Underwater target detection based on improved YOLOv7
基于改进YOLOv7的水下目标检测
Abstract
Underwater target detection is a crucial aspect of ocean exploration. However, conventional underwater target detection methods face several challenges such as inaccurate feature extraction, slow detection speed and lack of robustness in complex underwater environments. To address these limitations, this study proposes an improved YOLOv7 network (YOLOv7-AC) for underwater target detection. The proposed network utilizes an ACmixBlock module to replace the 3x3 convolution block in the E-ELAN structure, and incorporates jump connections and 1x1 convolution architecture between ACmixBlock modules to improve feature extraction and network reasoning speed. Additionally, a ResNet-ACmix module is designed to avoid feature information loss and reduce computation, while a Global Attention Mechanism (GAM) is inserted in the backbone and head parts of the model to improve feature extraction. Furthermore, the K-means++ algorithm is used instead of K-means to obtain anchor boxes and enhance model accuracy. Experimental results show that the improved YOLOv7 network outperforms the original YOLOv7 model and other popular underwater target detection methods. The proposed network achieved a mean average precision (mAP) value of 89.6% and 97.4% on the URPC dataset and Brackish dataset, respectively, and demonstrated a higher frame per second (FPS) compared to the original YOLOv7 model.水下目标检测是海洋探测的一个重要方面。然而,在复杂的水下环境下,传统的水下目标检测方法面临特征提取不准确、检测速度慢、鲁棒性不足等挑战。针对这些局限性,提出了一种改进的YOLOv7网络(YOLOv7- ac)用于水下目标检测。该网络利用ACmixBlock模块替代E-ELAN结构中的3x3卷积块,并在ACmixBlock模块之间融入跳跃连接和1x1卷积架构,以提高特征提取和网络推理速度。此外,设计了ResNet-ACmix模块以避免特征信息损失并减少计算量,同时在模型的主干和头部部分插入了全局注意力机制(GAM)以改进特征提取。使用k -means++算法代替K-means算法获取锚框,提高模型精度。实验结果表明,改进的YOLOv7网络优于原始的YOLOv7模型和其他流行的水下目标检测方法。所提网络在URPC数据集和Brackish数据集上分别取得了89.6%和97.4%的平均精度均值(mAP)值,并且相比原始YOLOv7模型表现出更高的每秒帧数(FPS)。
The source code for this study is publicly available at https://github.com/NZWANG/YOLOV7-AC.
In conclusion, the improved YOLOv7 network proposed in this study represents a promising solution for underwater target detection and holds great potential for practical applications in various underwater tasks.综上所述,本文提出的改进YOLOv7网络为水下目标检测提供了一种很好的解决方案,在水下各种任务的实际应用中具有很大的潜力。
Keywords
Underwater target detection; Marine resources; Computer vision; Image analysis; YOLOv7-AC; GAM; K-means++水下目标检测;海洋资源;计算机视觉;图像分析;YOLOv7-AC;GAM;k - means + +
Introduction
The oceans occupy a significant portion of the Earth’s surface and are a valuable source of oil, gas, minerals, chemicals, and other aquatic resources, attracting the attention of professionals, adventurers, and researchers, leading to an increase in marine exploration activities [1]. To support these exploration efforts, various underwater tasks such as target location, biometric identification, archaeology, object search, environmental monitoring, and equipment maintenance must be performed [2]. In this context, underwater target detection technology plays a crucial role. Underwater target detection can be categorized into acoustic system detection and optical system detection [3], and image analysis, including classification, identification, and detection, can be performed based on the obtained image information. Optical images, compared to acoustic images, offer higher resolution and a greater volume of information and are more cost-effective in terms of acquisition methods [4, 5]. As a result, underwater target detection based on optical systems is receiving increased attention.Target detection, being as a core branch of computer vision, encompasses fundamental tasks such as target classification and localization. The existing approaches to target detection can be broadly classified into two categories: traditional target detection methods and deep learning-based target detection methods [6].海洋占据了地球表面的重要部分,是石油、天然气、矿物、化学品和其他水生资源的宝贵来源,吸引了专业人士、探险家和研究人员的注意,导致海洋勘探活动的增加。为了支持这些探索工作,必须执行各种水下任务,如目标定位、生物特征识别、考古、物体搜索、环境监测和设备维护。在此背景下,水下目标检测技术起着至关重要的作用。水下目标探测分为声学系统探测和光学系统探测[3],可以根据获得的图像信息进行图像分析,包括分类、识别和探测。与声学图像相比,光学图像具有更高的分辨率和更大的信息量,在获取方法方面更具成本效益[4,5]。因此,基于光学系统的水下目标检测受到越来越多的关注。目标检测作为计算机视觉的核心分支,包含目标分类、定位等基本任务。现有的目标检测方法大致可以分为两类:传统的目标检测方法和基于深度学习的目标检测方法[6]。
Traditional algorithms for target detection are typically structured into three phases: region selection, feature extraction, and feature classification [7]. The goal of region selection is to localize the target, as the position and aspect ratio of the target may vary in the image. This phase is typically performed by traversing the entire image using a sliding window strategy [8], wherein different scales and aspect ratios are considered. Subsequently, feature extraction algorithms such as Histogram of Oriented Gradients (HOG) [9] and Scale Invariant Feature Transform (SIFT) [10] are employed to extract relevant features. Finally, the extracted features are classified using classifiers such as Support Vector Machines (SVM) [11] and Adaptive Boosting (Ada-Boost) [12]. However, the traditional target detection method has two major limitations: (1) the region selection using sliding windows lacks specificity and leads to high time complexity and redundant windows, and (2) the hand-designed features are not robust to variations in pose.传统的目标检测算法通常分为3个阶段:区域选择、特征提取和特征分类。由于目标在图像中的位置和长宽比可能会发生变化,因此区域选择的目的是定位目标。这一阶段通常通过使用滑动窗口策略[8]遍历整个图像来执行,其中考虑了不同的尺度和长宽比。然后,采用方向梯度直方图(HOG)[9]和尺度不变特征变换(SIFT)[10]等特征提取算法提取相关特征;最后,利用支持向量机(SVM)[11]和自适应增强(Ada-Boost)[12]等分类器对提取的特征进行分类。然而,传统的目标检测方法存在两个主要的局限性:(1)使用滑动窗口的区域选择缺乏特异性,导致时间复杂度高和窗口冗余;(2)手工设计的特征对姿态变化的鲁棒性不强。
The advent of deep learning has revolutionized the field of target detection and has been extensively applied in computer vision. Convolutional neural networks (CNNs) have demonstrated their superior ability to extract and model features for target detection tasks, and numerous studies have demonstrated that deep learning-based methods outperform traditional methods relying on hand-designed features [13]. Currently, there are two main categories of deep learning-based target detection algorithms: region proposal-based algorithms and regression-based algorithms. The former category, also referred to as Two-Stage target detection methods, are based on the principle of coarse localization and fine classification, where candidate regions containing targets are first identified and then classified. Representative algorithms in this category include R-FCN (Region-based Fully Convolutional Networks) [15] and the R-CNN (Region-CNN) family of algorithms (R-CNN [16], Fast-RCNN [17], Faster-RCNN [18], Mask-RCNN [19], Cascade-RCNN [20], etc.). Although region-based algorithms have high accuracy, they tend to be slower and may not be suitable for real-time applications. In contrast, regression-based target detection algorithms, also known as One-Stage target detection algorithms, directly extract features through CNNs for the prediction of target classification and localization. Representative algorithms in this category include the SSD (Single Shot MultiBox Detector) [21] and the YOLO (You Only Look Once) family of algorithms (YOLO [23], YOLO9000 [24], YOLOv3 [25], YOLOv4 [26], YOLOv5 [27], YOLOv6 [28], YOLOv7 [29]). Due to the direct prediction of classification and localization, these algorithms offer a faster detection speed, making them a popular research area in the field of target detection, with ongoing efforts aimed at improving their accuracy and performance.深度学习的出现彻底改变了目标检测领域,并被广泛应用于计算机视觉。卷积神经网络(cnn)已经证明了其在目标检测任务中提取和建模特征的卓越能力,大量研究表明,基于深度学习的方法优于依赖手工设计特征[13]的传统方法。目前,基于深度学习的目标检测算法主要有两大类:基于区域提议的算法和基于回归的算法。前一类也称为两阶段目标检测方法,基于粗定位和细分类的原则,首先识别出包含目标的候选区域,然后再进行分类。该类别中的代表性算法包括R-FCN(基于区域的全卷积网络)[15]和R-CNN(区域- cnn)系列算法(R-CNN[16]、Fast-RCNN[17]、Faster-RCNN[18]、Mask-RCNN[19]、Cascade-RCNN[20]等)。基于区域的算法虽然精度高,但速度较慢,不适合实时应用。相比之下,基于回归的目标检测算法,也称为单阶段目标检测算法,直接通过cnn提取特征用于目标分类和定位的预测。这一类中的代表性算法包括SSD (Single Shot MultiBox Detector)[21]和YOLO (You Only Look Once)系列算法(YOLO[23]、YOLO9000[24]、YOLOv3[25]、YOLOv4[26]、YOLOv5[27]、YOLOv6[28]、YOLOv7[29])。由于直接预测分类和定位,这些算法具有更快的检测速度,成为目标检测领域的研究热点,人们一直在努力提高它们的精度和性能。
The commercial viability of underwater robots equipped with highly efficient and accurate target detection algorithms is being actively pursued in the field of underwater environments [30]. In this regard, researchers have made significant contributions to the development of target detection algorithms. For instance, in 2017, Zhou et al. [31] integrated image enhancement techniques into an expanded VGG16 feature extraction network and employed a Faster R-CNN network with feature mapping for the detection and identification of underwater biological targets using the URPC dataset. In 2020, Chen et al. [32] introduced a new sample distribution-based weighted loss function called IMA (Invert Multi-Class AdaBoost) to mitigate the adverse effect of noise on detection performance. In 2021, Qiao et al. [33] proposed a real-time and accurate underwater target classifier, leveraging the combination of LWAP (Local Wavelet Acoustic Pattern) and MLP (Multilayer Perceptron) neural networks, to tackle the challenging problem of underwater target classification. Nevertheless, the joint requirement of localization and classification, in addition to classification, makes the target detection task especially challenging in underwater environments where images are often plagued by severe color distortion and low visibility caused by mobile acquisition.With the aim of enhancing the accuracy, achieving real-time performance, and promoting the portability of the underwater target detection capability, the most advanced YOLOv7 model of the YOLO series has been selected for improvement, resulting in the proposed YOLOv7-AC model, designed to address the difficulties encountered in this field. The effectiveness of the proposed model has been demonstrated through experiments conducted on underwater images.The innovations of this paper are as follows:在水下环境[30]领域,配备高效、准确目标检测算法的水下机器人的商业可行性正在积极追求。为此,研究人员为目标检测算法的发展做出了重大贡献。例如,2017年,Zhou等[31]将图像增强技术集成到扩展的VGG16特征提取网络中,并利用具有特征映射的Faster R-CNN网络对URPC数据集进行水下生物目标的检测和识别。2020年,Chen等人在[32]中引入了一种新的基于样本分布的加权损失函数IMA (inverse Multi-Class AdaBoost)来缓解噪声对检测性能的不利影响。2021年,Qiao et al.[33]提出了一种实时准确的水下目标分类器,利用LWAP (Local Wavelet Acoustic Pattern)和MLP (Multilayer Perceptron)神经网络的结合来解决水下目标分类的挑战性问题。然而,除了分类之外,还需要定位和分类,这使得水下环境下的目标检测任务尤其具有挑战性。在水下环境中,由于移动采集,图像往往存在严重的颜色失真和低能见度。为了提高水下目标检测的准确性、实时性和便携性,选取YOLO系列中最先进的YOLOv7模型进行改进,提出了YOLOv7- ac模型,以解决该领域遇到的困难。通过在水下图像上的实验验证了所提模型的有效性。本文的创新点如下:
(1) In order to extract more informative features, the integration of the Global Attention Mechanism (GAM) [39] is proposed. This mechanism effectively captures both the channel and spatial aspects of the features and increases the significance of cross-dimensional interactions.
