Centralized Feature Pyramid for Object Detection
用于目标检测的集中式特征金字塔
Abstract
Visual feature pyramid has shown its superiority in both effectiveness and efficiency in a wide range of applications. However, the existing methods exorbitantly concentrate on the inter-layer feature interactions but ignore the intra-layer feature regulations, which are empirically proved beneficial. Although some methods try to learn a compact intra-layer feature representation with the help of the attention mechanism or the vision transformer, they ignore the neglected corner regions that are important for dense prediction tasks. To address this problem, in this paper, we propose a Centralized Feature Pyramid (CFP) for object detection, which is based on a globally explicit centralized feature regulation. Specifically, we first propose a spatial explicit visual center scheme, where a lightweight MLP is used to capture the globally long-range dependencies and a parallel learnable visual center mechanism is used to capture the local corner regions of the input images. Based on this, we then propose a globally centralized regulation for the commonly-used feature pyramid in a top-down fashion, where the explicit visual center information obtained from the deepest intra-layer feature is used to regulate frontal shallow features. Compared to the existing feature pyramids, CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an allround yet discriminative feature representation. Experimental results on the challenging MS-COCO validate that our proposed CFP can achieve the consistent performance gains on the stateof-the-art YOLOv5 and YOLOX object detection baselines. The code has been released at: CFPNet.视觉特征金字塔在广泛的应用中显示了其在有效性和效率上的优越性。然而,现有的方法过分集中在层间的功能相互作用,而忽略了层内的功能规则,这是经验证明是有益的。虽然一些方法试图在注意力机制或视觉Transformer的帮助下学习紧凑的层内特征表示,但它们忽略了对密集预测任务很重要的被忽略的角区域。为了解决这个问题,在本文中,我们提出了一个集中式特征金字塔(CFP)的对象检测,这是基于一个全球显式的集中式特征调节。具体来说,我们首先提出了一个空间显式视觉中心计划,其中一个轻量级的MLP是用来捕捉全局的长程依赖和一个并行学习的视觉中心机制是用来捕捉输入图像的局部角区域。在此基础上,我们提出了一种全局集中的调节常用的特征金字塔在一个自上而下的方式,其中从最深的层内特征获得的显式视觉中心信息用于调节正面浅功能。与现有的特征金字塔相比,CFP不仅具有捕获全局长距离依赖的能力,而且能够有效地获得全面而有区别的特征表示。在具有挑战性的MS-COCO上的实验结果验证了我们提出的CFP可以在最先进的YOLOv 5和YOLOX对象检测基线上实现一致的性能增益。该代码已发布在:CFPNet。
I. INTRODUCTION
Object detection is one of the most fundamental yet challenging research tasks in the community of computer vision, which aims to predict a unique bounding box for each object of the input image that contains not only the location but also the category information [1]. In the past few years, this task has been extensively developed and applied to a wide range of potential applications, e.g., autonomous driving [2] and computer-aided diagnosis [3].目标检测是计算机视觉领域最基本但最具挑战性的研究任务之一,其目的是为输入图像中的每个目标预测一个唯一的边界框,该边界框不仅包含位置信息,还包含类别信息[1]。在过去的几年中,这项任务得到了广泛的发展,并应用于广泛的潜在应用,例如,自动驾驶[2]和计算机辅助诊断[3]。
The successful object detection methods are mainly based on the Convolutional Neural Network (CNN) as the backbone followed with a two-stage (e.g., Fast/Faster R-CNN [4], [5]) or single-stage (e.g., SSD [6] and YOLO [7]) framework. However, due to the uncertainty object sizes, a single feature scale cannot meet requirements of the high-accuracy recognition performance. To this end, methods (e.g., SSD [6] and FFP [8]) based on the in-network feature pyramid are proposed and achieve satisfactory results effectively and efficiently. The unified principle behind these methods is to assign region of interest for each object of different size with the appropriate contextual information and enable these objects to be recognized in different feature layers.成功的对象检测方法主要基于卷积神经网络(CNN)作为骨干,随后是两阶段(例如,快速/更快的R-CNN [4],[5])或单级(例如,SSD [6]和YOLO [7])框架。然而,由于目标尺寸的不确定性,单一的特征尺度不能满足高精度识别性能的要求。为此,方法(例如,SSD [6]和FFP [8])提出了基于网络内特征金字塔的方法,并取得了令人满意的效果。这些方法背后的统一原则是为不同大小的每个对象分配具有适当上下文信息的感兴趣区域,并使这些对象能够在不同的特征层中被识别。
Feature interactions among pixels or objects are important [9]. We consider that effective feature interaction can make image features see wider and obtain richer representations, so that the object detection model can learn an implicit relation (i.e., the favorable co-occurrence features [10], [11]) between pixels/objects, which has been empirically proved to be beneficial to the visual recognition tasks [12], [13], [14], [15], [16], [17], [18]. For example, FPN [17] proposes a topdown inter-layer feature interaction mechanism, which enables shallow features to obtain the global contextual information and semantic representations of deep features. NAS-FPN [13] tries to learn the network structure of the feature pyramid part via a network architecture search strategy, and obtains a scalable feature representation. Besides the inter-layer interactions, inspired by the non-local/self-attention mechanism [19], [20], the finer intra-layer interaction methods for spatial feature regulation are also applied to object detection task, e.g., nonlocal features [21] and GCNet [22]. Based on the above two interaction mechanisms, FPT [15] further proposes an interlayer cross-layer and intra-layer cross-space feature regulation method, and has achieved remarkable performances.像素或对象之间的特征交互很重要[9]。我们认为有效的特征交互可以使图像特征看得更宽,获得更丰富的表示,从而使目标检测模型可以学习到一种隐式关系(即,[10],[11]),这已被经验证明是有益的视觉识别任务[12],[13],[14],[15],[16],[17],[18]。例如,FPN [17]提出了一种自顶向下的层间特征交互机制,该机制使浅层特征能够获得全局上下文信息和深层特征的语义表示。NAS-FPN [13]试图通过网络架构搜索策略学习特征金字塔部分的网络结构,并获得可扩展的特征表示。除了层间交互之外,受非局部/自注意机制的启发[19],[20],用于空间特征调节的更精细的层内交互方法也适用于对象检测任务,例如,非局部特征[21]和GCNet [22]。基于上述两种交互机制,FPT [15]进一步提出了层间跨层和层内跨空间的特征调控方法,并取得了显著的效果。
Despite the initiatory success in object detection, the above methods are based on the CNN backbone, which suffer from the inherent limit receptive fields. As shown in Figure 1 (a), the standard CNN backbone features can only locate those most discriminative object regions (e.g., the “body of an airplane” and the “motorcycle pedals”). To solve this problem, vision transformer-based object detection methods [24], [23], [25], [26] have been recently proposed and flourished. These methods first divide the input image into different image patches, and then use the multi-head attention-based feature interaction among patches to complete the purpose of obtaining the global long-range dependencies. As expected, the feature pyramid is also employed in a vision transformer, e.g., PVT [26] and Swin Transformer [25]. Although these methods can address the limited receptive fields and the local contextual information in CNN, an obvious drawback is their large computational complexity. For example, a Swin-B [25] has almost 3× model FLOPs (i.e., 47.0 G vs 16.0 G) than a performance-comparable CNN model RegNetY [27] with the input size of 224 × 224. Besides, as shown in Figure 1 (b), since vision transformer-based methods are implemented in an omnidirectional and unbiased learning pattern, which is easy to ignore some corner regions (e.g., the “airplane engine”, the “motorcycle wheel” and the “bat”) that are important for dense prediction tasks. These drawbacks are more obvious on the large-scale input images. To this end, we rise a question: is it necessary to use transformer encodes on all layers? To answer such a question, we start from an analysis of shallow features. Researches of the advanced methods [28], [29], [30] show that the shallow features mainly contain some general object feature patterns, e.g., texture, colour and orientation, which are often not global. In contrast, the deep features reflect the object-specific information, which usually requires global information [31], [32]. Therefore, we argue that the transformer encoder is unnecessary in all layers.尽管在目标检测方面取得了初步的成功,但上述方法都是基于CNN主干的,其存在固有的有限感受野。如图1(a)所示,标准CNN骨干特征只能定位那些最具区分力的对象区域(例如,“飞机的机身”和“摩托车踏板”)。为了解决这个问题,最近提出了基于视觉变换的目标检测方法[24],[23],[25],[26]并蓬勃发展。这些方法首先将输入图像划分为不同的图像块,然后利用块间基于多头注意力的特征交互来完成获取全局长距离依赖关系的目的。如所预期的,特征金字塔也用于视觉Transformer中,例如,PVT [26]和Swin Transformer [25]。虽然这些方法可以解决CNN中有限的感受野和局部上下文信息,但一个明显的缺点是它们的计算复杂度很大。例如,Swin-B [25]具有几乎3×模型FLOP(即,47.0 G与16.0 G)比输入大小为224 × 224的性能相当的CNN模型RegNetY [27]。此外,如图1(b)所示,由于基于视觉变换的方法是以全向和无偏的学习模式实现的,这很容易忽略一些角落区域(例如,“飞机发动机”、“摩托车车轮”和“蝙蝠”),它们对于密集预测任务很重要。这些缺点在大规模输入图像上更加明显。为此,我们提出了一个问题:是否有必要在所有层上使用Transformer编码?为了回答这个问题,我们从分析浅层特征开始。先进方法[28]、[29]、[30]的研究表明,浅层特征主要包含一些通用的对象特征模式,例如,纹理、颜色和方向,这些往往不是全局性的。相比之下,深层特征反映了对象特定的信息,这通常需要全局信息[31],[32]。因此,我们认为Transformer编码器在所有层中是不必要的。
Fig. 1. Visualizations of image feature evolution for vision recognition tasks. For the input images in (a), a CNN model in (b) only locates those most discriminative regions; although the progressive model in (c) can see wider under the help of the attention mechanism [20] or transformer [23], it usually ignores the corner cues that are important for dense prediction tasks; our model in (d) can not only see wider but also more well-rounded by attaching the centralized constraints on features with the advanced long-range dependencies, which is more suitable for dense prediction tasks. Best viewed in color.
Fig. 1.视觉识别任务中图像特征演化的可视化。对于(a)中的输入图像,(B)中的CNN模型仅定位那些最具辨别力的区域;尽管(c)中的渐进模型可以在注意力机制[20]或Transformer [23]的帮助下看到更宽的区域,但它通常忽略了对密集预测任务很重要的角落线索;我们在(d)中的模型不仅可以看到更宽,而且通过将集中式约束附加到具有高级长距离依赖性的特征上来更全面,这更适合于密集预测任务。最好用彩色观看。
In this work, we propose a Centralized Feature Pyramid (CFP) network for object detection, which is based on a globally explicit centralized regulation scheme. Specifically, based on an visual feature pyramid extracted from the CNN backbone, we first propose an explicit visual center scheme, where a lightweight MLP architecture is used to capture the long-range dependencies and a parallel learnable visual center mechanism is used to aggregate the local key regions of the input images. Considering the fact that the deepest features usually contain the most abstract feature representations scarce in the shallow features [33], based on the proposed regulation scheme, we then propose a globally centralized regulation for the extracted feature pyramid in a top-down manner, where the spatial explicit visual center obtained from the deepest features is used to regulate all the frontal shallow features simultaneously. Compared to the existing feature pyramids, as shown in Figure 1 (c), CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an all-round yet discriminative feature representation. To demonstrate the superiority, extensive experiments are carried out on the challenging MS-COCO dataset [34]. Results validate that our proposed CFP can achieve the consistent performance gains on the state-of-the-art YOLOv5 [35] and YOLOX [36] object detection baselines.在这项工作中,我们提出了一个集中式特征金字塔(CFP)网络的对象检测,这是基于一个全球明确的集中式监管计划。具体来说,基于从CNN主干中提取的视觉特征金字塔,我们首先提出了一个显式的视觉中心方案,其中使用轻量级MLP架构来捕获长程依赖关系,并使用并行可学习的视觉中心机制来聚合输入图像的局部关键区域。考虑到最深特征通常包含浅层特征中缺乏的最抽象的特征表示[33],基于所提出的调节方案,我们然后以自顶向下的方式对提取的特征金字塔提出全局集中式调节,其中从最深特征获得的空间显式视觉中心用于同时调节所有前部浅层特征。与现有的特征金字塔相比,如图1(c)所示,CFP不仅能够捕获全局长程依赖关系,而且还有效地获得全面而有区别的特征表示。为了证明其优越性,在具有挑战性的MS-COCO数据集上进行了大量实验[34]。结果验证了我们提出的CFP可以在最先进的YOLOv 5 [35]和YOLOX [36]对象检测基线上实现一致的性能增益。
Fig. 1. Visualizations of image feature evolution for vision recognition tasks. For the input images in (a), a CNN model in (b) only locates those most discriminative regions; although the progressive model in (c) can see wider under the help of the attention mechanism [20] or transformer [23], it usually ignores the corner cues that are important for dense prediction tasks; our model in (d) can not only see wider but also more well-rounded by attaching the centralized constraints on features with the advanced long-range dependencies, which is more suitable for dense prediction tasks. Best viewed in color.
