特征提取网络基于VGG 16(Simonyan和Zisserman,2014)网络,模型通过联合训练进行训练。在前60 k次迭代中,学习率设置为0.001,在60 k到80 k次迭代中,学习率降低到0.0001,并在80 k次迭代后停止训练。
The test results on the open source data set PASCAL VOC2007 and on underwater data set are shown in Tables 1 and 2. In order to show the efficiency of the detection result via the proposed method, two benchmark method is added to conduct contrast experiment. FRCN(ASDN) refers to A-Fast-RCNN (Wang et al., 2017) with our training environment, and Faster R-CNN refers the work (Ren et al., 2017).在开放源数据集PASCAL VOC 2007和水下数据集上的测试结果如表1和表2所示。为了验证该方法检测结果的有效性,增加了两种基准方法进行对比实验。FRCN(ASDN)是指A-Fast-RCNN(Wang等人,2017)与我们的训练环境,更快的R-CNN指的是工作(任等人,2017年)。
It can be seen from Table 1 that in the detection results of PASCAL VOC2007, the method proposed in this paper (72.5% mAP) is 2.6% higher than Faster R-CNN (69.9% mAP) and 1.7% higher than FRCN (ASDN) (70.8% mAP), indicating that the method proposed in this paper has a certain improvement in the detection effect. Table 2 shows that in the detection results of underwater data set, the method proposed in this paper (72.1% mAP) is 4.2% higher than Faster R-CNN (67.9% mAP) and 6.4% higher than FRCN (ASDN) (65.7% mAP). It can be seen from Table 2 that the mAP of the three methods has decreased in the detection results of the underwater data set. The reason is that the underwater light is uneven and environment is complex and diverse, which leads to the imaging effect not as good as that on land, and the number of images obtained under the water is limited, which affects the detection effect. It can be seen that image quality has the greatest impact on the detection of FRCN (ASDN). However, the influence on this method in this paper is not obvious, which fully reflects the superiority of the method in this paper.