(1)为了提取信息量更大的特征,提出了融合全局注意力机制(GAM)的[39]。这种机制有效地捕获了特征的通道和空间方面,并增加了跨维度交互的重要性。
(2) To further enhance the performance of the network, the ACmix (A mixed model incorporating the benefits of self-Attention and Convolution) [40] is introduced.
(2)为了进一步提升网络的性能,引入了ACmix (A mixed model combination of self-Attention and Convolution)[40]模型。
(3) The design of the ResNet-ACmix module in YOLOv7-AC aims to enhance the feature extraction capability of the backbone network and to accelerate the convergence of the network by capturing more informative features.
(3) YOLOv7-AC中ResNet-ACmix模块的设计旨在增强骨干网的特征提取能力,并通过捕获更有信息量的特征来加速网络的收敛。
(4) The E-ELAN module in the YOLOv7 network is optimized by incorporating Skip Connections and a 1x1 convolutional structure between modules and replacing the 3x3 Convolutional layer with the ACmixBlock. This results in an enhanced feature extraction ability and improved speed during inference.
(4)对YOLOv7网络中的E-ELAN模块进行优化,在模块之间加入跳跃连接和1x1卷积结构,并将3x3卷积层替换为ACmixBlock。这增强了特征提取能力,提高了推理速度。
The rest of this paper is organized as follows. Section 2 describes the architecture of YOLOv7 model and related methods. Section 3 presents the proposed YOLOv7-AC model and its theoretical foundations. The performance of the YOLOv7-AC model is evaluated and analyzed through experiments conducted on underwater image datasets in Section 4. The limitations and drawbacks of the proposed method are discussed in Section 5. Finally, we provide a conclusion of this work in Section 6.本文的其余部分组织如下。第2节介绍YOLOv7模型的体系结构和相关方法。第3节介绍了YOLOv7-AC模型及其理论基础。第四节通过在水下图像数据集上进行实验,评估和分析了YOLOv7-AC模型的性能。第5节讨论了所提出方法的局限性和缺点。最后,在第6节对本文工作进行了总结。
2. Related Works
2.1. YOLOv7
The YOLOv7 model, developed by Chien-Yao Wang and Alexey Bochkovskiy et al. in 2022, integrates strategies such as E-ELAN (Extended efficient layer aggregation networks) [34], model scaling for concatenation-based models [35], and model re-parameterization [36] to achieve a favorable balance between detection efficiency and precision. As shown in Figure 1, the YOLOv7 network consists of distinct four modules: the Input module, the Backbone network, the Head network and the Prediction network.由Chien-Yao Wang和Alexey Bochkovskiy等人在2022年开发的YOLOv7模型集成了E-ELAN (Extended efficient layer aggregation networks)[34]、基于级联的模型扩展[35]和模型重新参数化[36]等策略,以实现检测效率和精度之间的良好平衡。如图1所示,YOLOv7网络由四个不同的模块组成:输入模块、主干网络、头部网络和预测网络。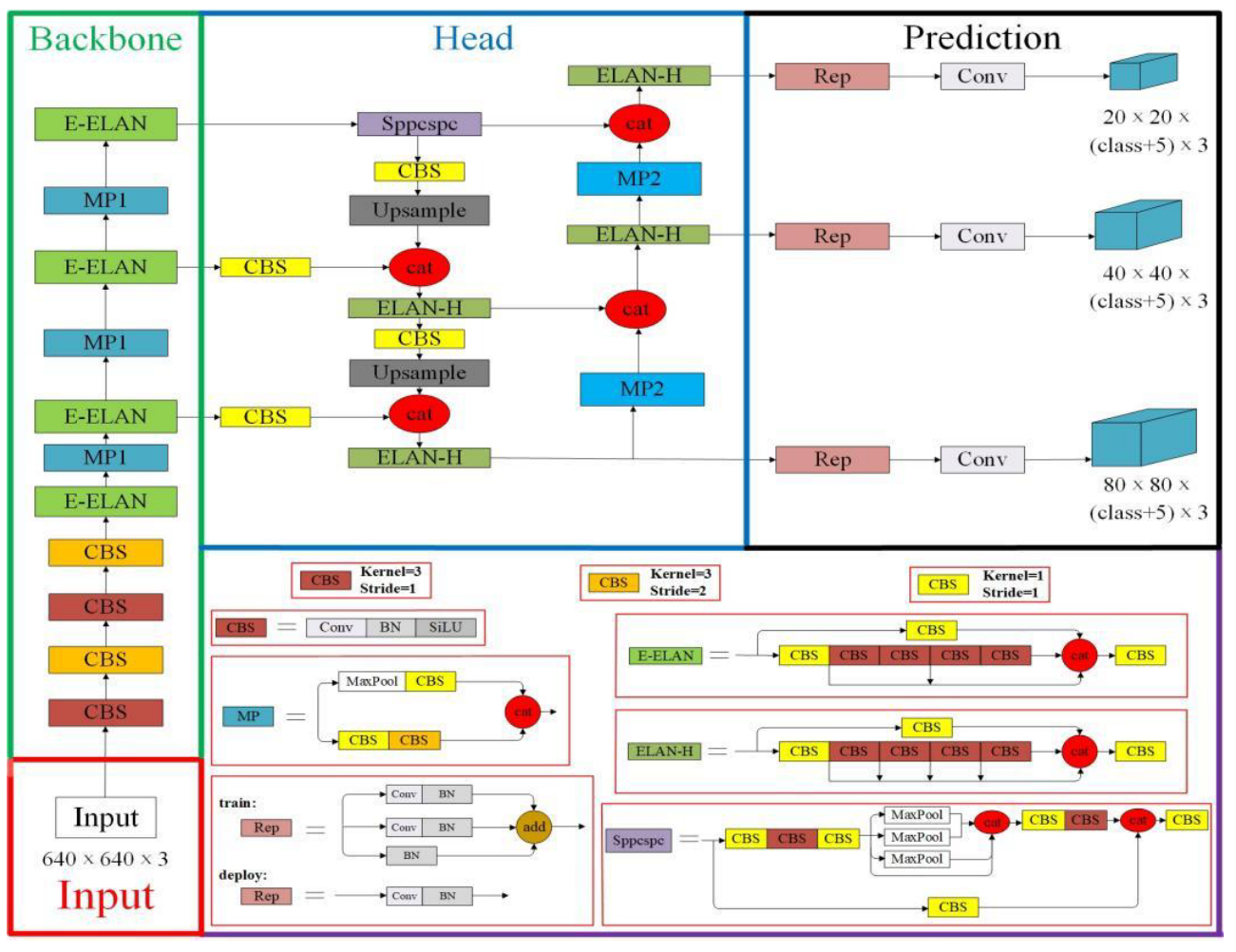
Figure 1. The network structure of YOLOv7 [29].