Fig. 1.视觉识别任务中图像特征演化的可视化。对于(a)中的输入图像,(B)中的CNN模型仅定位那些最具辨别力的区域;尽管(c)中的渐进模型可以在注意力机制[20]或Transformer [23]的帮助下看到更宽的区域,但它通常忽略了对密集预测任务很重要的角落线索;我们在(d)中的模型不仅可以看到更宽,而且通过将集中式约束附加到具有高级长距离依赖性的特征上来更全面,这更适合于密集预测任务。最好用彩色观看。
Our contributions are summarized as the following: 1) We proposed a spatial explicit visual center scheme, which consists of a lightweight MLP for capturing the global long-range dependencies and a learnable visual center for aggregating the local key regions. 2) We proposed a globally centralized regulation for the commonly-used feature pyramid in a topdown manner. 3) CFP achieved the consistent performance gains on the strong object detection baselines.1)提出了一种空间显式视觉中心方案,该方案由一个用于捕获全局长程依赖的轻量级MLP和一个用于聚集局部关键区域的可学习视觉中心组成。2)我们提出了一个全球性的集中监管的常用功能金字塔自上而下的方式。3)CFP在强对象检测基线上实现了一致的性能增益。
II. RELATED WORK
A. Feature Pyramid in Computer Vision
A.计算机视觉中的特征金字塔
Feature pyramid is a fundamental neck network in modern recognition systems that can be effectively and efficiently used to detect objects with different scales. SSD [6] is one of the first approaches that uses a pyramidal feature hierarchy representation, which captures multi-scale feature information through network of different spatial sizes, thus the model recognition accuracy is improved. FPN [17] hierarchically mainly relies on the bottom-up in-network feature pyramid, which builds a top-down path with lateral connections from multi-scale high-level semantic feature maps. Based on which, PANet [16] further proposed an additional bottom-up pathway based on FPN to share feature information between the interlayer features, such that the high-level features can also obtain sufficient details in low-level features. Under the help of the neural architecture search, NAS-FPN [13] uses spatial search strategy to connect across layers via a feature pyramid and obtains the extensible feature information. M2Det [37] extracted multi-stage and multi-scale features by constructing multi-stage feature pyramid to achieve cross-level and cross-layer feature fusion. In general, 1) the feature pyramid can deal with the problem of multi-scale change in object recognition without increasing the computational overhead; 2) the extracted features can generate multi-scale feature representations including some high resolution features. In this work, we propose an intra-layer feature regulation from the perspective of inter-layer feature interactions and intra-layer feature regulations of feature pyramids, which makes up for the shortcomings of current methods in this regard.特征金字塔是现代识别系统中的一种基本颈部网络,可以有效地用于检测不同尺度的目标。SSD [6]是最早使用金字塔特征层次表示的方法之一,它通过不同空间大小的网络捕获多尺度特征信息,从而提高模型识别精度。FPN [17]在层次上主要依赖于自下而上的网络内特征金字塔,该金字塔从多尺度高级语义特征映射中构建具有横向连接的自上而下的路径。在此基础上,PANet [16]进一步提出了一种基于FPN的额外的自底向上路径,以在层间特征之间共享特征信息,使得高层特征也可以在低层特征中获得足够的细节。在神经架构搜索的帮助下,NAS-FPN [13]使用空间搜索策略通过特征金字塔连接各层,并获得可扩展的特征信息。M2 Det [37]通过构建多级特征金字塔来提取多级、多尺度特征,实现跨层次、跨层特征融合。一般来说,1)特征金字塔可以在不增加计算开销的情况下处理对象识别中的多尺度变化问题; 2)提取的特征可以生成包括一些高分辨率特征的多尺度特征表示。在这项工作中,我们提出了一个层内的特征调节的角度,层间的特征相互作用和层内的特征规则的特征金字塔,这弥补了目前的方法在这方面的不足。
B. Visual Attention Learning
B。视觉注意学习
CNN [38] focuses more on the representative learning of local regions. However, this local representation does not satisfy the requirement for global context and long-term dependencies of the modern recognition systems. To this end, the attention learning mechanism [20] is proposed that focuses on deciding where to project more attention in an image. For example, non-local operation [19] uses the non-local neural network to directly capture long-range dependencies, demonstrating the significance of non-local modeling for tasks of video classification, object detection and segmentation. However, the local representation of the internal nature of CNNs is not resolved, i.e., CNN features can only capture limited contextual information. To address this problem, Transformer [20] which mainly benefits from the multi-head attention mechanism has caused a great sensation recently and achieved great success in the field of computer vision, such as image recognition [24], [39], [23], [40], [25]. For example, the representative VIT divides the image into a sequence with position encoding, and then uses the cascaded transformer block to extract the parameterized vector as visual representations. On this basis, many excellent models [39], [41], [42] have been proposed through further improvement, and have achieved good performance in various tasks of computer vision. Nevertheless, the transformer-based image recognition models still have disadvantages of being computationally intensive and complex.CNN [38]更关注局部区域的代表性学习。然而,这种局部表示不能满足现代识别系统对全局上下文和长期依赖性的要求。为此,提出了注意力学习机制[20],其重点是决定在图像中何处投射更多注意力。例如,非局部操作[19]使用非局部神经网络直接捕获长程依赖关系,证明了非局部建模对于视频分类,对象检测和分割任务的重要性。然而,CNN内部性质的局部表示没有解决,即,CNN功能只能捕获有限的上下文信息。为了解决这个问题,主要受益于多头注意机制的Transformer [20]最近引起了极大的轰动,并在计算机视觉领域取得了巨大的成功,如图像识别[24],[39],[23],[40],[25]。例如,代表性VIT将图像划分为具有位置编码的序列,然后使用级联的Transformer块来提取参数化向量作为视觉表示。在此基础上,通过进一步改进,提出了许多优秀的模型[39]、[41]、[42],并在计算机视觉的各种任务中取得了良好的性能。然而,基于变换器的图像识别模型仍然具有计算密集和复杂的缺点。
C. MLP in Computer Vision
C.计算机视觉中的MLP
In order to alleviate shortcomings of complex transformer models [43], [44], [23], [45], recent works [46], [47], [48], [49] show that replacing attention-based modules in a transformer model with MLP still performs well. The reason for this phenomenon is that both MLP (e.g., two fully-connected layer network) and attention mechanism are global information processing modules. On the one hand, the introduction of the MLP-Mixer [46] into the vision alleviates changes to the data layout. On the other hand, MLP-Mixer can better establish the long dependence/global relationship and spatial relationship of features through the interaction between spatial feature information and channel feature information. Although MLPstyle models perform well in computer vision tasks, they are still lacking in capturing fine-grained feature representations and obtaining higher recognition accuracy in object detection. Nevertheless, MLP is playing an increasingly important role in the field of computer vision, and has the advantage of a simpler network structure than transformer. In our work, we also use MLP to capture the global contextual information and longterm dependencies of the input images. Our contribution lies in the centrality of the grasped information using the proposed spatial explicit visual center scheme.为了减轻复杂Transformer模型的缺点[43],[44],[23],[45],最近的工作[46],[47],[48],[49]表明,用MLP替换Transformer模型中基于注意力的模块仍然表现良好。这种现象的原因是MLP(例如,两个全连接层网络)和注意机制是全局信息处理模块。一方面,将MLP-混合器[46]引入到视觉中会对数据布局进行更改。另一方面,MLP-Mixer通过空间特征信息和通道特征信息的交互,可以更好地建立特征的长依赖/全局关系和空间关系。虽然MLP风格的模型在计算机视觉任务中表现良好,但它们仍然缺乏捕获细粒度的特征表示和在目标检测中获得更高的识别精度。尽管如此,MLP在计算机视觉领域发挥着越来越重要的作用,并且具有比Transformer更简单的网络结构的优点。在我们的工作中,我们还使用MLP来捕获输入图像的全局上下文信息和长期依赖关系。我们的贡献在于使用建议的空间显式视觉中心计划掌握的信息的中心性。
D. Object Detection
D.目标检测
Object detection is a fundamental computer vision task, which aimes to recognize objects or instances of interest for the given image and provide a comprehensive scene description including the object category and location. With the unprecedented development of CNN [38] in the recent years, plenty of object detection models achieve remarkable progress. The existing methods can be divided into two types of two-stage and single-stage. Two-stage object detectors [50], [4], [5], [51], [52] usually first use a RPN to generate a collection of region proposals. Then use a learning module to extract region features of these region proposals and complete the classification and regression process. However, storing and repetitively extracting the features of each region proposal is not only computationally expensive, but also makes it impossible to capture the global feature representations. To this end, the single-stage detectors [7], [6], [53], [54] directly perform prediction and region classification by generating bounding boxes. The existing single-stage methods have a global concept in the design of feature extraction, and use the backbone network to extract feature maps of the entire image to predict each bounding box. In this paper, we also choose the single-stage object detectors (i.e., YOLOv5 [35] and YOLOX [36]) as our baseline models. Our focus is to enhance the representation of the feature pyramid used for these detectors.目标检测是计算机视觉的一项基本任务,其目的是识别给定图像中感兴趣的目标或实例,并提供包括目标类别和位置的全面场景描述。近年来,随着CNN的空前发展[38],许多目标检测模型取得了显著进展。现有的方法可以分为两阶段和单阶段两类。两阶段对象检测器[50],[4],[5],[51],[52]通常首先使用RPN来生成区域建议的集合。然后利用一个学习模块对这些区域建议进行区域特征提取,完成分类和回归过程。然而,存储和重复提取每个区域建议的特征不仅在计算上是昂贵的,而且使得不可能捕获全局特征表示。为此,单级检测器[7],[6],[53],[54]通过生成边界框直接执行预测和区域分类。现有的单阶段方法在特征提取的设计上具有全局概念,利用骨干网络提取整幅图像的特征图来预测每个包围盒。在本文中,我们还选择了单级目标检测器(即,YOLOv5 [35]和YOLOX [36])作为我们的基线模型。我们的重点是提高用于这些检测器的特征金字塔的表示。
III. OUR APPROACH
In this section, we introduce the implementation details of the proposed centralized feature pyramid (CFP). We first make an overview architecture description for CFP in Section III-A. Then, we show the implementation details of the explicit visual center in Section III-B. Finally, we show how to implement the explicit visual center on an image feature pyramid and propose our global centralized regulation in Section III-C.在本节中,我们将介绍所提出的集中式特征金字塔(CFP)的实现细节。我们首先在第III-A节中对CFP的体系结构进行概述。然后,我们在第三节B中展示了显式视觉中心的实现细节。最后,我们展示了如何在图像特征金字塔上实现显式视觉中心,并在第III-C节中提出了我们的全局集中式规则。
A. Centralized Feature Pyramid (CFP)
A.集中式特征金字塔(CFP)
Although the existing methods have been largely concentrated on the inter-layer feature interactions, they ignore the intra-layer feature regulations, which have been empirically proved beneficial to the vision recognition tasks. In our work, inspired by the previous works on dense prediction tasks [55], [48], [46], we propose a CFP for object detection, which is based on the globally explicit centralized intra-layer feature regulation. Compared to the existing feature pyramids, our proposed CFP not only can capture the global long-range dependencies, but also enable comprehensive and differentiated feature representations. As illustrated in Figure 2, CFP mainly consists of the following parts: the input image, a CNN backbone is used to extract the vision feature pyramid, the proposed Explicit Visual Center (EVC), the proposed Global Centralized Regulation (GCR), and a decoupled head network (which consists of a classification loss, a regression loss and a segmentation loss) for object detection. In Figure 2, EVC and GCR are implemented on the extracted feature pyramid.虽然现有的方法已经在很大程度上集中在层间特征的相互作用,他们忽略了层内的特征规则,这已被经验证明是有益的视觉识别任务。在我们的工作中,受到以前关于密集预测任务的工作的启发[55],[48],[46],我们提出了一种用于对象检测的CFP,该CFP基于全局显式集中式层内特征调节。与现有的特征金字塔相比,我们提出的CFP不仅可以捕获全局的长程依赖关系,而且还可以实现全面和差异化的特征表示。如图2所示,CFP主要由以下部分组成:输入图像,CNN主干用于提取视觉特征金字塔,提出的显式视觉中心(EVC),提出的全局集中调节(GCR)和用于对象检测的解耦头网络(由分类损失,回归损失和分割损失组成)。在图2中,EVC和GCR在提取的特征金字塔上实现。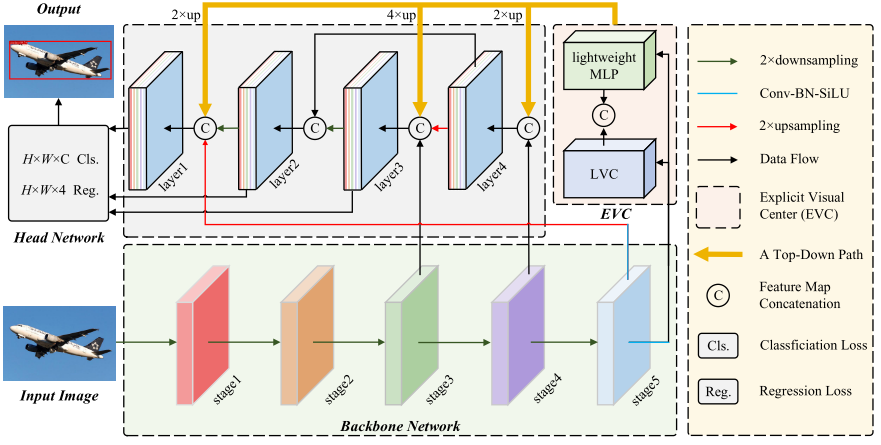
Fig. 2. An illustration of the overall architecture, which mainly consists of four components: input image, a backbone network for feature extraction, the centralized feature pyramid which is based on a commonly-used vision feature pyramid following [36], and the object detection head network which includes a classification (i.e., Cls.) loss and a regression (i.e., Reg.) loss. C denotes the class size of the used dataset. Our contribution lines in that we propose an intra-layer feature regulation method in a feature pyramid, and a top-to-down global centralized regulation.