从表1可以看出,在PASCAL VOC 2007的检测结果中,本文提出的方法(72.5%mAP)比Faster R-CNN(69.9%mAP)高2.6%,比FRCN(ASDN)(70.8%mAP)高1.7%,说明本文提出的方法在检测效果上有一定的提升。表2显示,在水下数据集的检测结果中,本文提出的方法(72.1%mAP)比Faster R-CNN(67.9%mAP)高4.2%,比FRCN(ASDN)(65.7%mAP)高6.4%。从表2中可以看出,三种方法的mAP在水下数据集的检测结果中均有所下降。原因是水下光线不均匀,环境复杂多样,导致成像效果不如陆地,水下获取的图像数量有限,影响了探测效果。可以看出,图像质量对FRCN(ASDN)的检测影响最大。但对本文方法的影响并不明显,充分体现了本文方法的优越性。
As can be seen from Figs. 5 and 6, the method proposed in this paper performs very well in the detection of multi-category objects and singlecategory objects in the four scenarios of near distance and clear, near distance but blur, a distance and clear and a distance but blur. In all the above results, the detection threshold set in this paper is 0.8. Only when the target detection score exceeds or equals to 0.8, the detection accuracy and target box of the target can be displayed correctly in the detection result. However, if the detection score of the target is lower than 0.8, the category of the target and the detection box cannot display in the detection results. This is often referred to as missed detection. In our detection results, all objects and targets in the image are detected accurately and correctly, and there are few missed objects.从图5和6中可以看出,本文提出的方法在近距离清晰、近距离模糊、远距离清晰和远距离模糊四种情况下对多类目标和多类目标的检测都有很好的效果。在上述所有结果中,本文设定的检测阈值为0.8。只有当目标检测得分大于等于0.8时,检测结果中才能正确显示目标的检测精度和目标框。但是,如果目标的检测分数低于0.8,则目标的类别和检测框不能显示在检测结果中。这通常被称为错过检测。在我们的检测结果中,图像中的所有物体和目标都被准确正确地检测出来,几乎没有遗漏的物体。
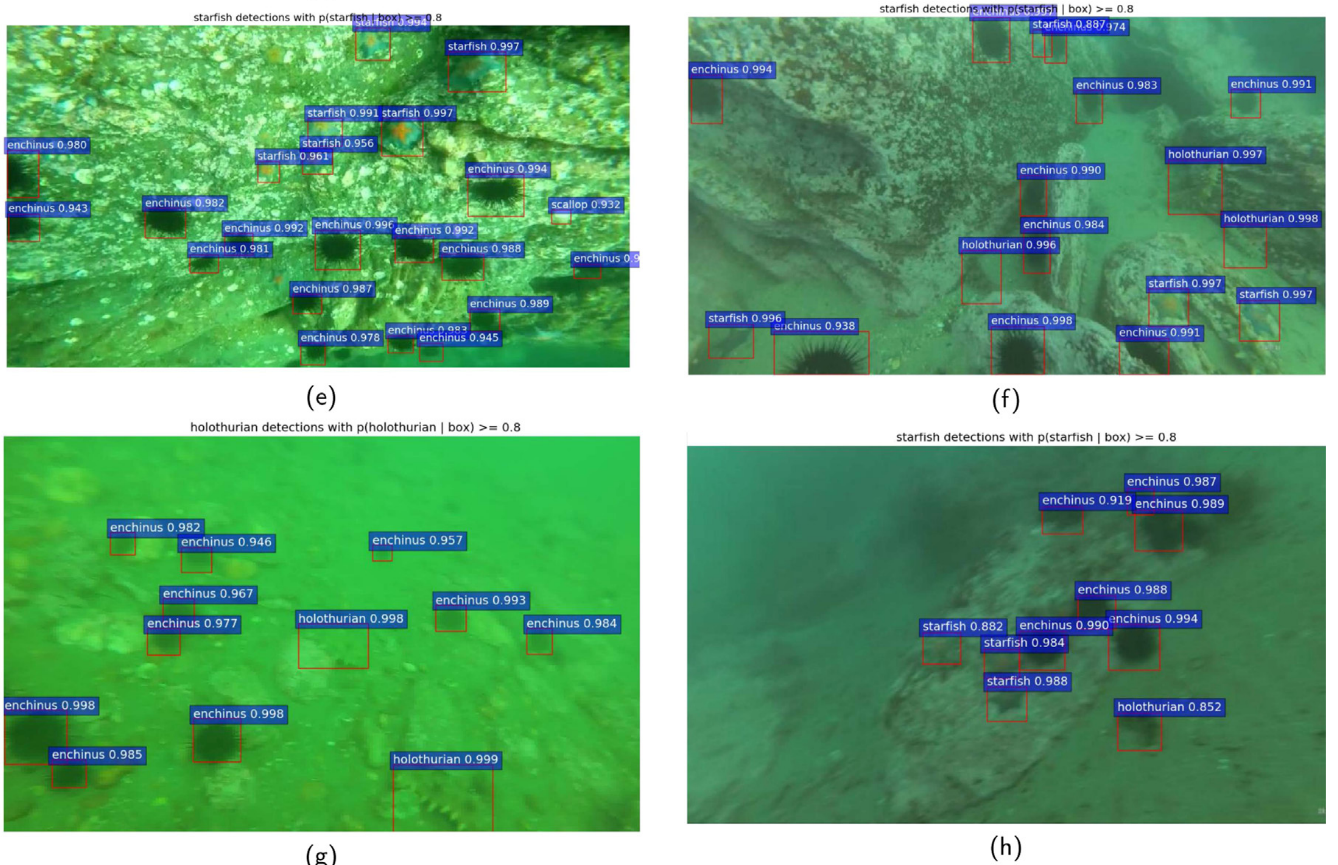
Fig. 5. The detection results of underwater multi class object. (a), (b) represents the situation of multiple targets at close range and clear. (c), (d) represents the situation of multiple targets at close but fuzzy. (e), (f) represents the situation of multiple targets at a distance and clear. (g) and (h) represents the situation of multiple targets at a distance but fuzzy.