图1.YOLOv7的网络结构[29]。
Input module: The pre-processing stage of the YOLOv7 model employs both mosaic and hybrid data enhancement techniques and leverages the adaptive anchor frame calculation method established by YOLOv5 to ensure that the input color images are uniformly scaled to a 640x640 size, thereby meeting the requirements for the input size of the backbone network.输入模块:YOLOv7模型的预处理阶段采用了马赛克和混合数据增强技术,并利用YOLOv5建立的自适应锚帧计算方法,以确保输入的彩色图像均匀缩放到640 x640大小,从而满足骨干网络对输入大小的要求。
Backbone network: The YOLOv7 network comprises three main components: CBS, E-ELAN, and MP1. The CBS module is composed of convolution, batch normalization, and SiLU activation functions. The E-ELAN module maintains the original ELAN design architecture and enhances the network’s learning ability by guiding different feature group computational blocks to learn more diverse features, preserving the original gradient path. MP1 is composed of CBS and MaxPool and is divided into upper and lower branches. The upper branch uses MaxPool to halve the image’s length and width and CBS with 128 output channels to halve the image channels. The lower branch halves the image channels through a CBS with a 1x1 kernel and stride, halves the image length and width with a CBS of 3x3 kernel and 2x2 stride, and finally fuses the features extracted from both branches through the concatenation (Cat) operation. MaxPool extracts the maximum value information of small local areas while CBS extracts all value information of small local areas, thereby improving the network’s feature extraction ability.骨干网络:YOLOv7网络由三个主要组件组成:CBS、E-ELAN和MP1。CBS模块由convolution、batch normalization和SiLU激活函数组成。E-ELAN模块保持了原有ELAN设计架构,通过引导不同特征组计算块学习更多样化的特征,增强了网络的学习能力,保留了原有的梯度路径。MP1由CBS和MaxPool组成,分为上分支和下分支。上面的分支使用MaxPool将图像的长度和宽度减半,使用具有128个输出通道的CBS将图像通道减半。下分支通过具有1x1核和步幅的CBS将图像通道减半,使用具有3x3核和2x2步幅的CBS将图像长宽减半,最后通过concatenation (Cat)操作将从两个分支提取的特征进行融合。MaxPool提取局部小区域的最大值信息,CBS提取局部小区域的所有值信息,从而提高网络的特征提取能力。
Head network: The Head network of YOLOv7 is structured using the Feature Pyramid Network (FPN) architecture, which employs the PANet design. This network comprises several Convolutional, Batch Normalization and SiLU activation (CBS) blocks, along with the introduction of a Spatial Pyramid Pooling and Convolutional Spatial Pyramid Pooling (Sppcspc) structure, the extended efficient layer aggregation network (E-ELAN), and MaxPool-2 (MP2). The Sppcspc structure improves the network’s perceptual field through the incorporation of a Convolutional Spatial Pyramid (CSP) structure within the Spatial Pyramid Pooling (SPP) structure, along with a large residual edge to aid optimization and feature extraction. The ELAN-H layer, which is a fusion of several feature layers based on E-ELAN, further enhances feature extraction. The MP2 block has a similar structure to the MP1 block, with a slight modification to the number of output channels.头网络:YOLOv7的头网络采用特征金字塔网络(Feature Pyramid network, FPN)架构构建,采用PANet设计。该网络由多个卷积、批量归一化和SiLU激活(CBS)块组成,同时引入了空间金字塔池化和卷积空间金字塔池化(Sppcspc)结构、扩展的高效层聚合网络(E-ELAN)和MaxPool-2 (MP2)。Sppcspc结构通过在空间金字塔池化(SPP)结构中融入卷积空间金字塔(CSP)结构来改善网络的感知场,并使用较大的残差边缘来辅助优化和特征提取。在E-ELAN的基础上融合多个特征层,进一步增强特征提取能力。MP2块与MP1块具有相似的结构,对输出通道的数量略有修改。
Prediction network: The Prediction network of YOLOv7 employs a Rep structure to adjust the number of image channels for the features output from the head network, followed by the application of 1x1 convolution for the prediction of confidence, category, and anchor frame. The Rep structure, inspired by RepVGG [37], introduces a special residual design to aid in the training process. This unique residual structure can be reduced to a simple convolution in practical predictions, resulting in a decrease in network complexity without sacrificing its predictive performance.预测网络:YOLOv7的预测网络采用Rep结构来调整头部网络输出特征的图像通道数量,然后应用1x1卷积来预测置信度、类别和锚帧。Rep结构受到RepVGG [37]的启发,引入了一种特殊的残差设计来帮助训练过程。这种独特的残差结构可以在实际预测中简化为简单的卷积,从而在不牺牲其预测性能的情况下降低网络复杂度。
2.2. GAM
The attention mechanism is a method used to improve the feature extraction in complex contexts by assigning different weights to the various parts of the input in the neural network. This approach enables the model to focus on the relevant information and ignore the irrelevant information, resulting in improved performance. Examples of attention mechanisms include pixel attention, channel attention, and multi-order attention [38].注意力机制是一种通过为神经网络中输入的各个部分分配不同权重来改善复杂背景下的特征提取的方法。这种方法使模型能够专注于相关信息,忽略不相关的信息,从而提高性能。注意力机制的例子包括像素注意力、通道注意力和多阶注意力[38]。
GAM [39] could improve the performance of deep neural networks by reducing information dispersion and amplifying the global interaction representation. The module structure is shown in Figure 2.GAM [39]可以通过减少信息分散和放大全局交互表示来提高深度神经网络的性能。模块结构如图2所示。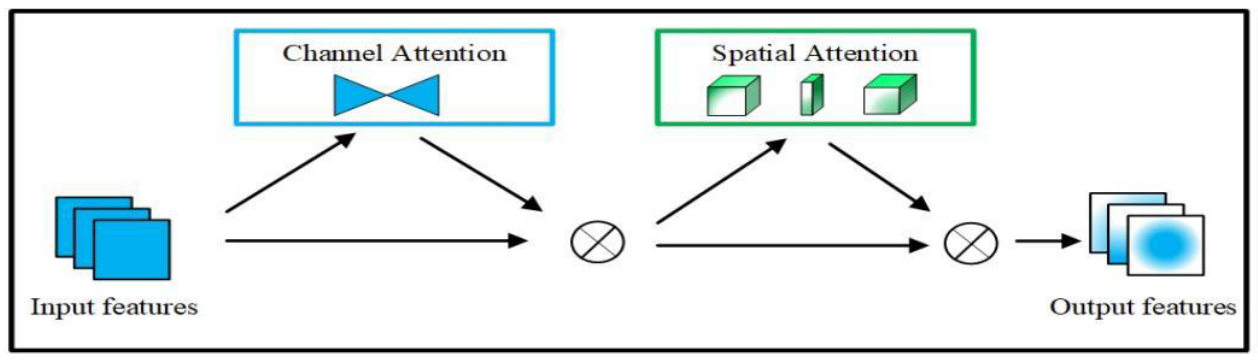
Figure 2. The structure diagram of GAMmodule [39].
图2 GAM模块的结构图[39]。
The GAM encompasses a channel attention submodule and a spatial attention submodule. The channel attention submodule is designed as a three-dimensional transformation, allowing it to preserve the three-dimensional information of the input. This is followed by a multi-layer perception (MLP) with two layers, which serves to amplify the inter-dimensional dependence in the channel space, thus enabling the network to focus on the more meaningful and foreground regions of the image, as depicted in Figure 3.GAM包括通道注意力子模块和空间注意力子模块。通道注意子模块被设计为三维变换,允许其保留输入的三维信息。随后是具有两层的多层感知(MLP),其用于放大通道空间中的维度间依赖性,从而使网络能够专注于图像的更有意义和前景区域,如图3所示。
Figure 3. The structure diagram of channel attention submodule in GAMmodule [39].
图3.GAM模块中通道注意子模块的结构图[39]。
The spatial attention submodule incorporates two convolutional layers to effectively integrate spatial information, enabling the network to concentrate on contextually significant regions across the image, as depicted in Figure 4.空间注意力子模块包含两个卷积层,以有效地整合空间信息,使网络能够专注于图像中的上下文重要区域,如图4所示。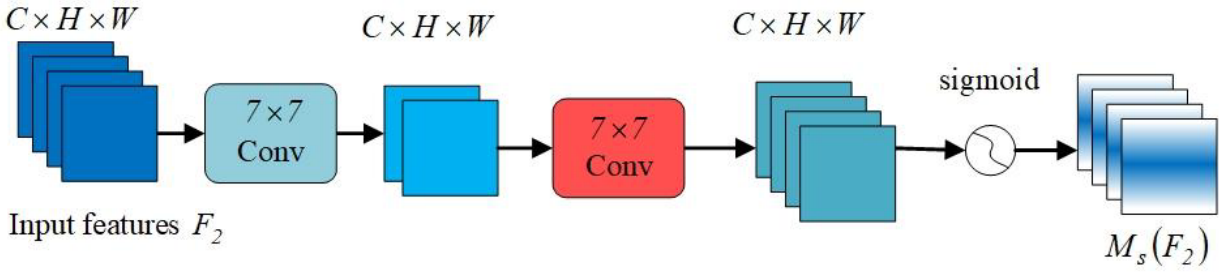
Figure 4. The structure diagram of spatial attention submodule in GAMmodule [39].
图4.GAM模块中空间注意子模块的结构图[39]。
2.3. ACmix
The authors of [40] discovered that self-attention and convolution both heavily rely on the 1x1 convolution operation. To address this, they developed a hybrid model known as ACmix, which elegantly combines self-attention and convolution with minimal computational overhead. The model structure is illustrated in Figure 5.[40]的作者发现,自我注意和卷积都严重依赖于1x1卷积运算。为了解决这个问题,他们开发了一种名为ACmix的混合模型,该模型将自我注意力和卷积巧妙地结合在一起,并具有最小的计算开销。模型结构如图5所示。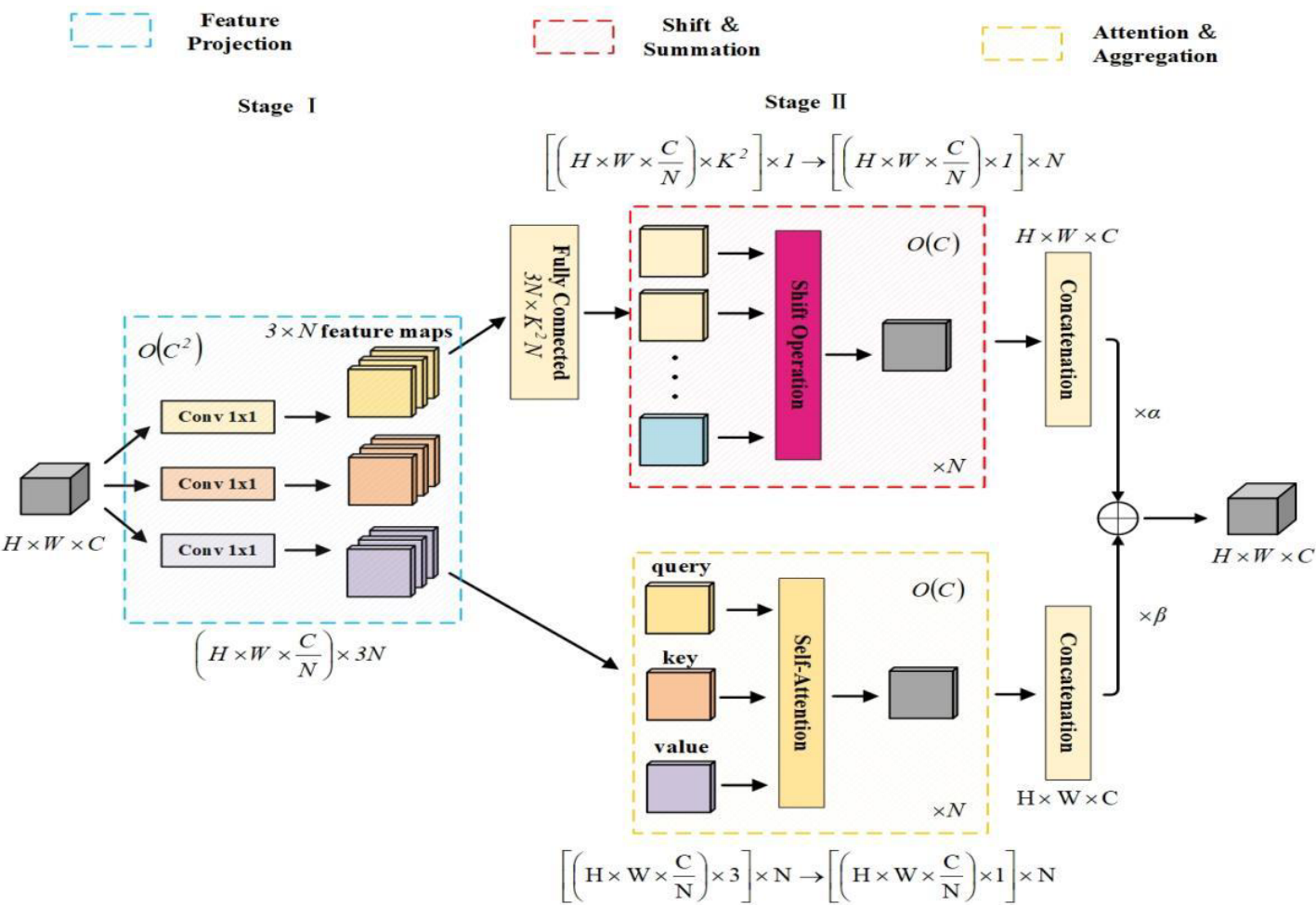
Figure 5. The structure diagram of ACmix module [40].