图二.总体架构的说明,主要由四个组件组成:输入图像,用于特征提取的骨干网络,基于常用视觉特征金字塔的集中式特征金字塔[36],以及包括分类(即,Cls.)损失和回归(即,Reg.)损失C表示所用数据集的类大小。我们的贡献在于,我们提出了一个层内的特征调节方法在一个特征金字塔,和一个自顶向下的全球集中式监管。
Concretely, we first feed the input image into the backbone network (i.e., the Modified CSP v5 [56]) to extract a five-level one feature pyramid X, where the spatial size of each layer of features Xi (i = 0, 1, 2, 3, 4) is 1/2, 1/4, 1/8, 1/16, 1/32 of the input image, respectively. Based on this feature pyramid, our CFP is implemented. A lightweight MLP architecture is proposed to capture the global long-range dependencies of X4, where the multi-head self-attention module of a standard transformer encoder is replaced by a MLP layer. Compared to the transformer encoder based on the multi-head attention mechanism, our lightweight MLP architecture is not only simple in structure but also has a lighter volume and higher computational efficiency (cf. Section III-B). Besides, a learnable visual center mechanism, along with the lightweight MLP, is used to aggregate the local corner regions of the input image. We name the above parallel structure network as the spatial EVC, which is implemented on the top layer (i.e., X4) of the feature pyramid. Based on the proposed ECV, to enable the shallow layer features of the feature pyramid to benefit from the visual centralized information of the deepest feature at the same time in an efficient pattern, we then propose a GCR in a top-down fashion, where the explicit visual center information obtained from the deepest intra-layer feature is used to regulate all the frontal shallow features (i.e., X3 to X2) simultaneously. Finally, we aggregate these features into a decoupled head network for classification and regression.具体地,我们首先将输入图像馈送到骨干网络(即,修改的CSP v5 [56])以提取五级一特征金字塔X,其中特征Xi(i = 0,1,2,3,4)的每一层的空间大小分别是输入图像的1/2,1/4,1/8,1/16,1/32。基于此特征金字塔,我们的CFP实现。提出了一种轻量级的MLP架构来捕获X4的全局长程依赖,其中标准Transformer编码器的多头自注意模块被MLP层取代。与基于多头注意机制的Transformer编码器相比,我们的轻量级MLP架构不仅结构简单,而且具有更轻的体积和更高的计算效率(参见图1)。第III-B节)。此外,一个可学习的视觉中心机制,沿着的轻量级MLP,被用来聚合的输入图像的局部角区域。我们将上述并行结构网络命名为空间EVC,其在顶层(即,X4)的特征金字塔。基于所提出的ECV,为了使特征金字塔的浅层特征能够以有效的模式同时受益于最深特征的视觉集中信息,我们然后以自顶向下的方式提出了GCR,其中从最深层内特征获得的显式视觉中心信息用于调节所有前部浅层特征(即,X3到X2)同时进行。最后,我们将这些特征聚合到一个解耦的头部网络中进行分类和回归。
B. Explicit Visual Center (EVC)
B。外显视觉中心(EVC)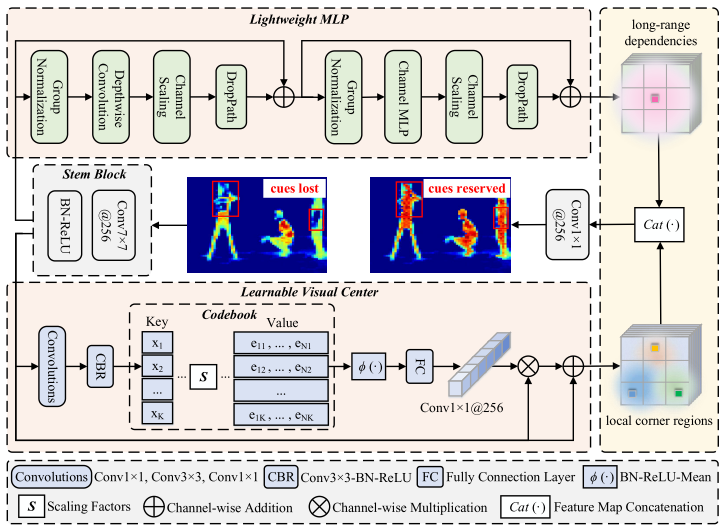
Fig. 3. An illustration of the proposed explicit visual center, where a lightweight MLP architecture is used to capture the long-range dependencies and a parallel learnable visual center mechanism is used to aggregate the local corner regions of the input image. The integrated features contain advantages of these two blocks, so that the detection model can learn an all-round yet discriminative feature representation.
图三.所提出的显式视觉中心的说明,其中一个轻量级的MLP架构被用来捕获的长程依赖关系和一个并行的可学习的视觉中心机制被用来聚合输入图像的局部角区域。集成的特征包含了这两个块的优点,使得检测模型可以学习全面而有区别的特征表示。
As illustrated in Figure 3, our proposed EVC mainly consists of two blocks connected in parallel, where a lightweight MLP is used to capture the global long-range dependencies (i.e., the global information) of the top-level features $X_4$. At the same time, to reserve the local corner regions (i.e., the local information), we propose a learnable vision center mechanism is implemented on $X_4$ to aggregate the intra-layer local regional features. The result feature maps of these two blocks are concatenate together along the channel dimension as the output of EVC for the downstream recognition. In our implementation, between $X_4$ and EVC, a Stem block is used for features smoothing instead of implementing directly on the original feature maps as in [35]. The Stem block consists of a 7 × 7 convolution with the output channel size of 256, followed by a batch normalization layer, and an activation function layer. The above processes can be formulated as:如图3所示,所提出的EVC主要由并行连接的两个块组成,其中一个轻量级的MLP用于捕获顶级特征$X_4$的全局长程依赖关系(即全局信息)。。同时,为了保留局部角区域(即,局部信息),我们提出了一种可学习的视觉中心机制,在$X_4$上实现,以聚合层内局部区域特征。这两个块的结果特征图沿着通道维度连接在一起,作为下游识别的EVC的输出。在我们的实现中,在$X_4$和EVC之间,Stem块用于特征平滑,而不是像[35]中那样直接在原始特征图上实现。Stem块由一个输出通道大小为256的7 × 7卷积组成,后面是一个批量归一化层和一个激活函数层。上述过程可表述为: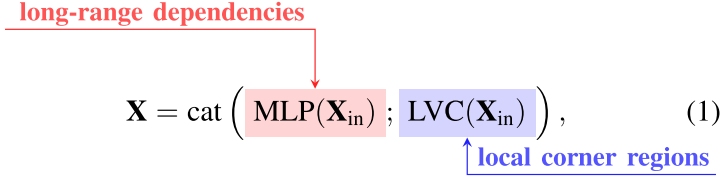
long-range dependencies
远程依赖关系
local corner regions局部角点区域
where X is the output of EVC. cat(·) denotes the feature map concatenation along the channel dimension. MLP($X_{in}$) and LVC($X_{in}$) denotes the output features of the used lightweight MLP and the learnable visual center mechanism, respectively. $X_{in}$ is the output of the Stem block, which is obtained by:其中X是EVC. cat(·)的输出,表示沿通道维度的特征图连接沿着。MLP($X_{in}$)和LVC($X_{in}$)分别表示所使用的轻量级MLP和可学习视觉中心机制的输出特征。$X_{in}$是Stem块的输出,通过以下方式获得: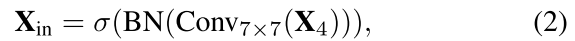
where $Conv_{7×7}(·)$ denotes a 7 × 7 convolution with stride 1 and the channel size is set to 256 in our work following [17]. BN(·) denotes a batch normalization layer and σ(·) denotes the ReLU activation function.其中$Conv_{7×7}(·)$表示步长为1的7 × 7卷积,在我们的工作中,通道大小设置为256 [17]。BN(·)表示批量归一化层,σ(·)表示ReLU激活函数。
MLP.
The used lightweight MLP mainly consists of two residual modules: a depthwise convolution-based module [57] and a channel MLP-based block, where the input of the MLPbased module is the output of the depthwise convolutionbased [46] module. These two blocks are both followed by a channel scaling operation [48] and DropPath operation [58] to improve the feature generalization and robustness ability. Specifically, for the depthwise convolution-based module, features output from the Stem module $X_{in}$ are first fed into a depthwise convolution layer, which have been processed by a group normalization (i.e., feature maps are grouped along the channel dimension). Compared to traditional spatial convolution, depthwise convolution can increase the feature representation ability while reducing the computational costs. Then, channel scaling and droppath are implemented. After that, a residual connection of $X_{in}$ is implemented. The above processes can be formulated as:所使用的轻量级MLP主要由两个残差模块组成:基于depth卷积的模块[57]和基于通道MLP的块,其中基于MLP的模块的输入是基于depth卷积的模块的输出[46]。这两个块后面都是通道缩放操作[48]和DropPath操作[58],以提高特征泛化和鲁棒性能力。具体地,对于基于去卷积的模块,从Stem模块$X_{in}$输出的特征首先被馈送到去卷积层,其已经通过组归一化(即,特征图被沿着通道维度分组)。与传统的空间卷积相比,深度卷积可以在提高特征表示能力的同时降低计算代价。然后,实现了通道缩放和丢弃路径。在此之后,执行$X_{in}$的剩余连接。上述过程可表述为: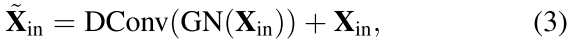
where $\check{\mathbf{X}}{\text {in }}$ is the output of the depthwise convolution-based module. GN(·) is the group normalization and DConv(·) is a depthwise convolution [57] with the kernel size of 1 × 1.其中,$\check{\mathbf{X}}{\text {in }}$是基于深度卷积的模块的输出。GN(·)是组归一化,DConv(·)是一个深度卷积[57],核大小为1 × 1。
For the channel MLP-based module, features output from the depthwise convolution-based module $\check{\mathbf{X}}{\text {in }}$ are first fed to the a group normalization, and then the channel MLP [46] is implemented on these features. Compared to space MLP, channel MLP can not only effectively reduce the computational complexity but also meet the requirements of general vision tasks [36], [54]. After that, channel scaling, droppath, and a residual connection of $\check{\mathbf{X}}{\text {in }}$ are implemented in sequence. The above processes are expressed as:对于基于通道MLP的模块,首先将从基于depth卷积的模块$\check{\mathbf{X}}{\text {in }}$输出的特征馈送到a组归一化,然后在这些特征上实现通道MLP [46]。与空间MLP相比,通道MLP不仅可以有效降低计算复杂度,而且可以满足一般视觉任务的要求[36],[54]。然后,依次实现了通道缩放、droppath和一个剩余的$\check{\mathbf{X}}{\text {in }}$连接。上述过程表示为: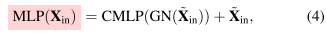
where CMLP(·) is the channel MLP [46]. In our paper, for the presentation convenience, we omit channel scaling and droppath in Eq. 3 and Eq. 4.其中CMLP(·)为通道MLP[46]。在我们的论文中,为了演示方便,我们省略了方程3和方程4中的通道缩放和下降路径。
LVC.