图五 水下多类目标的检测结果。(a)、(B)表示近距离和清晰的多个目标的情况。(c)(d)表示多个目标接近但模糊的情况。(e),(f)表示多个目标在一定距离和清晰的情况。(g)以及(h)表示在一定距离处但模糊的多个目标的情况。


Fig. 6. The detection results of underwater single class object. (a), (b) represents the situation of single class target at close range and clear. (c), (d) represents the situation of single class target at close but fuzzy. (e), (f) represents the situation of single class target at a distance and clear. (g) and (h) represents the situation of single class target at a distance but fuzzy.
见图6 水下单类目标的检测结果。(a)、(B)表示近距离、清晰的单类目标情况。(c)(d)表示近距离但模糊的单类目标的情况。(e)、(f)表示单类目标在远距离且清晰的情况。(g)(h)表示单类目标在一定距离上的模糊情况。
In order to give an intuitive understanding of the detection result, two comparison study under different scenarios is conducted, as shown in Figs. 7 and 8. Fig. 7 is the detection result of single class target in a blurred scene. Fig. 8 is the detection result of multiple class in a blurred scene. (a) is the original picture, (b) is the detection result of FRCN network training for 40,000 times. (c) is the detection result of the model after 40,000 times of training using the Faster R-CNN network. (d) is the detection result of the model via the proposed Faster R-CNNAON network training for 40,000 times. From the simulation result, it is quite clear that our proposed method has a higher detection result in most of the scenarios. Some seafood cannot be detected with FRCN method while Faster R-CNN has a close performance but still worse than our proposed method.为了直观地了解检测结果,进行了两种不同场景下的对比研究,如图7和图8所示。图7为模糊场景下的单类目标检测结果。图8为模糊场景下的多类检测结果。(a)为原始图片,(b)为FRCN网络训练40000次后的检测结果。(c)为使用Faster R-CNN网络训练40000次后的模型检测结果。(d)是通过提出的Faster R-CNNAON网络训练40000次后的模型检测结果。从仿真结果可以看出,我们的方法在大多数场景下都有较高的检测结果。FRCN方法不能检测某些海鲜,而Faster R-CNN方法与FRCN方法有相近的性能,但仍低于所提出的方法。
Fig. 7. Detection result of single class target in a blurred scene.
图7 模糊场景中单类目标的检测结果。

Fig. 8. Detection result of multiple class target in a blurred scene.
图8 模糊场景中多类目标检测结果。