图5.ACmix模块的结构图[40]。
The first core is convolution [41]: Given a standard convolution of the kernel $K \in \mathfrak{R}^{C_{\text {out }} \times C_{\text {in }} \times k \times k}$ , tensor $F \in \mathfrak{R}^{C_{\text {in }} \times H \times W}$ , $G \in \mathfrak{R}^{C_{\text {out }} \times H \times W}$ as input and output feature maps, respectively, k is the kernel size, $C_{in}$ and $C_{out}$ are input and output channels. H, W denote height and width. $f_{ij} \in \mathfrak{R}^{C_{\text {in }}}$ , $g_{ij} \in \mathfrak{R}^{C_{\text {out }}}$ denote the feature tensor of the pixels (i, j), corresponding to F and G . The standard convolution can be expressed as equation (1):第一个核心是卷积[41]:给定内核$K \in \mathfrak{R}^{C_{\text {out }} \times C_{\text {in }} \times k \times k}$,张量$F \in \mathfrak{R}^{C_{\text {in }} \times H \times W}$,$G \in \mathfrak{R}^{C_{\text {out }} \times H \times W}$的标准卷积分别作为输入和输出特征映射,k是内核大小,$C_{in}$和$C_{out}$是输入和输出通道。H、W表示高度和宽度。$f_{ij} \in \mathfrak{R}^{C_{\text {in }}}$ ,$g_{ij} \in \mathfrak{R}^{C_{\text {out }}}$表示对应于F和G的像素的特征张量。标准卷积可以表示为等式(1):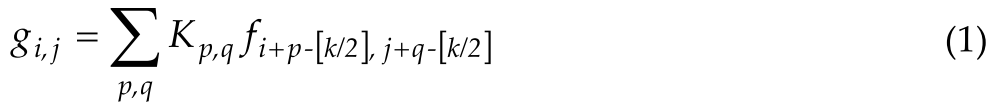
where $K_{p,q} \in \mathfrak{R}^{C_{\text {out }} \times C_{\text {in }}}$ subjecting to $p, q \in{0,1, \ldots, k-1}$ denotes the weight of the nucleus at position (p, q) , . Equation (1) can be simplified into equations (2) and (3).其中,$K_{p,q} \in \mathfrak{R}^{C_{\text {out }} \times C_{\text {in }}}$满足$p, q \in{0,1, \ldots, k-1}$表示在位置(p, q)处的原子核的重量。等式(1)可以简化为等式(2)和(3)。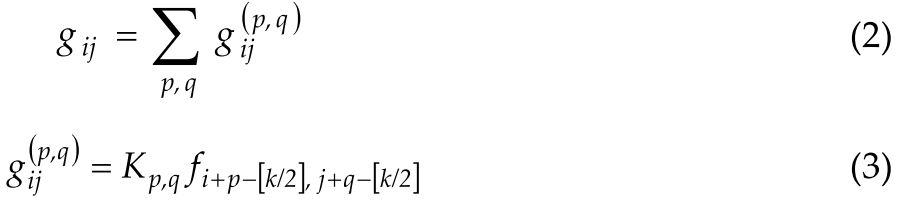
To further simplify the formula, define the Shift operation by $\widetilde{f} \triangleq \operatorname{Shift}(f, \Delta x, \Delta y)$为了进一步简化公式,将Shift运算定义为:$\widetilde{f} \triangleq \operatorname{Shift}(f, \Delta x, \Delta y)$
where Δx,|Δy correspond to horizontal and vertical displacements. Thus, equation (3) can be abbreviated to其中Δx,|Δy对应于水平和垂直位移。因此,等式(3)可以缩写为: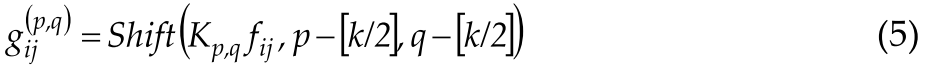
Standard convolution can be summarized in two steps:标准卷积可以总结为两个步骤:
(Convolution:)
State Ⅰ:
State Ⅱ: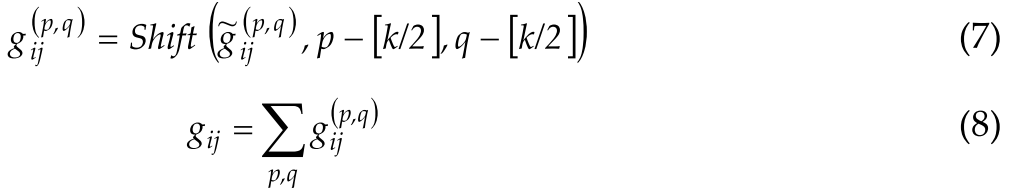
The next is Self-Attention [42]: Assuming that there is a standard self-attentive module withNheads, the output of the attention module is calculated as:下一个是Self-Attention [42]:假设有一个标准的Self-Attention模块,其中Nheads,注意力模块的输出计算为:
The ACmix module reveals the robust correlation between self-attention and convolution, leveraging the advantages of both techniques, and mitigating the need for repeated, high-complexity projection operations. As a result, it offers minimal computational overhead compared to either self-attention or pure convolution alone.ACmix模块揭示了自我注意力和卷积之间的强大相关性,利用了这两种技术的优势,并减少了对重复的高复杂度投影操作的需求。因此,与自注意或纯卷积相比,它提供了最小的计算开销。
3. Method
This section outlines the design of an underwater target detection model that leverages the improved YOLOv7 architecture. We design a ResNet-ACmix module (Section 3.1) and AC-E-ELAN structure (Section 3.2), finally resulting in the improved YOLOv7-AC model (Section 3.3).本节概述了利用改进的YOLOv 7架构的水下目标检测模型的设计。我们设计了一个ResNet-ACmix模块(第3.1节)和AC-E-ELAN结构(第3.2节),最终得到了改进的YOLOv 7-AC模型(第3.3节)。
3.1. ResNet-ACmix module3.1.ResNet-ACmix模块
The introduction of the ResNet-ACmix module into the Backbone component of YOLOv7 effectively preserves the coherence of the extracted feature information. This module is based on the bottleneck structure of ResNet [43], wherein the 3x3 convolution is substituted by the ACmix module, enabling adaptive focus on different regions and capturing more informative features, as illustrated in Figure 6. The input is divided into the main input and residual input, which helps prevent information loss, while reducing the number of parameters and computational requirements. The ResNet-ACmix module enables the network to attain deeper depths without encountering gradient disappearance, and the learning outcomes are more sensitive to fluctuations in network weights.在YOLOv 7的Backbone组件中引入ResNet-ACmix模块有效地保留了提取的特征信息的一致性。该模块基于ResNet [43]的瓶颈结构,其中3x 3卷积被ACmix模块取代,从而实现对不同区域的自适应聚焦并捕获更多信息特征,如图6所示。将输入分为主输入和剩余输入,这有助于防止信息丢失,同时减少参数数量和计算要求。ResNet-ACmix模块使网络能够达到更深的深度,而不会遇到梯度消失,并且学习结果对网络权重的波动更敏感。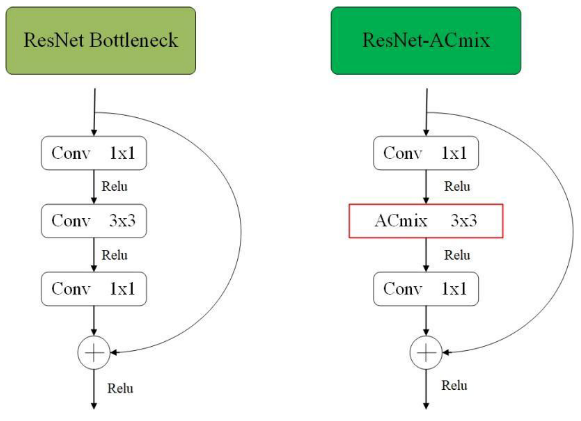
Figure 6. The structure diagram of ResNet-ACmix module (left: ResNet; right: ResNet-ACmix).