LVC is an encoder with an inherent dictionary and has two components: 1) an inherent codebook: B = {b1, b2, . . . , bK}, where N = H × W is the total spatial number of the input features, where H and W denotes the feature map spatial size in height and width, respectively; 2) a set of scaling factors S = {s1, s2, . . . , sK} for the learnable visual centers. Specifically, features from the Stem block $X_{in}$ are first encoded by a combination of a set of convolution layers (which consist of a 1 × 1 convolution, a 3×3 convolution, and a 1×1 convolution). Then, the encoded features are processed by a CBR block, which consists of a 3 × 3 convolution with a BN layer and a ReLU activation function. Through the above steps, the encoded features $\check{\mathbf{X}}{\text {in }}$ are entered into the codebook. To this end, we use a set of scaling factor s to sequentially make $\check{\mathbf{x}}{\text {in }}$ and $b_k$ map the corresponding position information. The information of the whole image with respect to the k-th codeword can be calculated by:LVC是具有固有字典的编码器,并且具有两个组件:1)固有码本:B = {b1,b2,...,bK},其中N = H × W是输入特征的总空间数量,其中H和W分别表示特征图在高度和宽度上的空间大小; 2)缩放因子集合S = {s1,s2,...,sK}的可学习视觉中心。具体来说,来自Stem块$\check{\mathbf{X}}{\text {in }}$的特征首先通过一组卷积层的组合(由1 × 1卷积、3×3卷积和1×1卷积组成)进行编码。然后,编码的特征由CBR块处理,该CBR块由BN层和ReLU激活函数的3 × 3卷积组成。通过上述步骤,编码特征Xin被输入到码本中。为此,我们使用一组缩放因子s来顺序地使$\check{\mathbf{x}}{\text {in }}$和$b_k$映射相应的位置信息。关于第k个码字的整个图像的信息可以通过下式计算: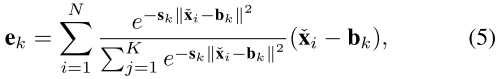
where $\check{\mathbf{x}}{\text {i}}$ is i-th pixel point, $b_k$ is k-th learnable visual codeword, and $s_k$ is k-th scaling factor. $\check{\mathbf{x}}{\text {i}}$− $b_k$ is the information about each pixel position relative to a codeword. K is the total number of visual centers. After that, we use φ to fuse all $e_k$, where φ contains BN layer with ReLU and mean layer. Based on which, the full information of the whole image with respect to the K codewords is calculated as follows.其中,$\check{\mathbf{x}}{\text {i}}$是第i个像素点,$b_k$是第k个可学习视觉码字,sk是第k个缩放因子。$\check{\mathbf{x}}{\text {i}}$-$b_k$是关于相对于码字的每个像素位置的信息。K是视觉中心的总数。之后,我们使用φ来融合所有$e_k$,其中φ包含BN层与ReLU和平均层。基于此,整个图像关于K个码字的全部信息被计算如下。
After obtaining the output of the codebook, we further feed e into a fully connection layer and a 1 × 1 convolution layer to predict features that highlight key classes. After that, we use the channel-wise multiplication between the input features from Stem block $X_{in}$ and the scaling factor coefficient δ(·). The above processes are expressed as:在获得码本的输出后,我们进一步将e馈送到全连接层和1 × 1卷积层,以预测突出关键类的特征。之后,我们使用来自Stem块$X_in$的输入特征与缩放因子系数δ(·)之间的通道乘法。上述过程表示为: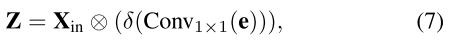
where $Conv_{1×1}$ denotes the 1×1 convolution, and δ(·) is the sigmoid function. ⊗ is channel-wise multiplication. Finally, we perform a channel-wise addition between features $X_{in}$ output from the Stem block and the local corner region features Z, which is formulated as:其中$Conv_{1×1}$表示1×1卷积,δ(·)是sigmoid函数。是通道式乘法。最后,我们在从Stem块输出的特征$X_{in}$和局部角区域特征Z之间执行通道加法,其公式为: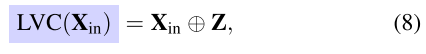
where ⊕ is the channel-wise addition.其中,⊕是通道方向加法。
C. Global Centralized Regulation (GCR)
C.全球集中监管(GCR)
EVC is a generalized intra-layer feature regulation method that can not only extract global long-range dependencies but also preserve the local corner regional information of the input image as much as possible, which is very important for dense prediction tasks. However, using EVC at every level of the feature pyramid would result in a large computational overheads. To improve the computational efficiency of intra-layer feature regulation, we further propose a GCR for a feature pyramid in a top-down manner. Specifically, as illustrated in Figure 2, considering the fact that the deepest features usually contain the most abstract feature representations scarce in the shallow features [33], [59], our spatial EVC is first implemented on the top layer (i.e., $X_4$) of the feature pyramid. Then, the obtained features X which includes the spatial explicit visual center is used to regulate all the frontal shallow features (i.e., $X_3$ to $X_2$) simultaneously. In our implementation, on each corresponding low-level features, the features obtained in the deep layer are upsampled to the same spatial scale as the low-level features and then are concatenated along the channel dimension. Based on which, the concatenated features are downsampled by a 1×1 convolution into the channel size of 256 as [17]. In this way, we are able to explicitly increase the spatial weight of the global representations at each layer of the feature pyramid in the top-down path, such that our CFP can effectively achieve an all-round yet discriminative feature representation.EVC是一种广义的层内特征调整方法,不仅能提取全局长程依赖关系,而且能尽可能保留输入图像的局部角点区域信息,这对于密集预测任务非常重要。然而,在特征金字塔的每一层使用EVC将导致较大的计算开销。为了提高层内特征调整的计算效率,我们进一步提出了一种自顶向下的特征金字塔的GCR。具体来说,如图2所示,考虑到最深的特征通常包含浅层特征中稀缺的最抽象的特征表示[33],[59],我们的空间EVC首先在顶层实现(即,$X_4$)的特征金字塔。然后,使用所获得的包括空间显式视觉中心的特征X来调节所有的前浅特征(即,$X_3$到$X_2$)同时进行。在我们的实现中,在每个对应的低级别特征上,在深层中获得的特征被上采样到与低级别特征相同的空间尺度,然后沿通道维度沿着连接。在此基础上,通过1×1卷积将级联特征下采样为256的通道大小[17]。通过这种方式,我们能够显式地增加自顶向下路径中特征金字塔每一层的全局表示的空间权重,使得我们的CFP可以有效地实现全面而有区别的特征表示。
Fig. 2. An illustration of the overall architecture, which mainly consists of four components: input image, a backbone network for feature extraction, the centralized feature pyramid which is based on a commonly-used vision feature pyramid following [36], and the object detection head network which includes a classification (i.e., Cls.) loss and a regression (i.e., Reg.) loss. C denotes the class size of the used dataset. Our contribution lines in that we propose an intra-layer feature regulation method in a feature pyramid, and a top-to-down global centralized regulation.
图二.总体架构的说明,主要由四个组件组成:输入图像,用于特征提取的骨干网络,基于常用视觉特征金字塔的集中式特征金字塔[36],以及包括分类(即,Cls.)损失和回归(即,Reg.)损失C表示所用数据集的类大小。我们的贡献在于,我们提出了一个层内的特征调节方法在一个特征金字塔,和一个自顶向下的全球集中式监管。
IV. EXPERIMENTS
A. Dataset and Evaluation Metrics
A.数据集和评估
Dataset.
In this work, Microsoft Common Objects in Context (MS-COCO) [34] is used to validate the superiority of our proposed CFP. MS-COCO contains 80 classes of the common scene objects, where the training set, val set and test set contains 118k, 5k and 20k images, respectively. In our experiments, for a fair comparison, all the training images are resized into a fix size of 640 × 640 as in [17]. For data augmentation, we adopt the commonly used Mosaic [54] and MixUp [60] in our experiments. Mosaic can not only enrich the image data, but also indirectly increase our batch size. MixUp can play a role in increasing the model generalization ability. In particular, following [36], our model turns the data augmentation strategy off at the last 15 epochs in training.在这项工作中,Microsoft Common Objects in Context(MS-COCO)[34]用于验证我们提出的CFP的优越性。MS-COCO包含80类常见场景对象,其中训练集、瓦尔集和测试集分别包含118 k、5 k和20 k幅图像。在我们的实验中,为了公平比较,所有训练图像都被调整为640 × 640的固定大小,如[17]所示。对于数据增强,我们在实验中采用常用的Mosaic [54]和MixUp [60]。拼接不仅可以丰富图像数据,还可以间接增加我们的批量。MixUp可以在增加模型泛化能力方面发挥作用。特别是,在[36]之后,我们的模型在训练的最后15个时期关闭了数据增强策略。
Evaluation metrics.
We mainly follow the commonly used object detection evaluation metric – Average Precision (AP) in our experiments, which including AP50, AP75, APS, APM and APL. Besides, to quantitative the model efficiency, GFLOPs, Frame Per Second (FPS), Latency and parameters (Params.) are also used. In particular, following [36], Latency and FPS are measured without post-processing for the fair comparison.在实验中我们主要遵循了常用的目标检测评价指标--平均精度(AP),包括AP 50、AP 75、APS、APM和APL。此外,为了量化模型的效率,GFLOPs,帧每秒(FPS),延迟和参数(Params。)也被使用。特别是,在[36]之后,延迟和FPS在没有后处理的情况下进行测量,以进行公平比较。
B. Implementation Details
B.实现细节
Baselines.基线
To validate the generality of CFP, we use two state-of-the-art baseline models in our experiments, which are YOLOv5 [35] and YOLOX [36]. In our experiments, we use the end-to-end training strategy and employ their default training and inference settings unless otherwise stated.为了验证CFP的通用性,我们在实验中使用了两种最先进的基线模型,即YOLOv5 [35]和YOLOX [36]。在我们的实验中,我们使用端到端的训练策略,并使用它们的默认训练和推理设置,除非另有说明。
- YOLOv5 [35]. The backbone is a modified cross stage partial network v5 [56] and DarkNet53 [53], where the modified cross stage partial network v5 is used in the ablation study and the DarkNet53 is used in result comparisons with the state-of-the-art. The neck network is FPN [17]. The object detection head is the coupled head network, which contains a classification branch and a regression branch. In YOLOv5, according to the scaling of network depth and width, three different scale networks are generated, they are YOLOv5-Small (YOLOv5S), YOLOv5-Media (YOLOv5-M), and YOLOv5-Large (YOLOv5-L).
YOLOv 5 [35].主干是改良的跨阶段部分网络v5 [56]和DarkNet 53 [53],其中改良的跨阶段部分网络v5用于消融研究,DarkNet 53用于与最新技术水平的结果比较。颈部网络是FPN [17]。目标检测头为耦合头网络,包含分类分支和回归分支。在YOLOv 5中,根据网络深度和宽度的缩放,生成三种不同规模的网络,它们是YOLOv 5-Small(YOLOv 5S),YOLOv 5-Media(YOLOv 5-M)和YOLOv 5-Large(YOLOv 5-L)。 - YOLOX [36]. Compared to YOLOv5, the whole network structure of YOLOX remains unchanged except for the coupled head network. In YOLOv5, object detection head is the decoupled head network.
YOLOX [36].与YOLOv5相比,YOLOX的整个网络结构保持不变,除了耦合头网络。在YOLOv5中,目标检测头是解耦的头网络。
Backbone.骨干
In our experiments, two backbones are used.在我们的实验中,使用了两个主链。
DarkNet53 [53]. DarkNet53 mainly consists of 53 convolutional layers (basically 1 × 1 with 3 × 3 convolutions), which is mainly used for the performance comparisons with state-of-the-art methods in Table VII.
DarkNet53[53]。DarkNet53主要由53个卷积层组成(基本为1 × 1和3 × 3卷积),主要用于与表VII中的先进方法进行性能对比。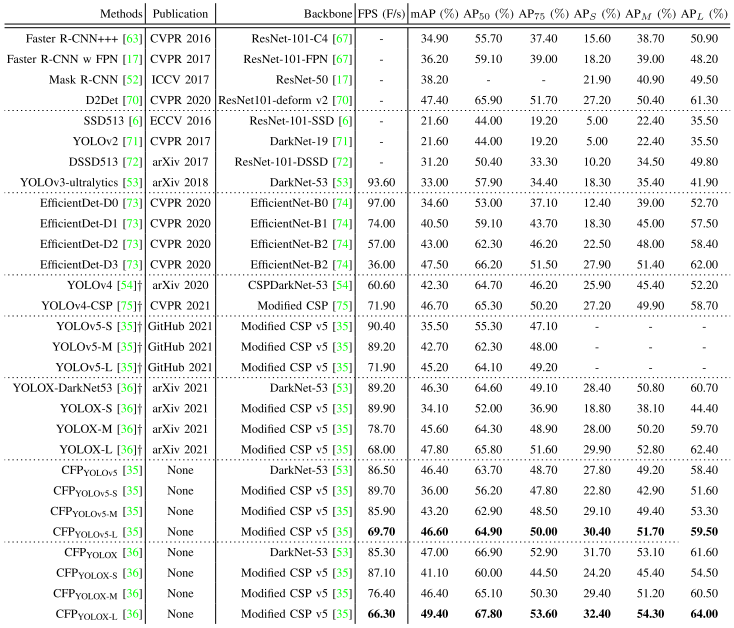
TABLE VII COMPARISON OF THE SPEED AND ACCURACY OF DIFFERENT OBJECT DETECTORS ON MS-COCO val SET. WE SELECT ALL THE MODELS TRAINED ON 150 EPOCHS FOR FAIR COMPARISON. . ”+” IS OUR RE-IMPLEMENTATION RESULT.
表VII MS-COCO瓦尔SET上不同物体探测器的速度和准确度比较。我们选择所有在150个时期上训练的模型进行公平比较。.“+”是我们重新实施的结果。Modified CSPNet v5 [35]. For a fair comparison, we choose YOLOv5 (i.e., the Modified CSPNet v5) as our backbone network. The output feature maps is the ones from stage5, which consists of three convolution (Conv, BN and SiLU [61]) operations and a spatial pyramid pooling [62] layer (5 × 5, 9 × 9 and 13 × 13).