From the above simulation experiment, it can be concluded that the detection result with our proposed Faster-RCNN-AON method is superior to the compared two benchmark methods. It is more obvious for the underwater target detection since the underwater image is greatly influenced by light and turbidity, etc. Due to the character of AON network, it can generate images that is difficult for the network to detect which is quite applicable for the underwater case. Therefore, the detection rate with our method is still quite higher than other two methods without significant decrease compared with VOC 2007 set. Generally speaking, the method in this paper has a good detection effect in most of the underwater case.从上述仿真实验可以得出结论,我们提出的Faster-RCNN-AON方法的检测结果优于所比较的两种基准方法上级。由于水下图像受光照、浊度等因素的影响较大,这一点在水下目标检测中表现得更为明显。由于AON网络的特性,它可以生成网络难以检测的图像,非常适用于水下情况。因此,与VOC 2007集相比,我们的方法的检测率仍然比其他两种方法高得多,而没有显着下降。总的来说,本文的方法在大多数水下情况下都有较好的检测效果。
4. Conclusion
For underwater target detection, aiming at the problem of insufficient underwater image data, this paper presents an underwater target detection algorithm based on Faster R-CNN and adversarial network. The key idea is to learn an adversary in conjunction with original object detector. This adversary creates different examples of occlusion in training, such that these occlusions make it difficult for original object detector to classify correctly. Instead of generating samples in pixel space, our adversarial network modifies the features to simulate occlusion. Experiments show that the method is effective and superior in underwater target detection. Compared with some up-to-date well-known methods, this method has a significant improvement in underwater target detection. By joining the adversarial network on the standard Faster R-CNN detection network for joint training, we not only increases the number of training samples but also improves the detection capability of the detection network.在水下目标检测方面,针对水下图像数据不足的问题,提出了一种基于Faster R-CNN和对抗网络的水下目标检测算法。其关键思想是结合原始对象检测器来学习对手。这个对手在训练中创建了不同的遮挡示例,使得这些遮挡使得原始对象检测器难以正确分类。我们的对抗网络不是在像素空间中生成样本,而是修改特征来模拟遮挡。实验表明,该方法在水下目标检测中是有效的,具有上级的优越性。与目前一些著名的方法相比,该方法在水下目标检测方面有明显的改善。通过在标准Faster R-CNN检测网络上加入对抗网络进行联合训练,我们不仅增加了训练样本的数量,还提高了检测网络的检测能力。