图6.ResNet-ACmix模块结构图(左:ResNet;右:ResNet-ACmix)。
3.2. AC-E-ELAN module
3.2.AC-E-ELAN模块
The proposed improvement to the E-ELAN component of YOLOv7 is based on the advanced ELAN architecture [44]. Unlike traditional ELAN networks, the extended E-ELAN employs an expand, shuffle, and merge cardinality approach that enables continuous enhancement of the network’s learning capability without disrupting the original gradient flow, thereby enhancing parameter utilization and computational efficiency. The feature extraction module of the E-ELAN component in YOLOv7 has been further improved by incorporating residual structures (i.e., 1x1 convolutional branch and jump connection branch) from the RepVgg architecture [45]. This has led to the development of the AC-E-ELAN structure, as depicted in Figure 7, which integrates the ACmixBlock, consisting of 3x3 convolutional blocks, with jump connections and 1x1 convolutional structures between the ACmixBlocks. This combination enables the network to benefit from both the rich features obtained during the training of a multi-branch model and the fast, memory-efficient inference obtained from a single-path model.YOLOv 7的E-ELAN组件的拟议改进基于高级ELAN架构[44]。与传统的ELAN网络不同,扩展E-ELAN采用扩展,洗牌和合并基数的方法,使网络的学习能力不断增强,而不会破坏原来的梯度流,从而提高参数利用率和计算效率。YOLOv 7中E-ELAN组件的特征提取模块通过合并残差结构(即,1x 1卷积分支和跳跃连接分支)。这导致了AC-E-ELAN结构的发展,如图7所示,它集成了由3x 3卷积块组成的ACmixBlock,在ACmixBlock之间具有跳转连接和1x 1卷积结构。这种组合使网络能够受益于在多分支模型训练期间获得的丰富特征和从单路径模型获得的快速,内存高效的推理。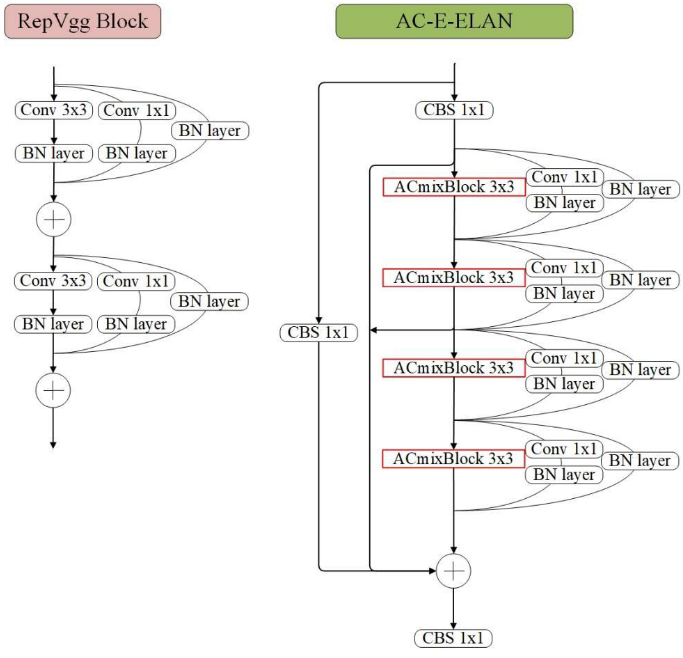
Figure 7. The structure diagram of AC-E-ELANmodule (left: RepVgg; right: AC-E-ELAN).
图7.AC-E-ELAN模块结构图(左:RepVgg;右:AC-E-ELAN)。
3.3. The proposed YOLOv7-AC model
3.3.YOLOv 7-AC模型
In the proposed YOLOv7-AC model, the original E-ELAN network in YOLOv7 is improved by the introduction of the AC-E-ELAN structure. The 3x3 convolutional blocks are replaced with 3x3 ACmixBlock, and jump connections and 1x1 convolutional structures are added between the ACmixBlock blocks, enhancing the ability of the model to focus on the valuable content and location of the input image samples, enriching the features extracted by the network, and reducing the model’s inference time. Additionally, the ResNet-ACmix blocks are integrated into the Backbone module, located behind the fourth CBS and at the bottom layer of the Backbone, to effectively retain the features collected by the Backbone and extract feature information of small targets and complex background targets, while simultaneously accelerating the network’s convergence and improving the detection accuracy. The incorporation of the GAM in the Backbone and Head of YOLOv7 enhances the network’s ability to extract deep and important features effectively.在YOLOv 7-AC模型中,通过引入AC-E-ELAN结构对YOLOv 7中原有的E-ELAN网络进行了改进。将3x 3卷积块替换为3x 3 ACmixBlock,并在ACmixBlock块之间添加跳转连接和1x 1卷积结构,增强了模型专注于输入图像样本的有价值内容和位置的能力,丰富了网络提取的特征,减少了模型的推理时间。此外,ResNet-ACmix模块被集成到骨干模块中,位于第四层CBS之后,位于骨干的底层,有效地保留了骨干收集的特征,提取小目标和复杂背景目标的特征信息,同时加速了网络的收敛,提高了检测精度。在YOLOv 7的主干和头部中加入GAM,增强了网络有效提取深度和重要特征的能力。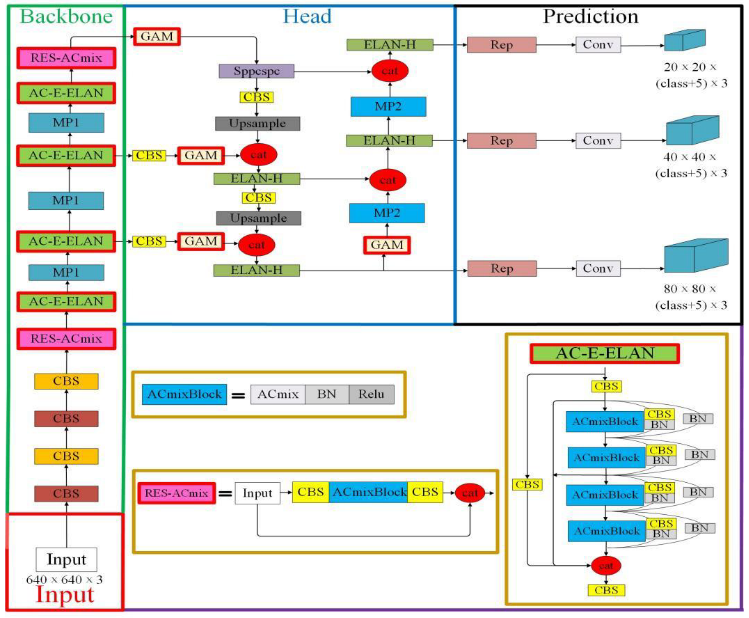
Figure 8. Structure diagram of the YOLOv7-AC model.
图8.YOLOv 7-AC模型结构图。
4. Experiments
In this section, the configuration of the experimental environment, hyperparameters, test dataset, and optimization of anchor boxes are described. The experimental results demonstrate that the proposed YOLOv7-AC model enhances both accuracy and speed in underwater target detection, thereby verifying its effectiveness and superiority in the challenging underwater detection environment.在本节中,描述了实验环境、超参数、测试数据集和锚框的优化的配置。实验结果表明,所提出的YOLOv 7-AC模型提高了水下目标检测的精度和速度,从而验证了其在水下目标检测环境中的有效性和优越性。
4.1. Experimental environment
The experimental platform is equipped with 5 vCPU Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz, NVIDIA GeForce RTX 3090 GPU with 24GB video memory size, Windows 11, 64-bit operating system. The software environments are CUDA 11.3, CUDNN 8.2.2, and the compiler Python 3.9.实验平台配备5个vCPU英特尔(R)至强(R)银4210 CPU@2.20 GHz,NVIDIA GeForce RTX 3090 GPU与24 GB视频内存大小,Windows 11,64位操作系统。软件环境是CUDA 11.3、CUDNN 8.2.2和编译器Python 3.9。
4.2. Model hyperparameter setting
The effectiveness of the YOLOv7-AC model was evaluated by training and testing the neural network using the hyperparameters detailed in Table 1.通过使用表1中详述的超参数训练和测试神经网络来评估YOLOv 7-AC模型的有效性。

Table 1. Experimental configuration.
表1.实验配置。
4.3.URPC数据集
This dataset was the 2021 National Underwater Robot Professional Competition (URPC) dataset, with 7600 underwater optical images (including manually annotated truth data). For more information, please find https://www.heywhale.com/home/competition/605ab78821e3f6003b56a7d8/content/0. The target groups to be evaluated in the experiment consist of four categories of seafood, namely “holothurian”, “echinus”, “scallop”, and “starfish”. In the traditional seafloor target detection often focus on sea food, so this paper remove the seagrass-related samples from the dataset, and keep 6575 valid images. Some of example images in the URPC dataset are shown in Figure 9.该数据集是2021年全国水下机器人专业竞赛(URPC)数据集,包含7600张水下光学图像(包括人工标注的真实数据)。欲了解更多信息,请访问https://www.heywhale.com/home/competition/605ab78821e3f6003b56a7d8/content/0。实验的评估对象包括四类海产,即“海参”、“海胆”、“扇贝”及“海星”。在传统的海底目标检测中往往集中在海产品上,因此本文从数据集中去除了与海草相关的样本,保留了6575幅有效图像。URPC数据集中的一些示例图像如图9所示。
Figure 9. Example images of the URPC dataset.
图9.URPC数据集的示例图像。
As depicted in Figure 10(a), the number of targets in each category was analyzed, with the most abundant being the echinus category, followed by starfish, scallop, and holothurian. The regularized target location map, as shown in Figure 10(b), reveals that the targets are more densely concentrated in the horizontal direction and comparatively dispersed in the vertical direction. Additionally, the normalized target size maps in Figure 10(c) indicate that the target sizes are relatively concentrated, with a majority of them being small. To create the experimental dataset, a 7:3 ratio of training set to test set was established, with 4521 images comprising the training set and 2054 images comprising the test set, divided randomly.如图10(a)所示,分析了每个类别中的靶标数量,最丰富的是海胆类别,其次是海星、扇贝和海参。如图10(B)所示,规则化的目标位置图揭示了目标在水平方向上更密集地集中,而在垂直方向上相对分散。此外,图10(c)中的标准化目标尺寸图表明,目标尺寸相对集中,其中大多数都很小。为了创建实验数据集,建立了7:3的训练集与测试集的比率,其中4521个图像包括训练集,2054个图像包括测试集,随机划分。
4.3.1. K-means++ to get anchor box of the URPC dataset
4.3.1.K-means++获取URPC数据集的锚框
In order to enhance the accuracy and efficiency of detection, this study employs the K-means++ algorithm, instead of the traditional K-means algorithm, to cluster the anchor boxes of the URPC dataset. The K-means++ algorithm selects the initial clustering centers based on the principle that the distance between the centers should be maximized, which is an improvement over the traditional K-means algorithm that randomly selects k data objects as initial centers. Additionally, the distance indicator used in the clustering process is changed from the Euclidean distance to 1-IOU (boxes, anchors). The YOLOv7 model has three detection feature maps, with each feature map corresponding to three anchors, resulting in a total of nine anchors. The dimensions of the three feature maps and the corresponding anchor boxes are specified in Table 2.为了提高检测的准确性和效率,本文采用K-means++算法代替传统的K-means算法对URPC数据集的锚盒进行聚类。K-means++算法根据中心之间的距离最大化的原则来选择初始聚类中心,这是对传统K-means算法随机选择k个数据对象作为初始中心的改进。此外,聚类过程中使用的距离指标从欧几里德距离更改为1-IOU(框,锚)。YOLOv 7模型有三个检测特征图,每个特征图对应三个锚点,总共有九个锚点。三个特征图和相应的锚框的尺寸在表2中指定。
Table 2. Anchor box parameters of the URPC dataset.