修改CSPNet v5 [35]。为了公平比较,我们选择YOLOv5(即,修改后的CSPNet v5)作为我们的骨干网络。输出的特征图来自第5阶段,由三个卷积(Conv,BN和SiLU [61])操作和空间金字塔池化[62]层(5 × 5,9 × 9和13 × 13)组成。
Comparison methods.比较方法。
We consider the use of MLP instead of attention-based, which not only performs well but is computationally less expensive. Therefore, we design a series of MLPs and attention-based variants. Through the ablation study, we choose an optimal variant for our LVC mechanism as well as CFP approach, called lightweight MLP.我们考虑使用MLP而不是基于注意力的,这不仅表现良好,但计算成本较低。因此,我们设计了一系列MLP和基于注意力的变体。通过消融研究,我们为我们的LVC机制以及CFP方法选择了一个最佳变体,称为轻量级MLP。
Figure 4 (a) shows the PoolFormer structure [48], which consists of a Pooling operation sub-block and a two-layered MLP sub-block. Considering that the Pooling operation corrupts the detailed features, we choose some convolutions that are structurally lightweight and guarantee accuracy at the same time. Therefore, we designate CPSLayer [56] as well as depthwise convolution as token mixers. They are called CSPM and MLP (Ours) in (c) and (e) of Figure 4 respectively. Compared with MLP variants, the structures (b), (d) and (f) are corresponding attention-based variants, respectively. It is worth noting that we choose the channel MLP in the MLP variants. Then, we use convolutional position encoding to prevent absolute position encoding from causing translational invariance of the module.图4(a)显示了PoolFormer结构[48],它由一个Pooling操作子块和一个双层MLP子块组成。考虑到Pooling操作破坏了细节特征,我们选择了一些结构上轻量级的卷积,同时保证了准确性。因此,我们将CPSLayer [56]以及dependency卷积指定为令牌混合器。它们分别在图4的(c)和(e)中被称为CSPM和MLP(我们的)。与MLP变体相比,结构(B)、(d)和(f)分别是相应的基于注意力的变体。值得注意的是,我们在MLP变体中选择通道MLP。然后,我们使用卷积位置编码来防止绝对位置编码导致模块的平移不变性。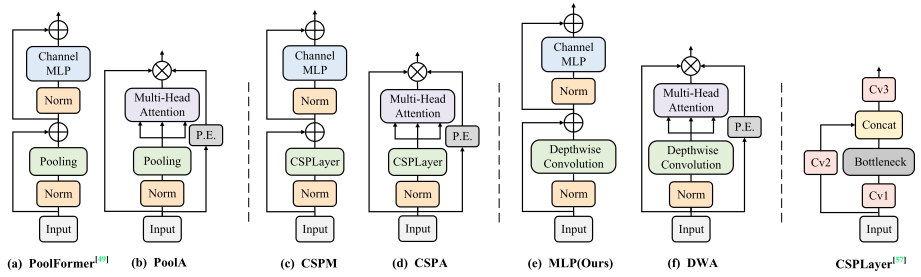
Fig. 4. MLP and attention-based variants structure diagram. (a) is the PoolFormer structure in [48]. (c) and (e) imitate PoolFormer structure and replace Pooling layer with CPSLayer [56] and Depthwise Convolution as token mixers respectively. Moreover, (b), (d) and (f) structures replace the channel MLP module with an attention-based module in transformer. Norm denotes the normalization. ⊕ represents channel-wise addition operation and ⊗ represents channel-wise multiplication operation. P.E. represents positional encoding.
见图4。MLP和基于注意力的变体结构图。(a)是[48]中的PoolFormer结构。(c)以及(e)模仿PoolFormer结构,并分别用CPSLayer [56]和Depressive Convolution代替Pooling层作为令牌混合器。此外,(B)、(d)和(f)结构用Transformer中的基于注意力的模块替换通道MLP模块。Norm表示标准化。表示逐通道加法运算,并且表示逐通道乘法运算。体育表示位置编码。
Training settings.培训设置。
We first train our CFP on MS-COCO using pre-trained weights from the YOLOX or YOLOv5 backbone, where all other training parameters are similar in all models. Considering the local hardware condition, our model is trained for a total of 150 epochs, including 5 epochs for learning rate warmup as in [63]. We use 2 GeForce RTX 3090 GPUs with the Batch Size of 16. Our training settings remain largely consistent from the bas for a total of 150 epochs, including 5 epochs for learning rate warmup as in [63]. We use 2 GeForce RTX 3090 GPUs with the Batch Size of 16. Our training settings remain largely consistent from the baseline to final model. The input image training size is 640 × 640. The learning rate is set to lr × BatchSize / 64 (i.e., the linear scaling strategy [64]), where the initial learning rate is set to lr = 0.01 and the cosine lr schedule is used. The weight decay is set to 0.0005. The optimizer for the model training process selects stochastic gradient descent, where the momentum is set to 0.9. Besides, following [17], we evaluate the AP every 10 training epochs and report the best one on the MS-COCO val set.我们首先使用来自YOLOX或YOLOv 5主干的预训练权重在MS-COCO上训练CFP,其中所有其他训练参数在所有模型中都是相似的。考虑到本地硬件条件,我们的模型总共训练了150个epoch,包括5个epoch用于学习率预热,如[63]所示。我们使用2个GeForce RTX 3090 GPU,批量大小为16。我们的训练设置在很大程度上与bas保持一致,总共150个epoch,包括5个epoch用于学习率预热[63]。我们使用2个GeForce RTX 3090 GPU,批量大小为16。我们的训练设置从基线到最终模型基本保持一致。输入图像训练大小为640 × 640。学习速率被设置为lr × BatchSize / 64(即,线性缩放策略[64]),其中初始学习速率被设置为LR = 0.01,并且使用余弦LR调度。权重衰减设置为0.0005。模型训练过程的优化器选择随机梯度下降,其中动量设置为0.9。此外,在[17]之后,我们每10个训练期评估AP,并报告MS-COCO值集上的最佳AP。
Inference settings.
For the inference of our model, the original image is scaled to the object size (640 × 640) and the rest of the image is filled with gray. Then, we feed the image into the trained model for detection. In the inference that FPS and Latency are all measured with FP16-precision and batch = 1 on a single GeForce RTX 3090. However, keep in mind that the inference speed of the models is often uncontrolled, as speed varies with software and hardware.对于我们模型的推断,原始图像被缩放到对象大小(640 × 640),图像的其余部分用灰色填充。然后,我们将图像输入到训练好的模型中进行检测。在这一推论中,FPS和延迟都是在单个GeForce RTX 3090上以FP16精度和批次= 1进行测量的。然而,请记住,模型的推理速度通常是不受控制的,因为速度随软件和硬件而变化。
C. Ablation Study
C.消融研究
Our ablation study aims to investigate the effectiveness of LVC, MLP, EVC, and CFP in object detection. To this end, we perform a series of experiments on the MS-COCO val set [34]. From the data in Table I, it can be seen that we analyze the effects of LVC, MLP, and EVC on the average precision, the amount of parameters, computation volume, and Latency using YOLOv5-L and YOLOX-L as the baselines, respectively. A detailed analysis of our proposed MLP variants and attentionbased variants in terms of precision and Latency is presented in Table II, using YOLOX-L as the baseline. Table III shows the effect of the number of visual centers K on the LVC at the YOLOX-L baseline. From the data in Table IV, we can intuitively see the effect of our CFP method on the model with the number of repetitions R at the YOLOX-L baseline.我们的消融研究旨在研究LVC,MLP,EVC和CFP在目标检测中的有效性。为此,我们在MS-COCO瓦尔集上进行了一系列实验[34]。从表I中的数据可以看出,我们分别以YOLOv 5-L和YOLOX-L为基线,分析了LVC、MLP和EVC对平均精度、参数数量、计算量和延迟的影响。我们提出的MLP变体和基于注意力的变体在精确度和延迟方面的详细分析见表II,使用YOLOX-L作为基线。表III显示了视觉中心数量K对YOLOX-L基线时LVC的影响。从表IV中的数据,我们可以直观地看到我们的CFP方法对模型的影响,其中重复次数为YOLOX-L基线。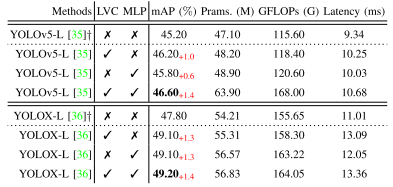
TABLE I RESULTS OF ABLATION STUDY WITH YOLOV5 [35] AND YOLOX-L [36]. ”+” DENOTES THAT THIS IS OUR RE-IMPLEMENTED RESULT.
表I YOLOV 5 [35]和YOLOX-L [36]消融研究结果。“+”表示这是我们重新实现的结果。
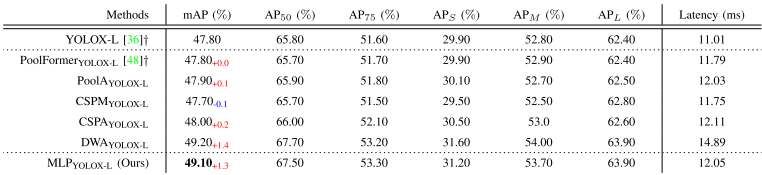
TABLE II RESULT COMPARISONS OF OUR LIGHTWEIGHT MLP(OURS)YOLOX-L WITH THE MLP VARIANTS AND THE SELF-ATTENTION VARIANTS ON THE MS-COCO val SET [34]. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表II我们的轻量级MLP(OURS)YOLOX-L与MS-COCO瓦尔集上的MLP变体和自我注意变体的结果比较[34]。“+”是我们重新实施的结果。
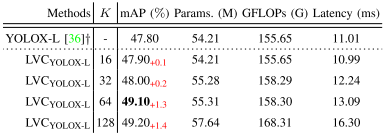
TABLE III EFFECT OF THE NUMBER OF VISUAL CENTERS K ON LVCYOLOX-L. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表III视觉中心数K对LVCYLOX-L的影响。“-”表示没有这样的设置。“+”是我们重新实施的结果。
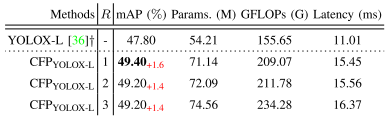
TABLE IV RESULT COMPARISONS OF THE NUMBER OF REPETITIONS OF THE PROPOSED CFP IN THE YOLOX-L BASELINE. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT. R DENOTES THE NUMBER OF REPETITIONS.
表IV YOLOX-L基线中拟定CFP重复次数的结果比较。“-”表示没有这样的设置。“+”是我们重新实施的结果。R表示重复次数。
Effectiveness on different baselines.不同基线的有效性。
As shown in Table I, we perform ablation studies on the MS-COCO val set using YOLOv5-L and YOLOX-L as baselines for the proposed MLP, LVC, and EVC, respectively. As shown in Table I, when we only use LVC mechanism to aggregate local corner region features, and the parameters, computation volume and Latency are all within the acceptable growth range, the mAP of our YOLOv5-L and YOLOX-L models are improved by 1.0% and 1.3%, respectively. Furthermore, when we capture the global long-range dependencies using only the lightweight MLP structure, the mAP of the YOLOv5-L and YOLOX-L models improve by 0.6% and 1.3%, respectively. Most importantly, when we use both LVC and MLP (the EVC scheme) on the YOLOv5-L and YOLOX-L baselines, the mAP of both models are improved by 1.4%. Further analysis shows that when EVC scheme is applied to YOLOv5-L baseline and YOLOXL baseline respectively, mAP of YOLOX-L model can be improved to 49.2%, and its parameter number and computation volume are lower than those of YOLOv5-L model. The results show that the EVC scheme is more effective in YOLOX-L baseline, and the overhead is slightly smaller than that of YOLOv5-L baseline. YOLOX-L is used as the baseline in subsequent ablation experiments.如表I所示,我们分别使用YOLOv 5-L和YOLOX-L作为拟定MLP、LVC和EVC的基线,对MS-COCO瓦尔集进行消融研究。如表I所示,当我们仅使用LVC机制聚合局部角区域特征,并且参数、计算量和Latency都在可接受的增长范围内时,我们的YOLOv 5-L和YOLOX-L模型的mAP分别提高了1.0%和1.3%。此外,当我们仅使用轻量级MLP结构捕获全局长程依赖关系时,YOLOv 5-L和YOLOX-L模型的mAP分别提高了0.6%和1.3%。最重要的是,当我们在YOLOv 5-L和YOLOX-L基线上同时使用LVC和MLP(EVC方案)时,两个模型的mAP都提高了1.4%。进一步分析表明,将EVC格式分别应用于YOLOv 5-L基线和YOLOXL基线,YOLOX-L模型的mAP可提高49.2%,且其参数数和计算量均低于YOLOv 5-L模型。结果表明,EVC方案在YOLOX-L基线上更有效,开销略小于YOLOv 5-L基线。YOLOX-L用作后续消融实验的基线。
TABLE I RESULTS OF ABLATION STUDY WITH YOLOV5 [35] AND YOLOX-L [36]. ”+” DENOTES THAT THIS IS OUR RE-IMPLEMENTED RESULT.