GPT解读
这篇文章的核心内容是关于一种基于Faster R-CNN(区域卷积神经网络)和对抗性遮挡网络(Adversarial Occlusion Network, AON)的新型水下目标检测方法。文章的主要贡献和结构如下:
研究背景:
- 水下目标检测对于海洋探索具有重要意义,尤其在军事和民用领域。
- 水下环境复杂多变,可用样本图像有限,这给水下目标检测带来了挑战。
研究目的:
- 提出一种结合Faster R-CNN和AON的新型网络结构,称为Faster R-CNN-AON网络,以提高水下目标检测的鲁棒性。
方法介绍:
- Faster R-CNN:作为基础检测网络,使用VGG16作为特征提取器,通过Region Proposal Network (RPN) 提高检测速度。
- AON:对抗性遮挡网络,与Faster R-CNN检测网络竞争,学习如何遮挡给定目标,使其难以被正确分类。AON通过生成遮挡来增加训练样本的多样性,同时与检测网络共同学习,提高检测网络的鲁棒性。
实验结果:
- 在PASCAL VOC2007数据集上,与标准Faster R-CNN相比,mAP(平均精度均值)提高了2.6%。
- 在水下数据集上,mAP提高了4.2%。
实验方法:
- 使用两个数据集进行测试:PASCAL VOC2007和实验室收集的水下图像数据集。
- 使用mAP作为评估指标,衡量模型的检测准确性。
结论:
- 提出的Faster R-CNN-AON方法在水下目标检测中表现出色,尤其是在水下图像受光照和浑浊度影响较大的情况下。
- 通过联合训练对抗性网络,不仅增加了训练样本数量,还提高了检测网络的检测能力。
文章还详细介绍了Faster R-CNN的工作原理、AON的设计、损失函数的定义以及联合训练的步骤。此外,文章还讨论了实验设置、硬件环境、训练过程和结果分析。
1.前人的研究方法
在这篇文章中,提到了前人研究的方法包括基于传统方法和基于深度学习方法的水下目标检测算法。
- 基于传统方法的水下目标检测算法:传统方法主要依赖于手工设计的特征提取器和机器学习算法。这些方法通常使用针对水下图像特点设计的特征,如颜色、纹理、形状等,通过与事先定义的模型进行比较,识别和检测水下目标。常见的传统方法包括基于颜色统计的方法、基于纹理分析的方法、基于轮廓提取的方法等。然而,传统方法在处理水下图像的颜色失真、光照变化和水下散射等问题时效果不佳。
- 基于深度学习方法的水下目标检测算法:深度学习方法已经在很多计算机视觉任务中取得了显著的成果。在水下目标检测任务中,基于深度学习的方法也被广泛应用。这些方法主要基于卷积神经网络(CNN)和目标检测算法进行水下目标的检测。常见的基于深度学习的水下目标检测算法包括基于Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)等。这些方法通过在数据集上进行端到端的训练,可以自动学习图像中的特征和目标的位置信息,从而实现准确的水下目标检测。
在这篇文章中,作者采用了基于深度学习的水下目标检测方法,具体是基于Faster R-CNN算法。Faster R-CNN是一种常用的目标检测算法,它通过联合训练区域建议网络(RPN)和Fast R-CNN网络实现目标检测。RPN网络负责生成候选框的位置和得分,而Fast R-CNN网络负责对这些候选框进行分类和位置回归。为了增加训练样本的多样性并提高检测鲁棒性,作者还引入了对抗性遮挡网络(AON),用于生成遮挡蒙版,使得检测网络难以正确分类被遮挡的目标。通过联合训练Faster R-CNN和AON网络,最终实现了对水下目标的准确检测。
总而言之,前人研究的水下目标检测方法主要包括基于传统方法和基于深度学习方法。传统方法依赖于手工设计的特征和机器学习算法,而基于深度学习的方法则通过训练深度神经网络来实现自动学习特征和目标位置信息。在这篇文章中,作者提出了一种基于Faster R-CNN和AON网络的水下目标检测方法,通过引入对抗性网络来增加训练样本的多样性和提高检测的鲁棒性。
2.作者要解决的问题
本文旨在解决水下目标检测的问题。水下目标检测是海洋探索中的重要问题,对于军事和民用领域都具有重要的应用价值。然而,由于水下环境复杂多变,难以获取大量的样本图像,因此传统的水下目标检测方法存在一定的局限性。因此,本文提出了一种改进的目标检测算法,将对抗性网络引入标准的Faster R-CNN算法中,提高水下目标检测的准确性和鲁棒性。