表2.URPC数据集的锚框参数。
4.3.2. Model evaluation metrics
4.3.2.模型评价指标
Commonly used basic metrics for target detection are Precision, Recall, Intersection over Union (IOU), etc. AP (Average - Precision) and mAP (mean Average Precision) value. The IOU metric is employed to measure the degree of overlap between the system-predicted bounding box and the ground-truth bounding box in the original image. ,The calculation is the intersection and concatenation ratio of Detection Result to Ground Truth as follow.常用的目标检测的基本指标有精度、召回率、交集等。AP(平均精度)和mAP(平均精度)值。IOU度量用于测量原始图像中系统预测的边界框和地面实况边界框之间的重叠程度。计算是检测结果与地面真值的交集和拼接比,如下所示。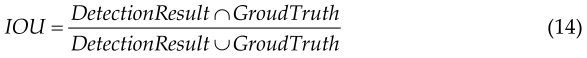
In the experiment, a threshold value of IOU was established. The Detection Result was considered as True Positive (TP) when the IOU value calculated between the Detection Result and the Ground Truth was greater than the threshold value, indicating the accurate identification of targets. Conversely, the Detection Result was considered as False Positive (FP) when the IOU value was less than the threshold value, representing incorrect identification. The number of undetected targets, referred to as False Negative (FN), was calculated as the number of Ground Truth instances with no matching Detection Result. Precision is defined as the proportion of True Positives in the recognized images, expressed as a percentage.在实验中,建立了IOU的阈值。当检测结果与地面真实值之间的IOU值大于阈值时,检测结果被认为是真阳性(TP),表明目标的准确识别。相反,当IOU值小于阈值时,检测结果被认为是假阳性(FP),表示不正确的识别。未检测到的目标的数量,被称为假阴性(FN),被计算为没有匹配检测结果的地面实况实例的数量。精度定义为识别图像中真阳性的比例,以百分比表示。
Recall is the proportion of all positive samples in the test set that identify the correct target.召回率是测试集中所有阳性样本中识别正确目标的比例。
A Precision-Recall (PR) curve plots precision along the vertical axis and recall along the horizontal axis, thereby illuminating the interplay between the accuracy of the classifier in identifying positive instances and its ability to encompass all positive instances. The Average Precision (AP) is a scalar representation of the area under the PR curve, with higher values indicating superior performance of the classifier.精确度-召回率(PR)曲线沿着垂直轴沿着绘制精确度,并且沿着水平轴绘制召回率沿着,从而阐明分类器在识别肯定实例中的准确度与其包含所有肯定实例的能力之间的相互作用。平均精度(AP)是PR曲线下面积的标量表示,较高的值表示分类器的上级性能。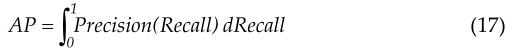
In target detection, the model usually detects many classes of targets, and each class can plot a PR curve, which in turn calculates an AP value. mAP represents the average of the APs of all classes.在目标检测中,该模型通常检测多类目标,每类目标可以绘制PR曲线,进而计算AP值。mAP表示所有类别的AP的平均值。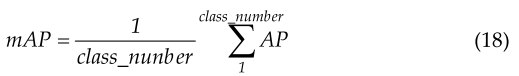
4.3.3. Experimental results and analysis of the URPC dataset
4.3.3.URPC数据集的实验结果和分析
The proposed YOLOv7-AC model was experimentally evaluated on the URPC dataset with respect to its detection performance. As illustrated in Figure 11, the results of the improved model demonstrate an improved detection efficiency on the various target categories, particularly the echinus category which boasts an average precision (AP) value of 92.2%. The mean average precision (mAP) for the model was calculated to have a value of 89.6%.在URPC数据集上对所提出的YOLOv 7-AC模型的检测性能进行了实验评估。如图11所示,改进模型的结果表明,对各种目标类别的检测效率有所提高,特别是海胆类别,其平均精度(AP)值为92.2%。模型的平均精密度(mAP)计算值为89.6%。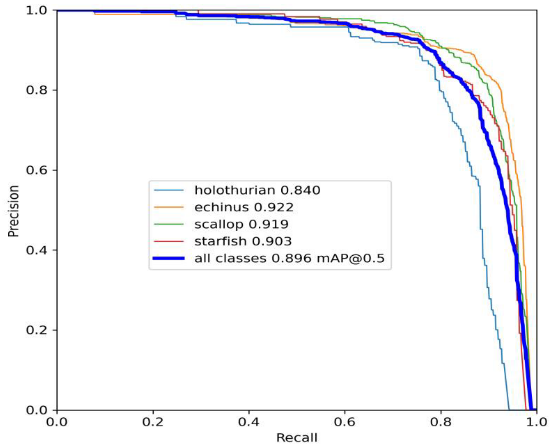
Figure 11. The precision-recall curve of the YOLOv7-AC model on the URPC dataset.
图11.YOLOv 7-AC模型在URPC数据集上的精确度-召回率曲线。
A confusion matrix was utilized to evaluate the accuracy of the proposed YOLOv7-AC model’s results. Each column of the confusion matrix represents the predicted proportions of each category, while each row represents the true proportions of the respective category in the data, as depicted in Figure 12. The analysis of Figure 12 reveals that the predicted categories of “holothurian”, “echinus”, “scallop” and “starfish” have correct prediction rates of 81%, 90%, 89% and 89%, respectively, which suggests that the model has a high degree of accuracy.混淆矩阵被用来评估所提出的YOLOv 7-AC模型的结果的准确性。混淆矩阵的每一列表示每个类别的预测比例,而每一行表示数据中相应类别的真实比例,如图12所示。图12的分析显示,“海参”、“海胆”、“扇贝”和“海星”的预测类别的正确预测率分别为81%、90%、89%和89%,这表明该模型具有较高的准确度。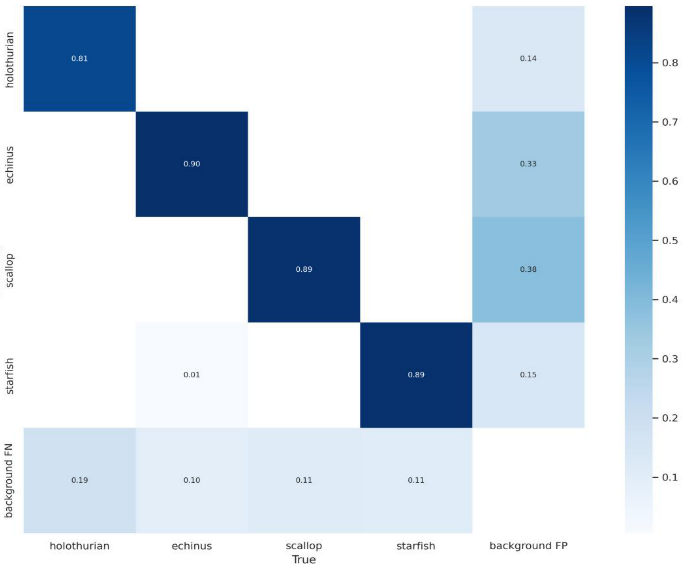
Figure 12. The confusion matrix of the YOLOv7-AC model on the URPC dataset.
图12.URPC数据集上YOLOv 7-AC模型的混淆矩阵。
Additionally, this study presents the graphical representation of the variations in the loss values including the Box loss, Objectness loss, and Classification loss. YOLOv7 adopts the GIOU Loss as the loss function for bounding boxes, where the Box loss is the mean of the GIOU loss function and a lower value indicates higher accuracy. The Objectness loss is the average value of the target detection loss, with a smaller value corresponding to higher accuracy. The Classification loss is the mean of the classification loss, with a lower value indicating higher accuracy, as demonstrated in Figure 13. As illustrated in Figure 13, the loss values demonstrate a steady decrease and eventual stabilization as the number of iterations increases, reaching convergence after 200 iterations.此外,这项研究提出了图形表示的损失值的变化,包括框损失,客观性损失,和分类损失。YOLOv7采用GIOU损失作为边界框的损失函数,其中框损失是GIOU损失函数的平均值,值越低表示精度越高。客观性损失是目标检测损失的平均值,较小的值对应于较高的精度。分类损失是分类损失的平均值,较低的值表示较高的准确性,如图13所示。如图13所示,随着迭代次数的增加,损失值稳步下降并最终稳定,在200次迭代后达到收敛。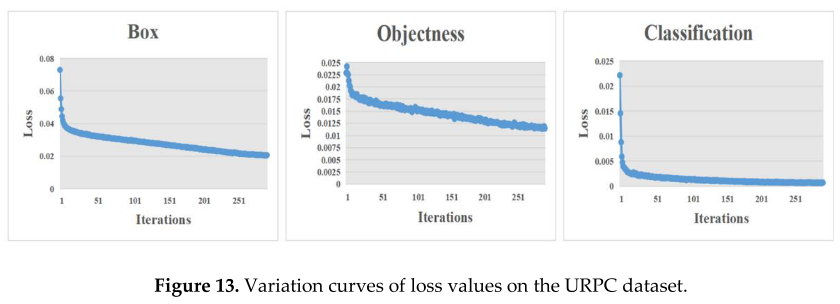
Figure 13. Variation curves of loss values on the URPC dataset.