表I YOLOV 5 [35]和YOLOX-L [36]消融研究结果。“+”表示这是我们重新实现的结果。
Comparisons with MLP variants.与MLP变体的比较。
Table II shows the detection performance of MLP and attention-based variants based on YOLOX-L baseline on the MS-COCO val set. We first analyze the comparison results of MLP variants. We can observe that the PoolFormer structure obtains the same mAP (i.e., 47.80%) as YOLOX-L model. The performance of CSPM is even worse compared to the YOLOX-L model, which not only reduces the average precision by 0.1%, but also increases the Latency by 0.74ms. But our proposed lightweight MLP structure obtains the highest mAP (i.e., 49.10%) in the MLP variants, which is 1.3% better than the mAP of YOLOX-L. This also demonstrates that our choice of depthwise convolution as the token mixer in the MLP variant performs better. Turning to the attention-based variants, the performance of PoolA, CSPA and DWA are all improved compared to YOLOX-L, and the mAP of DWA can reach 49.20%. But in fact, we compare the two best performing structures (MLP and DWA) find that the Latency of DWA increases by 2.84ms in the same hardware environment than MLP (Ours). From the comprehensive analysis of the data in Table II, it can be found that our lightweight MLP is not only better but also faster in capturing long-range dependencies.表II显示了在MS-COCO瓦尔集上基于YOLOX-L基线的MLP和基于注意力的变体的检测性能。我们首先分析MLP变体的比较结果。我们可以观察到PoolFormer结构获得相同的mAP(即,47.80%)。与YOLOX-L模型相比,CSPM的性能更差,不仅平均精度降低了0.1%,而且延迟增加了0.74ms。但是我们提出的轻量级MLP结构获得了最高的mAP(即,49.10%),比YOLOX-L的mAP高1.3%。这也证明了我们选择去卷积作为MLP变体中的令牌混合器性能更好。转向基于注意力的变体,与YOLOX-L相比,PoolA,CSPA和DWA的性能都有所提高,DWA的mAP可以达到49.20%。但实际上,我们比较了两种性能最好的结构(MLP和DWA),发现在相同的硬件环境下,DWA的延迟比MLP(Ours)增加了2.84ms。从表II中的数据综合分析可以发现,我们的轻量级MLP在捕获远程依赖关系方面不仅更好,而且更快。
TABLE II RESULT COMPARISONS OF OUR LIGHTWEIGHT MLP(OURS)YOLOX-L WITH THE MLP VARIANTS AND THE SELF-ATTENTION VARIANTS ON THE MS-COCO val SET [34]. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表II我们的轻量级MLP(OURS)YOLOX-L与MS-COCO瓦尔集上的MLP变体和自我注意变体的结果比较[34]。“+”是我们重新实施的结果。
Effect of K.K的影响。
As shown in Table III, we analyze the effect of the number of visual centers K on the performance of LVC. We choose YOLOX-L as the baseline, and with increasing K, we can observe that its performance shows an increasing trend. At the same time, the parameter number, computation volume and the Latency of the model also tend to increase gradually. Notably, when K = 64, the mAP of the model can reach 49.10% and when K = 128, the mAP of the model can reach 49.20%. Although the performance of the model improves by 0.1% as K increases, its extra computational cost increases by 10.01G, and the corresponding inference time increases by 3.21ms. The reason for this may be that too much visual centers bring more redundant semantic information. Not only the performance is not significantly improved, but also the computational effort is increased. So we choose K = 64.如表III所示,我们分析了视觉中心数量K对LVC性能的影响。我们选择YOLOX-L作为基线,随着K的增加,我们可以观察到它的性能表现出增加的趋势。同时,模型的参数数量、计算量和延迟也有逐渐增加的趋势。值得注意的是,当K = 64时,模型的mAP可以达到49.10%,当K = 128时,模型的mAP可以达到49.20%。虽然模型的性能随着K的增加而提高了0.1%,但其额外的计算成本增加了10.01G,相应的推理时间增加了3.21ms。其原因可能是过多的视觉中心会带来更多的冗余语义信息。不仅性能没有显著提高,而且计算量也增加了。所以我们选择K = 64。
TABLE III EFFECT OF THE NUMBER OF VISUAL CENTERS K ON LVCYOLOX-L. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表III视觉中心数K对LVCYLOX-L的影响。“-”表示没有这样的设置。“+”是我们重新实施的结果。
Effect of R
From Table IV, we analyze the effect of the number of repetitions R of CFP on the performance. We still choose the YOLOX-L baseline, and as R increases, we can observe a trend of increasing and then decreasing and then stabilizing the performance compared to the YOLOX-L model. Meanwhile, the number of parameters, computation volume, and the Latency all show a gradual increase. In particular, when R = 1, $CFP_{YOLOX-L}$ achieves the best performance mAP of 49.40%. When R = 2, the performance is instead reduced by 0.2% compared to R = 1. The reason may be that this repeated extraction of features does not capture useful information except for increasing the computational cost. Therefore, based on the above observations, we choose R = 1.从表IV中,我们分析了CFP的重复次数R对性能的影响。我们仍然选择YOLOX-L基线,随着R的增加,我们可以观察到与YOLOX-L模型相比,性能先增加后减少,然后稳定的趋势。同时,参数数量、计算量和延迟都呈现逐渐增加的趋势。特别地,当R = 1时,$CFP_{YOLOX-L}$实现最佳性能mAP 49.40%。当R = 2时,与R = 1相比,性能反而降低了0.2%。原因可能是,这种重复提取特征的做法除了增加计算成本之外,并没有捕捉到有用的信息。因此,基于上述观察,我们选择R = 1。
TABLE IV RESULT COMPARISONS OF THE NUMBER OF REPETITIONS OF THE PROPOSED CFP IN THE YOLOX-L BASELINE. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT. R DENOTES THE NUMBER OF REPETITIONS.
表IV YOLOX-L基线中拟定CFP重复次数的结果比较。“-”表示没有这样的设置。“+”是我们重新实施的结果。R表示重复次数。
D. Efficiency Analysis
D.效率分析
In this section, we show the efficiency analysis. First, we analyze the performance of the MLP variants and attentionbased variants from a multi-metric perspective. In Figure 5, all models take YOLOX-L as baseline and are trained on the MS-COCO emphval set with the same data augmentation settings. Meanwhile, to demonstrate the effectiveness of the MLP structure, as shown in Table V, we compare it with the state-of-the-art transformer methods and the MLP methods at this stage. As can be observed from Figure 5, we can intuitively see that the MLP (Ours) structure is significantly better than the other structures in terms of mAP, and it is lower than the other structures in terms of number of parameters, computation volume, and the inference time. It can be shown that the MLP structure can guarantee a lower number of parameters and computation volume under the condition of obtaining a better precision.在本节中,我们展示了效率分析。首先,我们从多度量的角度分析了MLP变体和基于注意力的变体的性能。在图5中,所有模型都将YOLOX-L作为基线,并在具有相同数据增强设置的MS-COCO emphval集上进行训练。同时,为了证明MLP结构的有效性,如表V所示,我们将其与最先进的Transformer方法和现阶段的MLP方法进行了比较。从图5可以看出,我们可以直观地看到,MLP(Ours)结构在mAP方面明显优于其他结构,并且在参数数量、计算量和推理时间方面低于其他结构。结果表明,MLP结构在保证较高精度的前提下,可以保证较少的参数个数和计算量。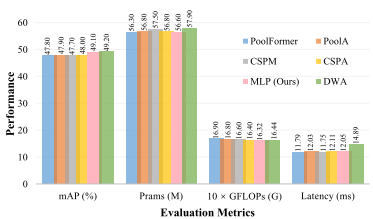
Fig. 5. Multi-metrics comparison results between MLP variants and attentionbased variants based on the MS-COCO val set.
图五 基于MS-COCO瓦尔集的MLP变体和基于注意力的变体之间的多度量比较结果。
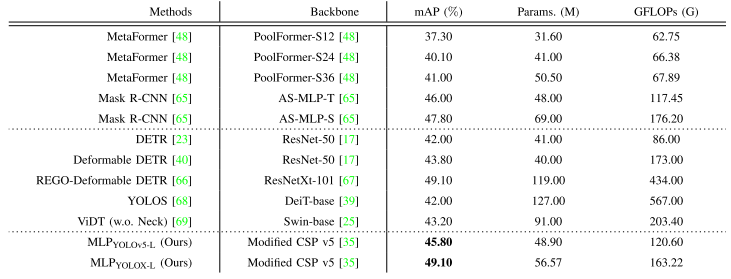
TABLE V RESULT COMPARISONS OF OUR LIGHTWEIGHT MLP WITH TRANSFORMER VARIANTS AND MLP VARIANT METHODS. MODEL EFFICIENCY ANALYSIS. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表V我们的轻量级MLP与Transformer变体和MLP变体方法的结果比较。模型效率分析“-”表示没有这样的设置。“+”是我们重新实施的结果。
In Table V, we give the comparative results of the MLP and transformer methods that are outstanding performers in object detection tasks at this stage. IN the first half of Table V, our MLPYOLOX-L method not only occupies less memory but also has an average precision of 1.3% higher compared to Mask R-CNN (backbone as AS-MLP-S [65]). In the middle part of Table V, we can find that our MLPYOLOX-L can improve the mAP by up to 7.1% compared to the transformer method (DETR [23]) without extra computational cost. With the same mAP, the number of parameters of MLP is reduced by 62.43M compared to REGO-Deformable DETR [66]. Therefore, we can find that MLP not only has high precision but also takes up less memory compared to the transformer methods. All in all, our MLP has outstanding performance in capturing feature long-range dependencies.在表V中,我们给予MLP和Transformer方法的比较结果,这两种方法在此阶段的目标检测任务中表现出色。在表V的前半部分,我们的MLPYOLOX-L方法不仅占用更少的内存,而且与Mask R-CNN(主干为AS-MLP-S [65])相比,平均精度高出1.3%。在表V的中间部分,我们可以发现,与Transformer方法(DETR [23])相比,我们的MLPYOLOX-L可以将mAP提高7.1%,而无需额外的计算成本。使用相同的mAP,与REGO可变形DETR [66]相比,MLP的参数数量减少了62.43M。因此,我们可以发现,MLP不仅具有较高的精度,而且还占用较少的内存相比,Transformer方法。总而言之,我们的MLP在捕获功能长期依赖性方面具有出色的性能。
TABLE V RESULT COMPARISONS OF OUR LIGHTWEIGHT MLP WITH TRANSFORMER VARIANTS AND MLP VARIANT METHODS. MODEL EFFICIENCY ANALYSIS. “-” DENOTES THAT THERE IS NO SUCH A SETTING. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表V我们的轻量级MLP与Transformer变体和MLP变体方法的结果比较。模型效率分析“-”表示没有这样的设置。“+”是我们重新实施的结果。
E. Comparisons with State-of-the-art Methods.
E.与最先进方法的比较。
As shown in Table VI, we validate the proposed CFP method on the MS-COCO val set with YOLOv5 (Small, Media and Large) and YOLOX (Small, Media and Large) as baselines. In addition, the data in table VII show the comparison results of our CFP method compared to the advanced singlestage and two-stage detectors. Finally, we show some visual comparison plots in Figure 6.如表VI所示,我们以YOLOv 5(小、中、大)和YOLOX(小、中、大)作为基线,在MS-COCO值集上验证了所提出的CFP方法。此外,表VII中的数据显示了我们的CFP方法与先进的单级和两级检测器的比较结果。最后,我们在图6中显示了一些视觉比较图。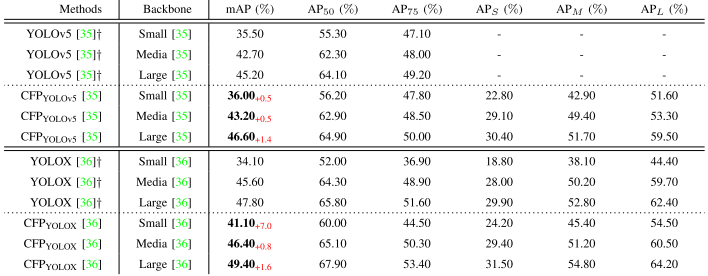
TABLE VI RESULT COMPARISONS WITH YOLOV5 AND YOLOX BASELINES. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表VI与YOLOV 5和YOLOX基线的结果比较。“+”是我们重新实施的结果。

Fig. 6. Qualitative results on the test set of MS-COCO 2017 [34]. We show the results of object detection from baseline and our approaches for comparison.
见图6。MS-COCO 2017测试集的定性结果[34]。我们展示了从基线和我们的方法进行比较的对象检测的结果。
Comparison with YOLOv5 and YOLOX baseline.与YOLOv5和YOLOX基线比较。
As shown in Table VI, when YOLOv5 is chosen as the baseline, the mAP of our CFP method is enhanced by 0.5%, 0.5%, and 1.4% on the Small, Media, and Large size models, respectively. When YOLOX [36] is used as the baseline, the mAP improves by 7.0%, 0.8%, and 1.6% on the backbone networks of different sizes. It is worth noting that the main reason why we choose YOLOv5 (anchor mechanism) and YOLOX (anchor-free mechanism) as the baseline is that the reciprocity of these two models in terms of network structure can fully demonstrate the effectiveness of our CPF approach. Most importantly, our CFP method do not perform poorly due to the shortcomings of the YOLOv5 model, which achieve a maximum mAP of 46.60%. Meanwhile, our mAP reaches 49.40% at YOLOX baseline. Moreover, CFPYOLOX on the small backbone network is improved by 7.0% over YOLOX [36]. The main reason for this is that the LVC in our CFP can enhance the feature representations of the local corner regions through visual centers at the pixel-level.如表VI所示,当选择YOLOv5作为基线时,我们的CFP方法的mAP在小、中和大尺寸模型上分别增强0.5%、0.5%和1.4%。当使用YOLOX [36]作为基线时,mAP在不同规模的骨干网络上提高了7.0%,0.8%和1.6%。值得注意的是,我们选择YOLOv5(锚机制)和YOLOX(无锚机制)作为基线的主要原因是,这两种模型在网络结构上的互惠性,能够充分证明我们的CPF方法的有效性。最重要的是,我们的CFP方法不会因为YOLOv5模型的缺点而表现不佳,它实现了46.60%的最大mAP。同时,我们的mAP在YOLOX基线时达到49.40%。此外,小型骨干网络上的CFPYOLOX比YOLOX提高了7.0%[36]。其主要原因是,在我们的CFP中的LVC可以通过像素级的视觉中心来增强局部角区域的特征表示。
TABLE VI RESULT COMPARISONS WITH YOLOV5 AND YOLOX BASELINES. ”+” IS OUR RE-IMPLEMENTATION RESULT.