具体而言,本文提出了一种名为Faster R-CNN-AON(Faster R-CNN和对抗性遮挡网络)的目标检测算法。该算法中的对抗性遮挡网络学习如何生成遮挡图像,使得检测器难以正确识别目标。Faster R-CNN检测器和对抗性遮挡网络通过联合训练,相互竞争和学习,从而提高检测网络在水下环境中的鲁棒性和检测能力。
通过联合训练Faster R-CNN和对抗性遮挡网络,可以有效防止检测网络对生成的固定特征过拟合。实验结果表明,在PASCAL VOC2007数据集和水下数据集上,相比于标准的Faster R-CNN网络,本文提出的方法在检测性能上有明显的提升。在VOC07数据集上,mAP提高了2.6%,在水下数据集上,mAP提高了4.2%。这表明本文所提出的Faster R-CNN-AON算法能够在水下目标检测中取得更好的效果,提高检测准确性,并具备对抗水下环境变化的能力。
因此,本文旨在解决水下目标检测中的挑战,提出了一种利用对抗性遮挡网络改进Faster R-CNN的方法,通过联合训练两个网络,提高水下目标检测的性能和鲁棒性。这对于海洋探索和应用领域具有重要的实际意义。
3.作者通过什么样的方法来解决所提出的研究问题
根据这篇文章,作者提出了一种基于Faster R-CNN和对抗性遮挡网络(AON)相结合的方法来解决水下目标检测的问题。
首先,作者使用Faster R-CNN作为基础目标检测算法。Faster R-CNN是一种常用的目标检测算法,它通过联合训练区域建议网络(RPN)和Fast R-CNN网络来实现目标检测。RPN网络用于生成候选框的位置和得分,而Fast R-CNN网络负责对这些候选框进行分类和位置回归。
为了增加训练样本的多样性,并提高检测鲁棒性,作者引入了对抗性遮挡网络(AON)。AON网络与Faster R-CNN检测网络存在竞争关系,它学习如何生成遮挡蒙版,即哪些特征图区域会被遮挡(即特征值被清零),从而使得检测网络难以正确分类被遮挡的目标。AON网络和Faster R-CNN网络进行联合训练,并共享卷积层和ROI池化层,同时使用各自独立的全连接层。
通过联合训练Faster R-CNN和AON网络,可以有效地防止检测网络过拟合生成的固定特征。实验结果表明,相较于标准的Faster R-CNN网络,在VOC07数据集上的mAP提高了2.6%,在水下数据集上的mAP提高了4.2%。这表明该方法能够提高水下目标检测网络的检测性能和鲁棒性。
综上所述,作者通过将对抗性遮挡网络引入Faster R-CNN目标检测算法中,实现了水下目标检测的改进。这一方法能够增加训练样本的多样性,并提高检测网络的鲁棒性,从而提升水下目标检测的准确性和性能。
4.作者通过哪些实验得出来了这些结果
根据这篇文章,作者通过一系列实验来验证他们所提出的方法在水下目标检测任务中的有效性。下面是他们进行的实验和得出的结果:
- 数据集和实验设置:作者使用了PASCAL VOC2007数据集和水下数据集进行实验。他们在Ubuntu 18.04操作系统、CUDA 10.0、CUDNN 7.0和OpenCV 2.4.0的环境下搭建了基于Caffe深度学习框架的运行环境。实验所使用的硬件配置包括Intel Core I7 8700 CPU、Nvidia GeForce RTX 2080显卡和32GB内存。
- 模型训练和评估:作者使用提出的Faster R-CNN-AON网络对校准样本数据集进行训练。他们将VGG16网络作为特征提取器,并通过联合训练Faster R-CNN和AON网络来提高检测效果。训练过程中,学习率在不同迭代阶段有不同的设定。训练完成后,作者使用训练好的模型在测试集上进行评估,并计算mAP(mean Average Precision)来衡量检测结果的准确性。
- 与基准方法的对比实验:为了证明所提出方法的优越性,作者进行了与两种基准方法的对比实验。一种基准方法是标准的Faster R-CNN网络,另一种是FRCN (ASDN)方法。通过与这两种方法的对比,作者证明了所提出方法在PASCAL VOC2007和水下数据集上的mAP值都有显著的提升。
- 检测结果分析:通过实验结果的图示,作者展示了所提出方法在不同情景下对多类别和单一类别对象的检测效果。同时,作者还对不同距离和清晰度的情况下的检测结果进行了分析。他们设置了一个检测阈值来控制检测结果的显示,当目标的检测分数大于等于阈值时,才显示目标的检测精度和边界框。
通过这些实验,作者验证了所提出的Faster R-CNN-AON方法在水下目标检测任务中的有效性,并与其他基准方法进行了对比分析,从而得出了实验结果。这些结果表明,所提出的方法在PASCAL VOC2007和水下数据集上的检测效果明显优于传统的Faster R-CNN方法和FRCN (ASDN)方法。
5.实验部分的不足
根据这篇文章,实验部分存在以下一些不足之处:
- 数据集选择较为有限:作者在实验中仅使用了PASCAL VOC2007数据集和水下数据集进行验证。这两个数据集可能无法完全覆盖水下目标检测任务中的各种场景和情况,因此可能存在一定的偏差。为了更全面地评估所提出的方法的有效性,可以考虑使用更多样化、更具代表性的水下数据集进行实验。
- 实验环境和硬件配置:虽然作者提到了实验所使用的操作系统、深度学习框架和硬件配置等信息,但并未对其选择进行详细的解释和说明。例如,为何选择了特定的硬件配置和软件环境,是否有其他选择可行等。更详细的实验环境说明可以提供更多的信息,以便他人能够重现实验并对结果进行进一步验证。
- 与更多基准方法的对比:作者在实验中仅与标准的Faster R-CNN网络和FRCN (ASDN)方法进行了对比。虽然这两种方法是相关的和常用的基准方法,但与更多的相关工作进行对比可能更有说服力。对比更多的基准方法可以更全面地评估所提出方法的优劣,并更好地揭示其相对优势。
综合来看,虽然实验部分展示了所提出方法在水下目标检测任务中的有效性,但仍有一些不足之处需要改进和完善。解决这些不足之处可以进一步增强实验的可靠性和说服力。
6.作者使用该方法的优点
根据这篇文章,使用作者提出的方法在水下目标检测任务中具有以下优点:
- 提高目标检测鲁棒性:通过引入对抗性遮挡网络(AON),该方法可以学习生成遮挡蒙版来遮挡目标的部分特征,从而使得检测网络对被遮挡的目标难以正确分类。这样的对抗学习机制能够提高目标检测网络对复杂和变化的水下环境的适应性,提高了检测的鲁棒性。
- 扩展训练样本:AON网络可以生成具有不同遮挡程度的样本,从而增加了训练样本的多样性。通过与Faster R-CNN联合训练,使得检测网络能够学习到更多不同情况下的目标特征,提高了模型的泛化能力。
- 防止过拟合:联合训练Faster R-CNN和AON网络可以有效地防止检测网络过拟合生成的固定特征。AON网络与Faster R-CNN网络在训练过程中相互竞争学习,通过动态生成遮挡蒙版,减少了模型对固定特征的依赖,提高了模型的泛化能力。
- 提高检测性能:实验结果显示,与标准的Faster R-CNN网络相比,该方法在PASCAL VOC2007数据集上的mAP提高了2.6%,在水下数据集上的mAP提高了4.2%。这表明该方法能够显著提高水下目标检测的准确性和性能。
综上所述,该方法通过引入对抗性遮挡网络,扩展了训练样本并提高了模型的鲁棒性和泛化能力,从而在水下目标检测任务中表现出优秀的性能。
7.作者使用该方法的缺点
根据这篇文章,该方法存在以下一些缺点:
- 目标遮挡生成的挑战:尽管作者提出的对抗性遮挡网络(AON)能够学习生成遮挡的蒙版,但是在实际情况下,目标的遮挡可能由于光照变化、水下散射等因素而变得复杂和不确定。因此,生成的遮挡蒙版可能存在不准确或者不理想的情况,这会对目标的检测结果产生一定的影响。
- 训练复杂度增加:引入对抗性网络 (AON) 后,模型的训练复杂度会增加。联合训练 Faster R-CNN 和 AON 网络要求增加额外的计算资源和时间,这对于一些资源有限的环境可能带来一定的挑战。
- 数据集限制:作者在实验中使用了有限的数据集进行验证,如 PASCAL VOC2007 数据集和水下数据集。这些数据集可能无法完全覆盖所有的水下场景和目标类型,因此对于该方法的鲁棒性和泛化性能在更广泛的数据集上的表现还需要进一步研究。
- 参数调优的困难:在训练过程中,联合训练 Faster R-CNN 和 AON 网络需要调优的参数较多,调整好各个参数的取值是一项具有挑战性的任务。可能需要更多的实验和调优才能获得最佳的模型性能。
综上所述,尽管该方法在水下目标检测中具有一定的优点,但也面临着一些挑战和限制,需要进一步的研究和改进。
8.论文的创新点主要体现在以下几个方面
根据这篇文章,论文的创新点主要体现在以下几个方面:
- 提出了将对抗性遮挡网络(AON)引入Faster R-CNN目标检测算法的方法。在传统的目标检测算法中,往往只通过增加训练样本数量来提高模型的鲁棒性,而AON网络通过与Faster R-CNN网络的竞争学习,可以生成遮挡蒙版,增加样本的多样性,并提高模型对遮挡目标的检测能力。
- 通过联合训练Faster R-CNN和AON网络,提高了模型的泛化能力。传统的目标检测算法往往在具体场景下表现较好,但在其他场景下泛化能力较弱。而通过联合训练,模型可以学习到更多不同情况下的目标特征,提高了模型的泛化能力和鲁棒性。
- 实验证明了所提方法在水下目标检测任务中的有效性。通过与基准方法的对比实验证明了所提出的方法相对于传统方法和单独使用Faster R-CNN而言,在水下目标检测任务中具有更好的性能和鲁棒性,取得了较好的检测结果。
综上所述,该论文的创新点主要在于引入对抗性遮挡网络,并通过联合训练提高模型的泛化能力和鲁棒性,以及在水下目标检测任务中取得了较好的实验结果。