图13.URPC数据集上损失值的变化曲线。
To further demonstrate the superiority of the proposed YOLOv7-AC model, a comparison was performed with popular target detection models, including YOLOv7, YOLOv6, YOLOv5s, SSD, etc. by conducting training and testing on the URPC dataset and comparing their evaluation metrics, such as mean Average Precision (mAP). The results of the comparison are presented in Table 3. As can be seen from the table, the YOLOv7-AC model outperforms the other detection algorithms, with mAP 3.4% higher than that of YOLOv7 and 6.1%, 6.4%, and 14.2% higher than that of YOLOv6, YOLOv5s, and SSD, respectively. These experimental results demonstrate the practical advantages of the proposed method in underwater target recognition.为了进一步证明所提出的YOLOv 7-AC模型的优越性,通过在URPC数据集上进行训练和测试并比较其评估指标,如平均精度(mAP),与流行的目标检测模型(包括YOLOv 7,YOLOv 6,YOLOv 5s,SSD等)进行比较。比较结果见表3。从表中可以看出,YOLOv 7-AC模型优于其他检测算法,mAP比YOLOv 7高3.4%,比YOLOv 6、YOLOv 5s和SSD分别高6.1%、6.4%和14.2%。实验结果表明了该方法在水下目标识别中的实用优势。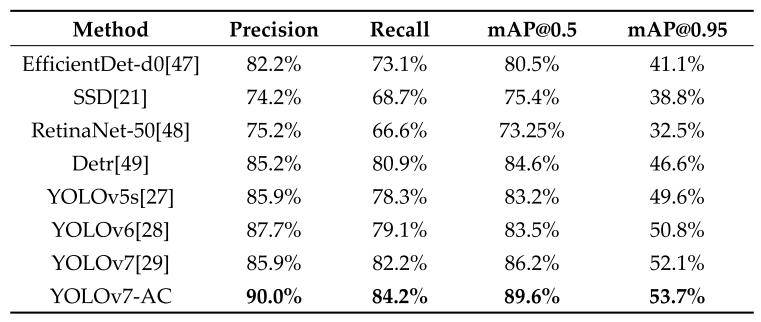
Table 3. Performance comparison of target detection model on the URPC dataset.
表3.目标检测模型在URPC数据集上的性能比较。
4.3.4. Ablation experiments of the URPC dataset
4.3.4.URPC数据集的消融实验
We performed ablation experiments in order to assess the effectiveness of different improvements on the model performance. Firstly, this paper uses the designed ResNet-ACmix and AC-E-ELAN models to extract features, then introduces GAM, and finally applies K-means++ to obtain the anchor box of the URPC dataset in this paper. The experimental results are shown in Table 4.我们进行了消融实验,以评估模型性能的不同改进的有效性。首先利用设计的ResNet-ACmix和AC-E-ELAN模型进行特征提取,然后引入GAM,最后应用K-means++获得URPC数据集的锚盒。实验结果如表4所示。
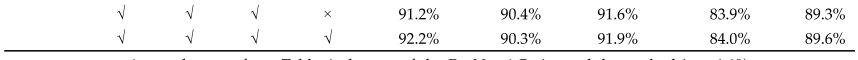
Table 4. Ablation comparison of model performance improvement on the URPC dataset.
表4.URPC数据集上模型性能改进的消融比较。
As can be seen from Table 4, the use of the ResNet-ACmix module resulted in a 1.1% increase in mAP value, and the AC-E-ELAN module acting as the model’s backbone network to obtain more useful features was the most critical improvement, which increased the model’s mAP by another 1.8% on top of the introduction of ResNet-ACmix. Finally, by incorporating GAM and using K-means++ clustering anchor box, mAP is also improved by 0.2% and 0.3% respectively based on the pre-experiments.从表4中可以看出,ResNet-ACmix模块的使用导致mAP值增加了1.1%,而AC-E-ELAN模块作为模型的骨干网络以获得更多有用的功能是最关键的改进,这使得模型的mAP在ResNet-ACmix的引入基础上又增加了1.8%。最后,通过引入GAM和使用K-means++聚类锚盒,在预实验的基础上,mAP也分别提高了0.2%和0.3%。
4.4. The Brackish Dataset
4.4.半咸水数据集
The Brackish dataset [50] is the first publicly available European underwater image dataset with 2465 images, including “fish”, “small_fish”, “crab”, “shrimp”, “jellyfish”, and “starfish”. Some of example images in the dataset are shown in Figure 14.Brackish数据集[50]是第一个公开的欧洲水下图像数据集,包含2465张图像,包括“鱼”,“小鱼”,“螃蟹”,“虾”,“水母”和“海星”。数据集中的一些示例图像如图14所示。
Figure 15(a) presents the distribution of the number of targets across various categories, with “Crab” having the largest representation. The regularized target location map is depicted in Figure 15(b), while Figure 15(c) illustrates the normalized target size maps, which reveal a majority of small targets. The URPC dataset was randomly divided into training and testing sets in a 7:3 ratio, with 1726 images being designated as the training set and 739 images as the testing set.图15(a)显示了各类目标数量的分布情况,“螃蟹”类的数量最多。在图15(B)中描绘了规则化的目标位置图,而图15(c)示出了标准化的目标尺寸图,其揭示了大多数小目标。URPC数据集以7:3的比例随机分为训练集和测试集,其中1726张图像被指定为训练集,739张图像被指定为测试集。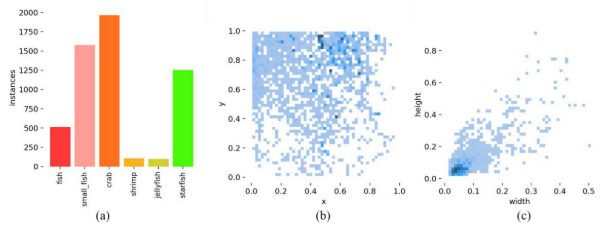
Figure 15. Statistical results of the Brackish dataset: (a) bar chart of the number of targets in each class; (b) normalized target location map; (c) normalized target size map.
图15.Brackish数据集的统计结果:(a)每个类别中目标数量的条形图;(b)归一化目标位置图;(c)归一化目标大小图。
4.4.1. K-means++ to get anchor box of the Brackish dataset
4.4.1.K-means++获取Brackish数据集的锚框
This study employs the K-means++ algorithm to cluster the anchor boxes of the Brackish dataset. The dimensions of the three feature maps and the corresponding anchor boxes are shown in Table 5.本研究采用K-means++算法对Brackish数据集的锚盒进行聚类。三个特征图的尺寸和相应的锚框如表5所示。
Table 5. Anchor box parameters of the Brackish dataset.
表5 Brackish数据集的锚框参数。
4.4.2. Experimental results and analysis of the Brackish dataset
4.4.2.半咸水数据集的实验结果和分析
The effectiveness of the proposed YOLOv7-AC model was evaluated by conducting experiments on the Brackish dataset. The results of the detection performance are depicted in the precision-recall curve presented in Figure 16. As can be observed from the figure, the YOLOv7-AC model demonstrates improved performance in detecting various targets, particularly shrimp and starfish, which achieved an average precision value of 99.5%. The mAP of the model was 97.4%.通过在Brackish数据集上进行实验,评估了所提出的YOLOv 7-AC模型的有效性。检测性能的结果如图16中的精确度-召回率曲线所示。从图中可以看出,YOLOv 7-AC模型在检测各种目标,特别是虾和海星方面表现出更好的性能,平均精度达到99.5%。该模型的mAP为97.4%。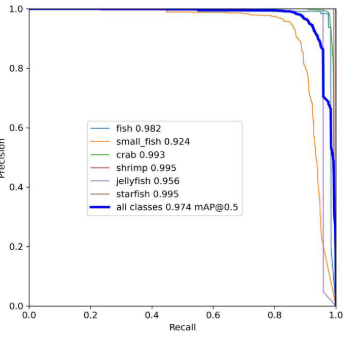
Figure 16. The precision-recall curve of the YOLOv7-AC model on the Brackish dataset.
图16 YOLOv 7-AC模型在Brackish数据集上的精确度-召回率曲线。
The confusion matrix with regard to the Brackish dataset was shown in Figure 17. As can be seen from Figure 17, most of the targets were correctly predicted, indicating that the model is highly accurate.图17中显示了关于Brackish数据集的混淆矩阵。从图17中可以看出,大多数目标都被正确预测,表明该模型具有高度准确性。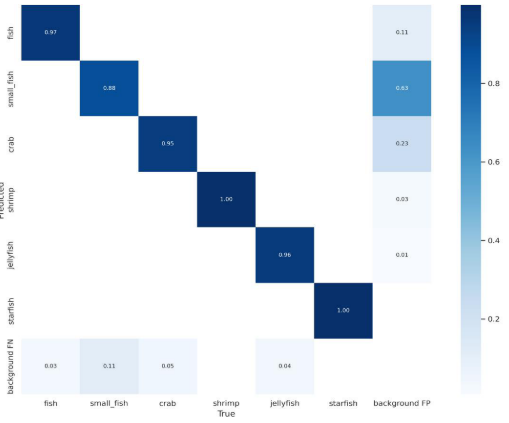
Figure 17. The confusion matrix of the YOLOv7-AC model (the Brackish dataset).
图17 YOLOv 7-AC模型的混淆矩阵(Brackish数据集)。
The variation curves of loss values with regard to the Brackish dataset were shown in Figure 18. As can be seen in Figure 18, the loss value steadily decreased and stabilized as the number of iterations increased.图18中显示了关于半咸水数据集的损失值的变化曲线。从图18中可以看出,随着迭代次数的增加,损失值稳步下降并趋于稳定。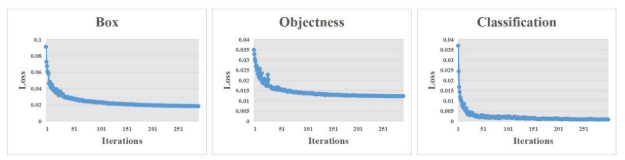
Figure 18. Variation curves of loss values on the Brackish dataset.
图18 Brackish数据集上损失值的变化曲线。
To further demonstrate the superiority of the proposed YOLOv7-AC model, a performance comparison was performed with popular target detection models on the Brackish dataset, where the correspondingly experimental results are shown in Table 6. As depicted in Table 6, the performance of the proposed YOLOv7-AC model was found to be superior to that of other popular target detection models, with mAP 1.1% higher than YOLOv7, and a respective improvement of 1.6%, 0.6%, and 7.5% compared to YOLOv6, YOLOv5s, and SSD. These experimental results demonstrate the clear advantages of the proposed method in the recognition of underwater targets.为了进一步证明所提出的YOLOv 7-AC模型的优越性,在Brackish数据集上与流行的目标检测模型进行了性能比较,其中相应的实验结果如表6所示。如表6所示,发现所提出的YOLOv 7-AC模型的性能上级其他流行的目标检测模型的性能,其中mAP比YOLOv 7高1.1%,并且与YOLOv 6、YOLOv 5s和SSD相比分别提高了1.6%、0.6%和7.5%。实验结果表明,该方法在水下目标识别中具有明显的优势。

Table 6. Performance comparison of target detection model on the Brackish dataset.