表VI与YOLOV 5和YOLOX基线的结果比较。“+”是我们重新实施的结果。
Result comparisons on speed and accuracy.速度和准确度的结果比较。
We perform a series of comparisons on the MS-COCO val set with singlestage as well as two-stage detectors, and the results are shown in Table VII. We can first see the two-stage object detection models, including the Faster R-CNN series with different backbone networks, Mask R-CNN, and D2Det. Our $CFP_{YOLOX-L}$ model has significant advantages in terms of precision, as well as inference speed and time. Immediately after, we divide the single-stage detection methods into three parts in chronological order and then analyze them. There is no doubt that the proposed $CFP_{YOLOX-L}$ method improves the mAP by up to 27.80% compared to YOLOv3-ultralytics and its previous detectors. With nearly the same average precision, the CFPYOLOv5-M inferred 1.5 times faster compared to the EfficientDet-D2 detector. And comparing $CFP_{YOLOX-L}$ with EfficientDet-D3, not only the average accuracy is improved by 1.9%, but also the inference speed is 1.8 times higher. In addition, in the comparison with YOLOv4 series, it can be found that the mAP of CFPYOLOv5-L is improved by 2.7% compared to YOLOv4-CSP. Besides, we can see all scaled YOLOv5 models, including YOLOv5-S, YOLOv5-M, and YOLOv5-L. The average precision of its best YOLOv5-L model is 1.4% lower than the CFPYOLOv5-L. In the same way, our CFP method obtains a maximum average accuracy of no doubt that the proposed $CFP_{YOLOX-L}$ method improves the mAP by up to 27.80% compared to YOLOv3-ultralytics and its previous detectors. With nearly the same average precision, the CFPYOLOv5-M inferred 1.5 times faster compared to the EfficientDet-D2 detector. And comparing $CFP_{YOLOX-L}$ with EfficientDet-D3, not only the average accuracy is improved by 1.9%, but also the inference speed is 1.8 times higher. In addition, in the comparison with YOLOv4 series, it can be found that the mAP of CFPYOLOv5-L is improved by 2.7% compared to YOLOv4-CSP. Besides, we can see all scaled YOLOv5 models, including YOLOv5-S, YOLOv5-M, and YOLOv5-L. The average precision of its best YOLOv5-L model is 1.4% lower than the CFPYOLOv5-L. In the same way, our CFP method obtains a maximum average accuracy of 49.40%, which is 1.6% higher than YOLOX-L.我们对MS-COCO瓦尔装置与单级和两级检测器进行了一系列比较,结果如表VII所示。我们首先可以看到两阶段对象检测模型,包括具有不同骨干网络的Faster R-CNN系列,Mask R-CNN和D2 Det。我们的$CFP_{YOLOX-L}$模型在精度、推理速度和时间方面具有显著优势。紧接着,我们将单阶段检测方法按时间顺序分为三个部分进行分析。毫无疑问,与YOLOv 3-ultralytics及其以前的检测器相比,提出的$CFP_{YOLOX-L}$方法将mAP提高了27.80%。在几乎相同的平均精度下,CFPYLOv 5-M的推断速度是EfficientDet-D2检测器的1.5倍。与EfficientDet-D3相比,$CFP_{YOLOX-L}$不仅平均准确率提高了1.9%,而且推理速度提高了1.8倍。此外,在与YOLOv 4系列的比较中,可以发现CFPYLOv 5-L的mAP相比YOLOv 4-CSP提高了2.7%。此外,我们还可以看到所有比例的YOLOv 5模型,包括YOLOv 5-S,YOLOv 5-M和YOLOv 5-L。其最佳YOLOv 5-L模型的平均精度比CFPYLOv 5-L低1.4%。以同样的方式,我们的CFP方法获得了最大的平均精度,毫无疑问,与YOLOv 3-ultralytics及其以前的检测器相比,所提出的$CFP_{YOLOX-L}$方法将mAP提高了27.80%。在几乎相同的平均精度下,CFPYLOv 5-M的推断速度是EfficientDet-D2检测器的1.5倍。与EfficientDet-D3相比,$CFP_{YOLOX-L}$不仅平均准确率提高了1.9%,而且推理速度提高了1.8倍。此外,在与YOLOv 4系列的比较中,可以发现CFPYLOv 5-L的mAP相比YOLOv 4-CSP提高了2.7%。此外,我们还可以看到所有比例的YOLOv 5模型,包括YOLOv 5-S,YOLOv 5-M和YOLOv 5-L。其最佳YOLOv 5-L模型的平均精度比CFPYLOv 5-L低1.4%。同样,我们的CFP方法获得了49.40%的最大平均准确度,比YOLOX-L高1.6%。
Qualitative Results on MS-COCO 2017 test set.MS-COCO 2017测试集的定性结果。
In addition, we also show in Figure 6 some visualization results of baseline (YOLOX-L), $EVC_{YOLOX-L}$ and $CFP_{YOLOX-L}$ on MS-COCOCO test set. It is worth noting that we use white, red and orange boxes to mark where the detection task failures respectively. White boxes indicate misses due to occlusion, light influence, or small object size. Red boxes indicate detection errors due to insufficient contextual semantic relationships, e.g., causing one object to be detected as two objects. The yellow boxes indicate an error in the object classification此外,我们还在图6中显示了MS-COCOCO测试集上基线(YOLOX-L)、$EVC_{YOLOX-L}$和$CFP_{YOLOX-L}$的一些可视化结果。值得注意的是,我们分别使用白色、红色和橙子框来标记检测任务失败的位置。白色框表示由于遮挡、光线影响或小对象尺寸而导致的未命中。红框表示由于上下文语义关系不足而导致的检测错误,例如,导致一个物体被检测为两个物体。黄色框表示对象分类中的错误
As can be seen in the first line of the figure, the detection result of YOLOX-L in the part marked in the white box is not ideal due to the distance factor of “zebra”. And the $EVC_{YOLOX-L}$ can partially detect the “zebra” at a distance. Therefore, it is intuitively proved that EVC is very effective for small object detection in some intensive detection tasks. In the second line of the figure, YOLOX-L does not fully detect the “Cups” in the cabinet due to factors such as occlusion and illumination. The $EVC_{YOLOX-L}$ model alleviates this problem by using MLP structures to capture the long-range dependencies of the features in the object. Finally, the $CFP_{YOLOX-L}$ model uses the GCR-assisted EVC scheme and gets better results. In the third line of the figure, the $CFP_{YOLOX-L}$ model performs better in complex scenarios. Based on the EVC scheme, GCR is used to adjust intra-layer features for top-downm, and $CFP_{YOLOX-L}$ can solve the problem of classification better.从图中第一行可以看出,由于“斑马”的距离因素,白色框中标注的部分YOLOX-L的检测结果并不理想。$EVC_{YOLOX-L}$可以在一定距离内部分检测到“斑马”。因此,直观地证明了EVC对于一些密集检测任务中的小目标检测非常有效。在图中的第二行,由于遮挡和光照等因素,YOLOX-L无法完全检测到橱柜中的“杯子”。$EVC_{YOLOX-L}$模型通过使用MLP结构来捕获对象中特征的长程依赖关系来解决这个问题。最后,$CFP_{YOLOX-L}$模型采用了GCR辅助的EVC方案,得到了较好的结果。在图的第三行,$CFP_{YOLOX-L}$模型在复杂场景中表现更好。在EVC算法的基础上,采用GCR自顶向下调整层内特征,CFPYOLOX-L算法能较好地解决分类问题。
V. CONCLUSIONS AND FUTURE WORK
In this work, we proposed a CFP for object detection, which was based on a globally explicit centralized feature regulation. We first proposed a spatial explicit visual center scheme, where a lightweight MLP was used to capture the globally long-range dependencies and a parallel learnable visual center was used to capture the local corner regions of the input images. Based on the proposed EVC, we then proposed a GCR for a feature pyramid in a top-down manner, where the explicit visual center information obtained from the deepest intra-layer feature was used to regulate all frontal shallow features. Compared to the existing methods, CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an all-round yet discriminative feature representation. Experimental results on MS-COCO dataset verified that our CFP can achieve the consistent performance gains on the state-of-the-art object detection baselines. CFP is a generalized approach that can not only extract global longrange dependencies of the intra-layer features but also preserve the local corner regional information as much as possible, which is very important for dense prediction tasks. Therefore, in the future, we will start to develop some advanced intra layer feature regulate methods to further improve the feature representation ability. Besides, we will try to apply EVC and GCR to other feature pyramid-based computer vision tasks, e.g., semantic segmentation, object localization, instance segmentation and person re-identification.在这项工作中,我们提出了一个CFP的对象检测,这是基于一个全球显式的集中式特征调节。我们首先提出了一个空间显式视觉中心的计划,其中一个轻量级的MLP被用来捕捉全局的长程依赖和一个并行学习的视觉中心被用来捕捉输入图像的局部角区域。基于所提出的EVC,我们然后提出了一个GCR的特征金字塔在一个自顶向下的方式,其中从最深的层内特征获得的显式视觉中心信息被用来调节所有的正面浅功能。与现有的方法相比,CFP不仅具有捕获全局长距离依赖的能力,而且能够有效地获得全面而有区别的特征表示。在MS-COCO数据集上的实验结果表明,CFP算法在现有的目标检测基线上可以获得一致的性能增益。CFP是一种广义的方法,它不仅可以提取层内特征的全局长程依赖性,而且可以尽可能多地保留局部角点区域信息,这对于密集预测任务非常重要。因此,在未来,我们将开始开发一些先进的层内特征调节方法,以进一步提高特征表示能力。此外,我们将尝试将EVC和GCR应用于其他基于特征的计算机视觉任务,例如,语义分割、对象定位、实例分割和人物重新识别。
GPT解读
核心内容
这篇文章提出了一种名为Centralized Feature Pyramid (CFP)的新方法,用于目标检测任务。CFP的核心思想是基于全局显式的中心化特征调节,以提高目标检测的性能。文章的主要贡献和内容可以概括如下:
空间显式视觉中心方案:提出了一种轻量级的多层感知器(MLP)结构,用于捕捉全局长距离依赖性,以及一个并行可学习的视中心机制,用于捕捉输入图像的局部角区域。
全局中心化调节:在特征金字塔的顶层实施空间显式视觉中心,然后提出一种自上而下的全局中心化调节(GCR),使用从最深层特征获得的显式视觉中心信息来调节所有前面的浅层特征。
性能提升:在MS-COCO数据集上的实验结果表明,CFP在现有的YOLOv5和YOLOX目标检测基线上实现了一致的性能提升。
效率分析:文章还对MLP变体和基于注意力的变体进行了多指标的效率分析,证明了MLP结构在保持较低参数数量和计算量的同时,能够获得更好的精度。
与现有方法的比较:CFP不仅能够捕捉全局长距离依赖性,而且能够有效地获得全面且具有区分性的特征表示。与现有的特征金字塔方法相比,CFP在目标检测任务中表现出了优越性。
未来工作:作者计划开发更先进的层内特征调节方法来进一步提高特征表示能力,并尝试将EVC和GCR应用于其他基于特征金字塔的计算机视觉任务,如语义分割、目标定位、实例分割和行人重识别。
文章还详细描述了CFP的实现细节,包括网络架构、训练设置、实验结果以及与现有方法的比较。此外,还提供了代码的发布地址,以便其他研究者可以访问和使用CFP。
1. 前人研究的方法
根据这篇文章,前人在目标检测领域的研究方法主要包括以下几个方面:
特征金字塔:早期的方法如SSD和FPN通过构建特征金字塔来处理不同尺度的对象。这些方法通过在网络中使用不同大小的特征图来捕获多尺度信息,从而提高模型对各种尺寸对象的识别能力。
层间特征交互:FPN等方法通过自下而上的路径和横向连接来增强浅层特征与深层特征之间的交互,使得浅层特征能够获得全局上下文信息。
注意力机制:近年来,基于Transformer的方法通过多头自注意力机制来捕捉全局依赖性,这些方法将输入图像划分为多个patch,并通过patch之间的特征交互来获取全局信息。
非局部/自注意力机制:为了增强特征的局部交互,研究者引入了非局部操作和自注意力机制,如GCNet,这些方法通过捕获空间特征之间的长距离依赖来提高模型的性能。
网络架构搜索:NAS-FPN等方法利用神经架构搜索(NAS)来学习特征金字塔的结构,以获得可扩展的特征表示。
轻量级MLP结构:为了解决Transformer模型的计算复杂性问题,研究者开始探索使用轻量级的MLP结构来替代注意力模块,以捕获全局依赖性并保持模型的高效性。
端到端目标检测:一些研究如DETR和Deformable DETR采用了端到端的目标检测方法,这些方法通常基于Transformer架构,直接从图像到目标的边界框和类别标签进行预测。
特征金字塔与Transformer的结合:PVT和Swin Transformer等方法将特征金字塔与Transformer结合,以利用Transformer的全局依赖性捕捉能力。
这些研究方法为文章中提出的CFP方法提供了基础,CFP在这些方法的基础上进行了创新,通过引入显式的视觉中心方案和全局中心化调节来进一步提升目标检测的性能。
2. 作者要解决的问题
根据这篇文章,作者试图解决的主要问题是如何在目标检测任务中有效地捕捉全局长距离依赖性,同时保留局部角区域的信息,以提高模型在密集预测任务中的性能。具体来说,作者关注的问题包括:
层内特征调节的忽视:现有的目标检测方法主要关注层间特征交互,而忽略了层内特征调节的重要性。层内特征调节对于捕获图像的局部细节和角落区域的信息至关重要,这些信息对于精确的目标定位和分类是必要的。
全局长距离依赖性的捕捉:标准卷积神经网络(CNN)的接受域有限,这限制了模型捕捉全局信息的能力。虽然基于Transformer的方法能够通过自注意力机制捕获全局依赖性,但它们通常计算成本高昂,且可能忽略图像的角落区域。
计算效率与性能的平衡:Transformer模型虽然在视觉任务中表现出色,但其计算复杂度和参数数量较高。作者希望开发一种既能捕获全局信息又能保持计算效率的目标检测方法。
特征金字塔的改进:现有的特征金字塔方法在处理多尺度对象时存在局限性。作者提出了一种改进的特征金字塔结构,通过全局中心化特征调节来增强特征表示。
为了解决这些问题,作者提出了Centralized Feature Pyramid (CFP)方法,该方法包括:
- 空间显式视觉中心方案:使用轻量级MLP捕捉全局长距离依赖性,同时使用可学习的视中心机制来聚合输入图像的局部角区域特征。
- 全局中心化调节:在特征金字塔的顶层实施空间显式视觉中心,然后通过自上而下的方式调节所有前面的浅层特征。
- 性能提升:在MS-COCO数据集上的实验结果表明,CFP能够在保持计算效率的同时,提高目标检测的准确性。
总的来说,作者的目标是开发一种既能捕获全局信息又能保留局部细节的目标检测方法,同时保持模型的计算效率。通过CFP方法,作者在现有目标检测模型的基础上实现了性能的提升。
3.作者通过什么样的方法来解决所提出的研究问题
根据这篇文章,作者通过以下方法来解决所提出的研究问题:
提出空间显式视觉中心方案(EVC):作者提出了一个包含轻量级多层感知器(MLP)和可学习视觉中心机制的并行结构。这个方案旨在同时捕获全局长距离依赖性和局部角区域信息。轻量级MLP用于捕捉全局信息,而可学习的视觉中心机制则专注于输入图像的局部关键区域。
实现全局中心化调节(GCR):在特征金字塔的顶层实施空间显式视觉中心后,作者提出了一种自上而下的全局中心化调节方法。这种方法利用从最深层特征获得的显式视觉中心信息来调节所有前面的浅层特征,从而在保持计算效率的同时,增强了特征的全局和局部表示能力。
优化特征金字塔:作者对现有的特征金字塔结构进行了改进,通过引入EVC和GCR,使得特征金字塔能够更有效地捕获全局依赖性,同时保留局部特征信息。
实验验证:作者在MS-COCO数据集上进行了广泛的实验,以验证CFP方法的有效性。实验结果表明,CFP能够在现有的YOLOv5和YOLOX目标检测基线上实现一致的性能提升。
效率分析:为了确保所提出方法的计算效率,作者对MLP变体和基于注意力的变体进行了多指标的效率分析。分析结果表明,CFP方法在保持较高检测精度的同时,具有较低的参数数量和计算量。
未来工作:作者提出了未来研究的方向,包括开发更先进的层内特征调节方法,以及将EVC和GCR应用于其他计算机视觉任务,如语义分割、目标定位、实例分割和行人重识别。
通过这些方法,作者不仅解决了现有目标检测方法在全局依赖性和局部特征保留方面的局限性,还提高了模型的计算效率,为未来的目标检测研究提供了新的思路。
4.作者通过哪些实验得出来了这些结果
根据文章内容,作者通过以下实验来得出他们的研究结果:
基准模型的选择:作者选择了当时最先进的目标检测模型YOLOv5和YOLOX作为基准,以验证CFP方法的有效性。这些模型在目标检测领域具有代表性,能够提供一个强有力的性能比较基准。
数据集:实验在MS-COCO数据集上进行,这是一个广泛用于目标检测研究的标准数据集,包含多种类别的物体和复杂的场景。使用这个数据集可以确保实验结果的普遍性和可靠性。
性能指标:作者使用了多种评价指标来衡量模型性能,包括平均精度(AP)、AP50、AP75、APS、APM和APL。这些指标能够全面评估模型在不同尺度和难度下的表现。
消融实验:为了验证CFP中各个组件的贡献,作者进行了消融实验。这包括单独使用轻量级MLP、可学习视觉中心(LVC)以及全局中心化调节(GCR)等不同组合,以观察它们对模型性能的影响。
参数和计算效率分析:作者对模型的参数数量、计算量(GFLOPs)、帧率(FPS)、延迟等进行了分析,以评估CFP方法的计算效率。这些指标对于实际应用中的模型选择至关重要。
与现有方法的比较:作者将CFP方法与一系列现有的目标检测方法进行了比较,包括两阶段检测器(如Faster R-CNN)和单阶段检测器(如SSD和YOLO系列)。这种比较有助于展示CFP在当前研究领域中的地位。
定性结果分析:作者还提供了在MS-COCO测试集上的定性结果,通过可视化检测结果来展示CFP方法在处理遮挡、光照变化和小型物体等挑战时的优势。
通过这些实验,作者得出了CFP方法在目标检测任务中能够实现性能提升的结论,并且该方法在保持计算效率的同时,能够有效地捕获全局依赖性和局部特征信息。这些实验结果支持了作者提出的CFP方法的有效性和实用性。
5.实验部分的不足
文章中并未提供实验部分的详细不足,但根据常见的研究实践和实验设计原则,我们可以推测可能存在的一些潜在不足之处:
泛化能力的验证:实验主要在MS-COCO数据集上进行,虽然这是一个广泛使用的数据集,但模型的泛化能力在其他数据集上的表现未被验证。模型在不同领域、不同分布的数据集上的表现可能有所不同。
对比实验的广度:虽然与一些现有的目标检测方法进行了比较,但可能没有涵盖所有类型的最新方法,特别是那些与CFP方法在概念上相似或竞争的方法。
超参数调整:实验中可能对模型的超参数进行了调整以获得最佳性能,但文章中没有详细说明超参数选择的过程和理由,这可能会影响实验结果的可重复性。
计算资源的描述:实验可能没有详细描述使用的计算资源,如GPU型号、内存大小等,这些信息对于其他研究者复现实验结果非常重要。
训练和测试的一致性:实验中可能没有明确区分训练集和测试集的划分,或者在训练过程中可能使用了某些测试集的信息,这可能会影响模型性能评估的准确性。
模型鲁棒性测试:实验可能没有充分测试模型在面对极端情况(如噪声、遮挡、光照变化等)时的鲁棒性。
实时性能评估:对于实际应用,模型的实时性能(如FPS)非常重要,但实验可能没有在多样化的硬件配置上评估模型的实时性能。
代码和模型的开放性:虽然文章提到了代码的发布,但没有提及模型权重是否公开,这对于研究社区验证和进一步研究模型至关重要。
长期跟踪性能:对于目标检测任务,模型在长时间运行后的性能稳定性也是一个重要指标,但文章中可能没有提及这方面的测试。
多任务学习性能:文章主要关注目标检测任务,但没有提及模型在多任务学习设置下的性能,例如同时进行目标检测和语义分割。
这些潜在的不足之处可能会影响对CFP方法全面性能的理解。在后续的研究中,作者可以考虑这些方面来进一步完善实验设计和结果的解释。
6.作者使用该方法的优点
根据文章内容,作者提出的Centralized Feature Pyramid (CFP)方法具有以下优点:
全局与局部特征的结合:CFP通过轻量级MLP捕捉全局长距离依赖性,同时使用可学习的视中心机制来聚合局部角区域特征。这种结合使得模型能够同时关注全局上下文和局部细节,提高了目标检测的准确性。
计算效率:与传统的基于Transformer的方法相比,CFP方法使用轻量级MLP结构,减少了模型的计算复杂度,使得模型在保持高效性的同时能够捕获全局依赖性。
性能提升:在MS-COCO数据集上的实验结果表明,CFP能够在现有的YOLOv5和YOLOX目标检测基线上实现一致的性能提升,证明了其在实际应用中的有效性。
通用性:CFP方法不仅适用于目标检测任务,作者还提出了将其应用于其他计算机视觉任务的可能性,如语义分割、目标定位、实例分割和行人重识别,显示了其通用性。
简化的网络结构:CFP方法避免了复杂的注意力机制,采用了更为直接和简单的MLP结构,这有助于简化网络设计,降低模型的复杂性。
可扩展性:CFP方法可以与现有的目标检测模型相结合,通过引入新的模块来提升性能,这种可扩展性使得CFP可以轻松集成到不同的网络架构中。
代码开源:作者提供了CFP方法的代码,这有助于研究者和开发者复现实验结果,进一步研究和改进CFP方法。
多尺度特征融合:CFP方法通过特征金字塔结构,有效地融合了不同尺度的特征信息,这对于处理不同大小和形状的目标至关重要。
端到端训练:CFP方法支持端到端训练,这简化了训练流程,使得模型训练更加高效。
这些优点表明,CFP方法在目标检测领域提供了一种有效的特征提取和表示策略,能够在保持计算效率的同时提高模型性能。
7.作者使用该方法的缺点
尽管文章中提出的Centralized Feature Pyramid (CFP)方法具有多项优点,但也可能存在一些潜在的缺点或局限性,这些可能包括:
泛化能力的验证:文章中主要在MS-COCO数据集上验证了CFP方法的有效性,但没有提及在其他数据集或不同领域上的表现。这可能限制了对其泛化能力的全面评估。
复杂场景的挑战:虽然CFP在MS-COCO上表现良好,但在处理极端光照、遮挡、快速运动等复杂场景时的性能尚未得到充分验证。
实时性能:尽管CFP旨在提高计算效率,但其在实际硬件上的实时性能(如FPS)可能受到限制,特别是在资源受限的设备上。
模型大小和参数量:虽然CFP方法相对于基于Transformer的方法更为轻量级,但其模型大小和参数量可能仍然较大,这可能影响模型的部署和应用。
超参数调整:CFP方法可能需要仔细调整超参数以获得最佳性能,这可能需要大量的实验和计算资源。
计算资源消耗:尽管CFP方法相对于某些方法更为高效,但其在训练和推理过程中可能仍然需要显著的计算资源。
模型解释性:CFP方法可能缺乏模型解释性,这在某些应用场景中(如医疗图像分析)可能是一个重要因素。
对小目标的检测:文章中提到CFP在小目标检测上有所改进,但没有详细说明其在极小目标或密集目标场景下的表现。
多任务学习性能:文章没有提及CFP在多任务学习设置下的性能,这可能是一个潜在的研究方向。
代码和模型的开放性:虽然代码已经发布,但如果没有提供预训练模型或详细的使用说明,可能会影响其他研究者和开发者的使用。
这些潜在的缺点或局限性可能需要在未来的研究中进一步探讨和解决,以提高CFP方法的实用性和适用性。
8. 论文的创新点主要体现在以下几个方面
根据文章内容,论文的创新点主要体现在以下几个方面:
空间显式视觉中心方案(EVC):提出了一种新的网络结构,使用轻量级MLP来捕捉全局长距离依赖性,同时引入了一个并行的可学习视觉中心机制来聚焦于输入图像的局部角区域。这种结构旨在同时捕获全局和局部特征,提高目标检测的准确性。
全局中心化调节(GCR):在特征金字塔的基础上,提出了一种自上而下的全局中心化调节方法。这种方法利用从最深层特征获得的显式视觉中心信息来调节前面所有浅层特征,从而提高特征的全局表示能力。
性能提升:在MS-COCO数据集上的实验结果表明,CFP方法能够在现有的YOLOv5和YOLOX目标检测基线上实现一致的性能提升,这验证了所提出方法的有效性。
计算效率:CFP方法在保持较高检测精度的同时,具有较低的参数数量和计算量,这使得模型在计算资源有限的环境下更加实用。
通用性和可扩展性:CFP方法不仅适用于目标检测任务,还有潜力被应用于其他计算机视觉任务,如语义分割、目标定位、实例分割和行人重识别,显示了其通用性和可扩展性。
这些创新点表明,作者在目标检测领域提出了一种新的有效方法,不仅提高了模型性能,还考虑了计算效率和模型的通用性,为未来的目标检测研究提供了新的方向。