表6 目标检测模型在Brackish数据集上的性能比较。
4.4.3. Ablation experiments of the Brackish dataset
Accordingly, the ablation experiments were conducted to observe the effectiveness of different improvements on the model performance on the Brackish dataset, where the experimental results were shown in Table 7. As can be observed from Table 7, the application of each individual improvement leads to a relatively modest increase in performance. The integration of the ResNet-ACmix module and the AC-E-ELAN module resulted in a 0.2% and 0.4% increase in the mAP, respectively. Furthermore, the incorporation of GAM and the utilization of K-means++ clustering anchor boxes resulted in a 0.4% and 0.1% increase in the mAP, respectively, as seen from the pre-experiments.因此,进行消融实验以观察对Brackish数据集上的模型性能的不同改进的有效性,其中实验结果示于表7中。从表7中可以看出,应用每一个单独的改进都会导致性能相对适度的提高。ResNet-ACmix模块和AC-E-ELAN模块的集成分别使mAP增加了0.2%和0.4%。此外,GAM的并入和K-均值++聚类锚框的利用分别导致mAP增加0.4%和0.1%,如从预实验所见。
Table 7. Ablation comparison of model performance improvement on the Brackish dataset.
表7 Brackish数据集上模型性能改进的消融比较。
4.5. The speed comparison ofYOLOv7-AC and other models
4.5.YOLOv 7-AC与其他模型的速度对比
The performance of the proposed YOLOv7-AC model in terms of speed was evaluated by comparing its FPS metric with the popular target detection models applied to the URPC and Brackish datasets for training and testing. The experimental results, as shown in Table 8, indicate that the YOLOv5s model achieved the highest FPS score on both datasets, with YOLOv7-AC ranking second, slightly higher than YOLOv7, and significantly faster than the other models. These results demonstrate that the proposed YOLOv7-AC model not only offers improved accuracy, but also exhibits a noteworthy level of efficiency.通过将其FPS度量与应用于URPC和Brackish数据集进行训练和测试的流行目标检测模型进行比较,评估了所提出的YOLOv 7-AC模型在速度方面的性能。如表8所示的实验结果表明,YOLOv 5s模型在两个数据集上都获得了最高的FPS分数,YOLOv 7-AC排名第二,略高于YOLOv 7,并且明显快于其他模型。这些结果表明,所提出的YOLOv 7-AC模型不仅提供了更高的精度,而且还表现出显着的效率水平。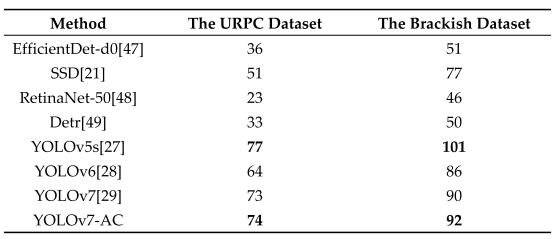
Table 8. Target detection model FPS comparison of the URPC dataset and the Brackish dataset.
表8 URPC数据集和Brackish数据集的目标检测模型FPS比较。
5. Discussion
The challenges associated with detecting targets in harsh underwater scenes can be attributed to the issues of color distortion and low visibility caused by medium scattering and absorption in underwater optical images. To address these challenges, this study proposes the innovative use of the ACmix module, the design of the ResNet-ACmix module and the AC-E-ELAN module based on ACmix, along with the incorporation of the GAM, to enhance the extraction of informative features. The results of the experiments demonstrate the efficacy of the proposed YOLOv7-AC model in harsh underwater scenarios, as indicated by its improved performance compared to the traditional YOLOv7. This is demonstrated through a comparison of the detection results of YOLOv7 and YOLOv7-AC on the URPC dataset and the Brackish dataset, as illustrated in Figure 19. As demonstrated by this figure, the proposed YOLOv7-AC model outperforms the YOLOv7 model in terms of error detection and omission detection. Not only is a higher number of targets accurately detected, but the prediction boxes are also more precise.水下光学图像中的介质散射和吸收会导致图像颜色失真和可见度降低,这给水下目标检测带来了挑战。为了应对这些挑战,本研究提出了创新使用的ACmix模块,设计的ResNet-ACmix模块和AC-E-ELAN模块的基础上ACmix,沿着的GAM的合并,以提高信息特征的提取。实验结果表明,所提出的YOLOv 7-AC模型在恶劣的水下场景中的有效性,与传统的YOLOv 7相比,其性能有所改善。这通过比较YOLOv 7和YOLOv 7-AC在URPC数据集和半咸水数据集上的检测结果来证明,如图19所示。如该图所示,所提出的YOLOv 7-AC模型在错误检测和遗漏检测方面优于YOLOv 7模型。不仅可以准确检测到更多的目标,而且预测框也更精确。
Figure 19. Detection results of YOLOv7 (left) and YOLOv7-AC (right) in harsh underwater scenes.
图19.YOLOv 7(左)和YOLOv 7-AC(右)在水下恶劣场景下的检测结果。
However, despite the improved performance, the YOLOv7-AC model still exhibits instances of false detection and missing detection in highly complex underwater environments. This can be observed in the examples presented in Figure 20.然而,尽管性能有所提高,YOLOv 7-AC模型在高度复杂的水下环境中仍然存在误检和漏检的情况。这可以在图20所示的示例中观察到。
Figure 20. (a) Error detection of YOLOv7-AC in highly complex underwater environments (left: marked in black boxes); (b) omission detection of YOLOv7-AC in highly complex underwater environments (right: marked in red boxes).
图20 (a)高度复杂水下环境中YOLOv 7-AC的错误检测(左:用黑框标记);(b)高度复杂水下环境中YOLOv 7-AC的遗漏检测(右:用红框标记)。
6. Conclusion
In this study, an improved YOLOv7-based network, referred to as YOLOv7-AC, is presented for the purpose of detecting targets in complex underwater environments. To achieve this, the AC-E-ELAN module is designed to emphasize target features, while the incorporation of jump connections and a 1x1 convolutional structure within the ACmixBlock improves computational speed and memory utilization. The ResNet-ACmix module is further developed to extract deep features that are more effectively trained by the network. Furthermore, the use of GAM and K-means++ enhances the overall performance of the detection. Experiments were conducted using the URPC and Brackish datasets, and the results were compared to those obtained using popular target detection algorithms and the proposed YOLOv7-AC model. The results indicate that the proposed YOLOv7-AC model surpasses the state-of-the-art target detection models in terms of its robustness and performance in complex underwater environments.在这项研究中,一个改进的YOLOv 7为基础的网络,简称为YOLOv 7-AC,提出了在复杂的水下环境中检测目标的目的。为了实现这一目标,AC-E-ELAN模块被设计为强调目标特征,而在ACmixBlock中加入跳转连接和1x 1卷积结构可以提高计算速度和内存利用率。ResNet-ACmix模块被进一步开发,以提取由网络更有效训练的深度特征。此外,GAM和K-means++的使用增强了检测的整体性能。使用URPC和Brackish数据集进行了实验,并将结果与使用流行的目标检测算法和所提出的YOLOv 7-AC模型获得的结果进行了比较。结果表明,YOLOv 7-AC模型在复杂水下环境下的鲁棒性和性能优于现有的目标检测模型。
However, it must be noted that the availability of high-quality underwater datasets and images remains a major challenge in the development of target detection in underwater environments. Hence, the future research efforts will aim at collecting a large and diverse set of underwater datasets and employing image enhancement techniques to improve the overall quality of underwater images, which are crucial for the detection of underwater targets.然而,必须指出的是,高质量的水下数据集和图像的可用性仍然是水下环境中目标检测发展的主要挑战。因此,未来的研究工作将致力于收集大量和多样化的水下数据集,并采用图像增强技术来提高水下图像的整体质量,这对于水下目标的检测至关重要。
GPT解读
核心内容
这篇文章的核心内容是关于一种改进的YOLOv7网络(YOLOv7-AC)用于水下目标检测的研究。以下是文章的主要点:
- 研究背景:水下目标检测对于海洋探索至关重要,但传统的水下目标检测方法面临着特征提取不准确、检测速度慢和在复杂水下环境中缺乏鲁棒性等挑战。
- 改进的YOLOv7网络(YOLOv7-AC):为了解决这些限制,研究提出了一种改进的YOLOv7网络。这个网络通过以下方式进行优化:
- 使用ACmixBlock模块替换E-ELAN结构中的3x3卷积块。
- 在ACmixBlock模块之间加入跳跃连接和1x1卷积架构以提高特征提取和网络推理速度。
- 设计ResNet-ACmix模块以避免特征信息丢失并减少计算量。
- 在模型的骨干和头部部分插入全局注意力机制(GAM)以提高特征提取。
- 使用K-means++算法代替K-means来获取锚框,以提高模型精度。
- 实验结果:改进的YOLOv7网络在URPC数据集和Brackish数据集上分别实现了89.6%和97.4%的平均精度(mAP),并且与原始YOLOv7模型相比,帧率(FPS)更高。
- 研究贡献:文章提出了以下创新点:
- 引入全局注意力机制(GAM)以更有效地捕获特征。
- 引入ACmix(结合自注意力和卷积的优点)。
- 设计ResNet-ACmix模块以增强骨干网络的特征提取能力。
- 优化YOLOv7网络的E-ELAN模块,通过引入跳跃连接和1x1卷积结构。
- 实验设置:详细描述了实验环境、超参数设置、测试数据集以及锚框的优化方法。
- 性能比较:与YOLOv7、YOLOv6、YOLOv5s、SSD等流行的目标检测模型进行了性能比较,证明了YOLOv7-AC模型在水下目标检测中的优越性。
- 讨论与结论:尽管YOLOv7-AC模型在水下目标检测方面表现出色,但在高度复杂的水下环境中仍存在误检和漏检的情况。未来的研究将致力于收集更多样化的水下数据集,并采用图像增强技术来提高水下图像质量,这对于水下目标检测至关重要。
文章还提供了源代码的公开链接:https://github.com/NZWANG/YOLOV7-AC,以便其他研究者可以访问和使用。